H. Mössenböck
Johannes Kepler University Linz
Institute of Practical Computer Science
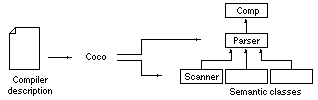
Coco/R is a compiler generator which takes a compiler description in the form of an LL(1) attributed grammar and generates the scanner and the parser of the described parser. This paper describes Coco/R for Java. There are also implementations of Coco/R for C and Modula-2 as well as for Oberon.
Coco/R takes an augmented EBNF grammar of a language and generates a recursive descent parser and a scanner for this language. The programmer has to supply a main class that calls the parser, as well as semantic classes that are used from within the grammar (e.g., a symbol table handler and a code generator).
The following example gives you a rough impression of the input language. It shows a grammar rule for the processing of declarations.
VarDeclaration <^int adr>
(. Object obj, obj1;
Struct typ;
int n, a;
String name; .)
= Ident <^name> (. obj = SymTab.Find(name);
obj.link = null;
n = 1; .)
{ ',' Ident <^name> (. obj1 = SymTab.Find(name);
obj1.link = obj;
obj = obj1;
n++; .)
}
':'
Type <^typ> (. adr = adr + n * typ.size;
a = adr;
while (obj != null) {
a =- typ.size;
obj.adr = a;
obj = obj.link;
} .)
';'.
The core of this specification is the EBNF rule
VarDeclaration = Ident {',' Ident} ':' Type ';'.
It is augmented by attributes and semantic actions. The attributes (e.g. <^name>) specify the parameters of the symbols. There are input attributes (e.g. <x, y>) and output attributes (e.g. <^z>). Output attributes are preceded by a "^". A grammar symbol may have at most one output attribute, which must be the first attribute in the attribute list (e.g. sym<^x, y, z>). The semantic actions are arbitrary Java statements between "(." and ".)". A semantic action is executed by the generated parser at its position in the grammar.
Coco/R generates a parser method for every grammar rule. The parser method of the above rule looks as follows:
private static int VarDeclaration () {
Object obj, obj1;
Struct typ;
int n, a;
String name;
name = Ident();
obj = SymTab.Find(name);
obj.link = null;
n = 1;
while (t.kind == ',') {
Get();
name = Ident();
obj1 = SymTab.Find(name);
obj1.link = obj;
obj = obj1;
n++;
}
Expect(':');
typ = Type();
adr = adr + n * typ.size;
a = adr;
while (obj != null) {
a =- typ.size;
obj.adr = a;
obj = obj.link;
}
Expect(';');
return adr;
}
Coco/R also generates a scanner that reads the input file and returns a stream of tokens to the parser.
A compiler description can be viewed as a class consisting of imports, declarations and grammar rules that describe the lexical and syntactical structure of a language as well as its translation into a target language. The vocabulary of Cocol/R uses identifiers, strings and numbers in the usual way:
ident = letter {letter | digit}.
string = '"' {anyButQuote} '"' | "'" {anyButApostrophe} "'".
number = digit {digit}.
Upper case letters are distinct from lower case letters. Strings must not cross line borders. Keywords are
ANY CASE CHARACTERS CHR COMMENTS COMPILER CONTEXT END FROM IGNORE NESTED PRAGMAS PRODUCTIONS SYNC TO TOKENS WEAK
The following metacharacters are used to form EBNF expressions:
|
( ) |
for grouping |
Comments are enclosed in "/*" and "*/" and may be nested.
A compiler description is made up of the following parts
Cocol =
"COMPILER" ident
ArbitraryJavaDeclarations
ScannerSpecification
ParserSpecification
"END" ident "." .
The name after the keyword COMPILER is the grammar name and must match the name after the keyword END. The grammar name also denotes the topmost nonterminal (the start symbol).
After the grammar name arbitrary Java declarations may follow that are not checked by Coco/R. They usually contain imports of other classes as well as declarations of fields and methods of the parser class to be generated. The fields and methods can be used in the semantic actions later on.
The remaining parts of the compiler description specify the lexical and syntactical structure of the language to be processed.
A scanner has to read source text, skip meaningless characters, and recognize tokens which have to be passed to the parser. Tokens may be classified as literals and token classes. Literals (e.g., "while", "=", etc.) are written as strings and denote themselves. They are introduced directly in the productions and do not have to be declared. Token classes (e.g., identifiers or numbers) have a certain structure that must be declared by a regular expression in EBNF. There are usually many different instances of a token class (e.g., many different identifiers) which are all recognized as the same token.
ScannerSpecification =
{ "CHARACTERS" {SetDecl}
| "TOKENS" {TokenDecl}
| "PRAGMAS" {PragmaDecl}
| CommentDecl
| VariousDecl
}.
A scanner specification consists of 5 optional parts that may be written in arbitrary order.
Character sets. This section allows the user to name character sets such as letters or digits. These names may be used in the other sections of the scanner specification.
SetDecl = ident "=" Set.
Set = BasicSet { ("+"|"-") BasicSet}.
BasicSet = ident | string | "CHR" "(" number ")" | "ANY".
SetDecl associates a name with a character set. Basic character sets are denoted as
|
string |
a set consisting of all characters in the string |
Character sets may be formed from basic sets by the operators
|
+ |
set union |
Examples
digit = "0123456789". /* the set of all digits */ hexdigit = digit + "ABCDEF". /* the set of all hexadecimal digits */ eol = CHR(13). /* the end-of-line character */ noDigit = ANY - digit. /* any character that is not a digit */
Tokens. A token is a terminal symbol for the parser but a syntactically structured symbol for the scanner. This structure has to be described by a regular expression in EBNF.
TokenDecl = Symbol ["=" TokenExpr "."].
TokenExpr = TokenTerm {"|" TokenTerm}.
TokenTerm = TokenFactor {TokenFactor} ["CONTEXT" "(" TokenExpr ")"].
TokenFactor = Symbol
| "(" TokenExpr ")" | "[" TokenExpr "]" | "{" TokenExpr "}".
Symbol = ident | string.
Tokens may be declared in any order. A token declaration defines a symbol together with its structure. Usually the symbol on the left-hand side of the declaration is an identifier. It is declared to stand for the structure described on the right-hand side of the declaration. (In special cases the symbol on the left-hand side may be a string, in which case a right-hand side must not be specified; see Section 4.)
The right-hand side of a token declaration specifies the structure of the token by a regular EBNF expression. This expression may contain literals denoting themselves (e.g., "==") and names of character sets (e.g., letter) denoting an arbitrary character from this set. It must not contain names of previously declared tokens. The CONTEXT phrase in a TokenTerm means that the term is only recognized when its context (i.e. the characters following in the input stream) matches the TokenExpr specified in brackets. Note that the context phrase is not part of the token.
If the right-hand side of a declaration is missing, no scanner is generated. This gives the programmer the chance to provide a hand-written scanner (see Section 4).
Examples
ident = letter {letter | digit}.
real = digit {digit} "." {digit} ["E" ["+"|"-"] digit {digit}].
number = digit {digit} | digit {digit} CONTEXT ("..").
The CONTEXT phrase in the above example allows the scanner to distinguish between reals (e.g., 1.23) and range constructs (e.g., 1..2) that could otherwise not be scanned with a single character lookahead. After reading a "1" and a ".", the scanner still works on both alternatives. If the next character is again a "." the ".." phrase is pushed back to the input stream and a number is returned to the parser. If the next character is not a ".", the scanner continues with the recognition of a real number.
Pragmas. A pragma is a token that may occur anywhere in the input stream (e.g., end-of-line symbols or compiler options). It would be too complicated to handle all their possible occurrences in the grammar. Therefore a special mechanism is provided to process pragmas without including them in the productions. Pragmas are declared like tokens, but they may have an associated semantic action that is executed whenever they are recognized by the scanner.
PragmaDecl = TokenDecl [SemAction]. SemAction = "(." ArbitraryJavaCode ".)".
Example
option = "$" {letter} . (. i := 1;
while (i < t.val.length()) {
if (t.val.charAt(i) == "A") ...;
else if (t.val.charAt(i) == "B") ...;
i++;
} .)
Note: The next token to be delivered to the parser is available in the field t of the generated parser (see also Section 3). It holds the token code (t.kind), the token value (t.val) and the token position (t.pos, t.line, t.col). Thus, t.val is the string of the recognized pragma.
Comments. Comments are difficult (nested comments are even impossible) to specify with regular expressions. This makes it necessary to have a special construct to express their structure. Comments are declared by specifying their opening and their closing brackets. It is possible to declare several kinds of comments. Comment brackets must not be longer than 2 characters.
CommentDecl = "COMMENTS" "FROM" TokenExpr "TO" TokenExpr ["NESTED"].
Examples
COMMENTS FROM "/*" TO "*/" NESTED COMMENTS FROM "//" TO eol
Various. The following clause specifies the set of meaningless characters that are to be skipped by the scanner (e.g., tabulators or eol). Blank is meaningless by default.
VariousDecl = "IGNORE" Set.
Example
IGNORE CHR(10) + CHR(13) + CHR(9)
The parser specification is the main part of the compiler description. It contains the productions of an attributed grammar specifying the syntax of the language to be recognized as well as its translation. The productions may be given in any order. References to yet undeclared nonterminals are allowed. Any name that is not declared as a terminal token is considered to be a nonterminal. There must be exactly one production for every nonterminal. There must be a production for the start symbol (the grammar name).
ParserSpecification = "PRODUCTIONS" {Production}.
Production = ident [FormalAttributes] [LocalDecl]
'=' Expression "." .
FormalAttributes = '<' ['^'] ArbitraryJavaParameterDeclarations '>'.
LocalDecl = "(." ArbitraryJavaDeclarations ".)".
Productions. A production is considered as a procedure that parses a nonterminal. It has its own scope for attributes and local names and is made up of a left-hand side and a right-hand side which are separated by an equal sign. The left-hand side specifies the name of the nonterminal together with its formal attributes and local declarations. The right-hand side consists of an EBNF expression that specifies the structure of the nonterminal as well as its translation.
Formal attributes are declared as ordinary Java parameters. Since grammar symbols may have output attributes, but Java does not have reference parameters, the first attribute in an attribute declaration is considered to be an output parameter if it is preceded by the character '^'. An output attribute is translated into a function return value. For example, the declaration
SomeSymbol <^int n, String name> = ... .
is translated into
private int SomeSymbol (String name) {
int n;
...
return n;
}
The local declarations are arbitrary Java declarations enclosed in "(." and ".)". A production constitutes a scope for its formal attributes and its locally declared names. Terminals and nonterminals, globally declared fields and methods as well as imported classes are visible in any production.
Expressions. An EBNF expression defines the structure of some part of the source language together with attributes and semantic actions that specify the translation of this part into the target language.
Expression = Term {'|' Term}.
Term = Factor {Factor}.
Factor = ["WEAK"] Symbol [Attributes]
| SemAction
| "ANY"
| "SYNC"
| '(' Expression ')'
| '[' Expression ']'
| '{' Expression '}'.
Attributes = '<' ['^'] ArbitraryJavaParameters '>'
| '<.' ['^'] ArbitraryJavaParameters '.>'.
SemAction = "(." ArbitraryJavaStatements ".)".
Symbol = ident | string.
Nonterminals may have attributes. They are written like actual parameters in Java and are enclosed in angle brackets. If the first attribute is preceded by a '^' it is considered an output attribute. Otherwise, attributes are input attributes. Formal and actual attributes must match according to the parameter compatibility rules of Java. The conformance, however, is only checked when the generated parser is compiled.
If the attributes contain the symbol ">" they must be enclosed in brackets of the form "<." and ".>", for example
<. ab .>
A semantic action is an arbitrary sequence of Java statements enclosed in "(." and ".)".
The symbol ANY denotes any terminal that is not an alternative of this ANY symbol. It can be used to conveniently parse structures that contain arbitrary text. For example, the translation of a Cocol/R attribute list looks as follows:
Attributes <^int len>
(. int pos; .)
=
'<' (. pos := token.pos + 1; .)
{ANY}
'>' (. len := token.pos - pos; .) .
In this example the closing angle bracket is an implicit alternative of the ANY symbol in curly brackets. The meaning is that ANY matches any terminal except '>'. token.pos is the source text position of the most recently recognized token (token is a field of the generated parser; see Section 3).
Syntax error handling. The programmer has to give some hints in order to allow Coco/R to generate good and efficient error handling. First, synchronization points have to be specified. A synchronization point is a location in the grammar where particularly safe tokens are expected that are hardly ever missing or mistyped. When the generated parser reaches such a point, it skips all input until a token occurs that is expected at this point.
In most languages good candidates for synchronization points are the beginning of a statement (where if, while, etc. are expected), or the beginning of a declaration sequence (where static, public, etc. are expected). The end-of-file symbol is always included into the synchronization symbols. This guarantees that synchronization terminates at least at the end of the source text. A synchronization point is specified by the symbol SYNC.
Error-handling can be further improved by specifying which terminals are "weak" in a certain context. A weak terminal is a symbol that is often mistyped or missing, such as the semicolon between statements. A weak terminal is denoted by preceding it with the keyword WEAK. When the parser expects a weak symbol but does not find it in the input stream, it adjusts the input to the next symbol that is either a legal successor of the weak symbol or a symbol expected at any synchronization point (symbols expected at synchronization points are considered to be particularly "strong", so that it makes sense that they are never skipped).
Example
StatementSeq = Statement {WEAK ";" Statement}.
Declaration = SYNC ("CONST" | "TYPE" | "VAR" | ...).
LL(1) requirements. Recursive descent parsing requires that the grammar of the parsed language satisfies the LL(1) property. This means that at any point in the grammar the parser must be able to decide on the basis of a single lookahead symbol which of several possible alternatives have to be selected. For example, the following production is not LL(1):
Statement = ident ':=' Expression
| ident ['(' ExpressionList ')'].
Both alternatives start with the symbol ident. When the parser comes to a statement and ident is the next input symbol, it cannot distinguish between these alternatives. However, the production can easily be transformed into
Statement = ident ( ":=" Expression | ['(' ExpressionList ')'] ).
where all alternatives start with distinct symbols. There are LL(1) conflicts that are not as easy to detect as in the above example. For a programmer, it can be hard to detect them in the grammar if he does not have a tool like Coco that checks the grammar automatically. Coco/R gives appropriate error messages that show how to correct any LL(1) conflicts.
In order to generate a compiler the user has to
Coco/R translates an attributed grammar into the following files:
These files are generated in the directory that holds the attributed grammar. All generated classes belong to a package, whose name is the name of the start symbol of the attributed grammar.
The scanner and the parser class are generated from pre-fabricated frame files
that have to be in the same directory as Coco/R.
When Coco/R is started it shows a file dialog from which the user can select the attributed grammar file. Error messages and warnings go to the standard output stream (System.out).
The generated scanner has the following interface:
class Scanner {
static ErrorStream err; // error messages
static void Init (String file, ErrorStream e);
static void Init (String file);
static Token Scan();
}
The actual scanner is the method Scan() which returns a token every time it is called by the parser. When the input is exhausted, it returns a special end-of-file token (with the token code 0) that is known to the parser. A token has the following structure:
class Token {
int kind; // token code
String val; // token value
int pos; // token position in the source text (starting at 0)
int line; // token line (starting at 1)
int col; // token column (starting at 0)
}
The scanner has to be initialized by calling the method Init passing it the name of the source file to be scanned. Optionally, one can also specify an error stream object to be used for error messages (see below). If no error stream object is specified, a default error stream is generated. The error stream object is installed in the field err of the scanner.
Error messages. Coco/R generates a class ErrorStream that is used for printing error messages to System.out. It has the following interface:
class ErrorStream {
int count; // number of reported errors
ErrorStream();
void ParsErr (int n, int line, int col);
void SemErr (int n, int line, int col);
void Exception (String s);
}
The parser calls the method ParsErr when it detects a syntax error. Coco/R generates this method such that it prints meaningful error messages. The method SemErr can be called by the programmer from the semantic actions of the attributed grammar when a semantic error is detected. The programmer has to provide an error code as well as position information (obtained from the scanner). For example, the call could look like
Scanner.err.SemErr(3, token.line, token.col);
The default implementation of SemErr just prints the error code and the position information. To get more meaningful error messages, the programmer can make a subclass of ErrorStream and override SemErr so that the error code is transformed into an error message. For example:
class MyErrorStream extends ErrorStream {
void SemErr (int n, int line, int col) {
super.SemErr(n, line, col);
switch (n) {
case 1: {System.out.println("... my msg 1 ..."); break;}
case 2: {System.out.println("... my msg 2 ..."); break;}
...
default: {System.out.println("error " + n); break;}
}
}
}
An object of such a subclass has to be passed to the Init method of the scanner.
The method Exception can be called by the programmer when a serious error occurs which makes any continuation obsolete. After printing the parameter s the compilation is aborted.
After parsing, the number of detected errors can be obtained from Scanner.err.count. If this field is 0 the compilation was successful.
The generated parser has the following interface:
class Parser {
static Token token; // last recognized token
static Token t; // lookahead token
static void Parse();
}
The parser is started by calling the method Parse(). This is done in the main class of the compiler (see below). Parse repeatedly calls the scanner to get tokens and executes semantic actions at the appropriate places.
The field token holds the most recently parsed token. The field t is the lookahead token that is already obtained from the scanner but not yet parsed. In a semantic action, token refers to the token immeadiately before the action, and t to the token immediately after the action.
The main class has to initialize the scanner, possibly create a custom error stream object, and call the parser. The following example shows a minimum implementation of the main class.
public class Comp {
public static void main (String[] args) {
String file = ... source file name ...;
Scanner.Init(file);
Parser.Parse();
System.out.println(Scanner.err.count + " errors detected");
System.exit(0);
}
}
If the user wants to provide meaningful semantic error messages he has to create a subclass of ErrorStream and override the SemErr method as in the following example:
class MyErrorStream extends ErrorStream {
void SemErr (int n, int line, int col) {
super.SemErr(n, line, col); // increment error counter and
// print position information
switch(n) {
case 0: System.out.println("..."); break;
case 1: System.out.println("..."); break;
default: System.out.println("error " + n + " line " + line
+ " column " + col);
}
}
}
An object of this class has to be passed to the Init method of the scanner:
Scanner.Init(file, new MyErrorStream());
Coco/R performs several tests to check if the grammar is well-formed. If one of the following error messages is produced, no compiler parts are generated.
The following messages are warnings. They may indicate an error but they may also describe desired effects. The generated compiler parts are valid. If an LL(1) error is reported for a construct X one must be aware that the generated parser will choose the first of several possible alternatives for X.
Coco/R can produce various output that can help to spot LL(1) errors or to understand the generated parts. Trace output can be switched on with the pragma
'$' {digit}
at the beginning of the attributed grammar. The output goes to the file listing. The effect of the switches is as follows:
|
0: |
prints the states of the scanner automaton |
Scanning is a time-consuming task. The scanner generated by Coco/R is optimized, but it is implemented as a deterministic finite automaton, which introduces some overhead. A manual implementation of the scanner can be slightly more efficient. For time-critical applications a programmer may want to generate a parser but provide a hand-written scanner. This can be done by declaring all terminal symbols (including literals) as tokens but without defining their structure by an EBNF expression, e.g.,
TOKENS
ident
number
"if"
...
If a named token is declared without structure, no scanner is generated. Tokens are assigned numbers in the order of their declaration; i.e., the first token gets the number 1, the second the number 2, etc. The number 0 is reserved for the end-of-file symbol. The hand-written scanner has to return token numbers according to this convention. It must have the interface described in Section 3.
Using a generator usually increases productivity but decreases flexibility. There are always special cases that can be handled more efficiently in a hand-written implementation. A good tool handles routine matters in a standard way but gives the user a chance to change the standard policy if he wants to. Coco/R generates the scanner and the parser from source texts (so-called frames) stored as the files Scanner.frame and Parser.frame. It does so by inserting grammar-specific parts into these frames. The programmer may edit the frames and may therefore change the internally used algorithms. For example, the user can implement a different buffering scheme for input characters.
The generated parser offers the lookahead token t that can be used to access the next token in the input stream (i.e. the one that is already scanned but not yet parsed). The following example shows how to compute the start and the end position of a statement sequence enclosed in curly brackets:
"{" (. start = t.pos; .) // start of the first ANY
{ANY}
(. end = token.pos; .) // end of the last ANY
"}"
Ideally, syntax analysis should be independent of semantic analysis (symbol table handling, type checking, etc.). Some languages like Ada and C, however, have constructs that can only be distinguished if one also considers semantic information, e.g., the type of the parsed symbols. In the language Oberon, for example, a designator is defined as
Designator = Qualident
{"." ident | "^" | "[" ExprList "]" | "(" Qualident ")" }.
where x(T) means a type guard (i.e., x is asserted to be of type T). A designator may be used in a statement
Statement = ... | Designator ["(" ExprList ")"] | ... .
Here x(T) can be interpreted as a designator x (a procedure name) and a parameter T. The two interpretations of x(T) can only be distinguished by looking at the type of x. If x is a procedure then the opening bracket is the start of a parameter list, otherwise the bracket belongs to a type guard.
Cocol/R allows control of the parser from within semantic actions to a certain degree. A designator, for example, can be processed in the following way:
Designator <^Item x> =
Qualident <^x>
{ (. if (...x is a procedure...) return; .)
"(" Qualident <^y> ")" (. ... process type guard ... .)
| ...
} .
When an opening bracket is seen after a Qualident, the alternative starting with an opening bracket is selected. The first semantic action of this alternative checks for the type of x. If x is a procedure, the parser returns from the production and continues in the Statement production.
This section shows how to use Coco/R for building a compiler for a tiny programming language called "Taste". Taste bears some similarities with Modula-2 or Oberon. It has variables of type INTEGER and BOOLEAN and non-recursive procedures without parameters. It allows assignments, procedure calls, IF- and WHILE-statements. Integers may be read from a file and written to the screen, each of them in a single line. It has arithmetic expressions (+,-,*,/) and relational expressions (=,<,>).
Here is an example of a Taste program:
MODULE Example;
VAR n: INTEGER;
PROCEDURE SumUp; (*build the sum of all integers from 1 to n*)
VAR sum: INTEGER;
BEGIN
sum:=0;
WHILE n0 DO sum:=sum+n; n:=n-1 END;
WRITE sum
END SumUp;
BEGIN
READ n;
WHILE n0 DO SumUp; READ n END
END Example.
The full grammar of Taste can be found here. Of course Taste is too restrictive to be used as a real programming language. Its purpose is just to give you a taste of how to write a compiler with Coco/R.
The Taste compiler is a compile-and-go compiler, which means that it reads a source program and translates it into a target program which is executed (i.e. interpreted) immediately after the compilation. When you run Taste, a dialog pops up which asks you for the name of the source file to be compiled. The file Test.TAS holds the sample program shown above, so select Test.TAS. This file is then compiled and immediately executed. Now, a second dialog box pops up, which asks you for the name of a data input file. You could use Test.IN as a sample input file. The output is printed to the screen.
Figure 2 shows the classes of the compiler (an arrow from A to B means that class A is used by class B).
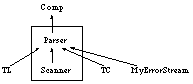
Fig.2 classes of the Taste compiler
The classes in the rectangle are generated by Coco/R, the others are written by hand. The classes have the following responsibilities:
|
Main class. It asks the user for the name of the source file and calls the parser and the interpreter. |
|
|
Recursive descent parser generated from the attributed grammar Taste.ATG. The parser contains the semantic actions from the attributed grammar. They are called and executed during parsing and do the actual compilation work. |
|
|
Scanner generated from Taste.ATG. |
|
|
Prints parser error messages. |
|
|
Symbol table with methods to handle scopes and to store and retrieve object information. |
|
|
Code generator with methods to emit instructions. It also contains the interpreter and its data structures. |
You can download all these classes together from here.
We define an abstract stack machine for the interpretation of Taste programs. The compiler translates a source program into instructions of that machine. The insructions are interpreted later on. The machine uses the following data structures (code and data are filled by the compiler):
char code[]; code memory int stack[]; stack with frames for local variables int top; stack pointer (points to next free stack element) int pc; program counter int base; base address of current frame
The instructions have variable length and are described by the following table (the initial values of the registers are: base=0; top=3;):
LOAD l,a Load value Push(stack[Frame(l)+a]);
LIT i Load literal Push(i);
STO l,a Store stack[Frame(l)+a]=Pop();
ADD Add j=Pop(); i=Pop(); Push(i+j);
SUB Subtract j=Pop(); i=Pop(); Push(i-j);
DIV Divide j=Pop(); i=Pop(); Push(i/j);
MUL Multiply j=Pop(); i=Pop(); Push(i*j);
EQU Compare if equal j=Pop(); i=Pop(); if (i==j) Push(1); else Push(0);
LSS Compare if less j=Pop(); i=Pop(); if (i<j) Push(1); else Push(0);
GTR Compare if greater j=Pop(); i=Pop(); if (i>j) Push(1); else Push(0);
CALL l,a Call procedure slink=Frame(l); Push(slink); Push(base); Push(pc+2);
pc=a; base=top-3;
RET Return from proc. top=base+3; pc=Pop(); base=Pop(); dummy=Pop();
RES i Reserve frame space top=top+i;
JMP a Jump pc=a;
FJMP a False jump if (Pop()==1) pc=adr;
HALT End of the program Halt;
NEG Negation Push(-Pop());
READ l,a Read integer stack[Frame(l)+a]=Read();
WRITE Write integer Writeln(Pop());
The function Frame(l) returns the base address of the stack frame which is (statically) l levels up in the stack. l=0 means the current frame, l=1 means the statically surrounding frame, etc. The main program is also considered as a procedure with a stack frame. Figure 3 shows the format of a stack frame.
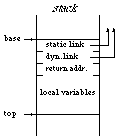
Fig.3 Format of a stack frame
For example, the source code instruction
i := i + 1
is translated into the code
LOAD 0,3 load value of i (at address 3 in current frame) LIT 1 load constant 1 ADD STO 0,3 store result to i
If you want to build a compiler for a source language of your own, proceed as follows:
We used Coco for various tasks (not only for writing compilers). The following list should give you some ideas about useful applications:
Here are the sources of Coco/R for Java.
|
The attributed grammar. Describes the processing of a compiler description. |
|
|
Main class. Initializes the scanner and calls the parser. This file also contains the custom error message class Errors. |
|
|
Scanner generated from Coco.ATG. |
|
|
Parser generated from Coco.ATG. |
|
|
A class for printing parser error messages. |
|
|
Symbol table of Coco. Stores information about terminals and nonterminals. |
|
|
This class builds the scanner automaton and generates the scanner source file. |
|
|
This class builts a syntax graph of the grammar rules and generates the parser source file from it. |
|
|
An auxiliary class with operations for sets. |
|
|
An auxiliary class to produce trace output. |
|
|
This is a frame file from which the scanner is generated. Coco/R inserts compiler-specific parts into this frame file. |
|
|
This is a frame file from which the parser is generated. Coco/R inserts compiler-specific parts into this frame file. |
If you rather would like to download a ZIP file with all class files of Coco, you can get it from here. (Note from JBergin. The version we use in the Pace Compiler Course is not exactly the one distributed by the original author. For the course, use the one distributed with the course tools.)
Caution:Some of the Coco source files contain multiple classes. This can be a problem for some Java compilers (e.g. JDK 1.1.5), which expect every class to be in a separate file. If your compiler produces error messages, you can either put every class into a separate file or simply compile Coco twice. The second compilation will usually succeed, because the compiler builds up dependency information during the first compilation.
Coco.Report.ps.Z
The original report on Coco/R including an implementation description.
Coco.Paper.ps.Z
H.Mössenböck: A Generator for Production Quality Compilers. Lecture Notes in Computer Science 477, Springer-Verlag, 1990.
Compiler book using Coco/R
P.Terry: Compilers and Compiler Generators - An Introduction Using C++. International Thomson Computer Press, 1997
This book uses the C++ version of Coco/R.