csis.pace.edu/~bergin
berginf@pace.edu
The design patterns community uses patterns and pattern languages as a means of communicating detailed problem solving knowledge from an expert in one domain to those who might benefit from the knowledge in another domain. To some extent, a pattern is an attempt to establish "best practice" with respect to a problem or class of problems.
One way to think about patterns is to think about the medieval apprentice system. A young person would apprentice to a master who would try to transmit the knowledge of the trade to the novice. The novice would begin by doing relatively simple and straight forward work, but would also often examine the more complex and intricate work of the master. The master would transmit knowledge by showing the novice how a certain thing could be done in the context of solving a certain kind of problem. For example, if the trade were stone carving, the novice would start out with simple patterns, probably marked by the master. The results most likely were fairly blocky with heavy bases. As the novice progressed, more advanced work could be undertaken. Some work was always challenging, even for masters, such as a rider upon a horse, due to the thinness of the legs of horses relative to the strength of stone. Over time, solutions to complex problems were found and refined by masters, who would then transmit the knowledge to novices.
In the educational setting, patterns provide a way for a master (the professor) to show a novice how to solve problems in context. Pattern languages are a formal mechanism for presenting patterns and thus transferring the knowledge. A comprehensive collection of patterns can be compared to an auto repair manual for a 1961 Volkswagen Beetle: solutions to problems in context.
Richard Pattis' book Karel the Robot (Wiley, 1981) was written at a time before the pattern movement began. Nevertheless, the author seems to have been thinking in terms of patterns in many parts of the book. His Stepwise Refinement discussions are one example. Even simpler is his discussion of nested if statements and the transformations that can be done on them. This gives the novice programmer an excellent framework for thinking about if statements as well as the specific topic: nested ifs. In the second edition (1995), Jim Roberts and mark Stehlik carried this a bit farther with their decision map. I tried to carry on in my extensions to Karel the Robot, that resulted in Karel++ (1997).
I think we need to start a conversation about extremely simple design patterns and pattern languages that can be used by novices in learning programming. The purpose is to get educators thinking about these simple patters and how the information we transmit to students can be framed as design patterns. This will have two important benefits. First, it will get educators to formalize what they do, as patterns provide a framework for presentation, discussion, and refinement. Second, students will become familiar with patterns and will be introduced to an important information transfer mechanism. Ideally, students can begin to look at patterns in CS1. They need to look at this information anyway. Patterns simply gives a way to present the information in a regularized format.
There are actually two movements going on, with different goals. One involves the Design Pattern community who have held annual conferences (PLoP Pattern Languages of Programming) conferences sponsored by the ACM. There is a web site (http://hillside.net/patterns/patterns.html) devoted to this work. You can find a nice FAQ there as well as a bibliography and several patterns and pattern languages. The second community is involved in Pedagogical Patterns. The emphasis here is on patterns of instruction. The web site for this is http://www.cs.unca.edu/~manns/oopsla.html. this site contains several contributed patterns. This information will be collected into a book.
What is being proposed here has elements of both existing movements. The Design Patterns community contributes "what to teach" and the Pedagogical Patterns Community speaks to "how to teach it." Both are vital, of course.
If we are to transmit knowledge systematically, it helps to have a common expression framework. Once a student is familiar with the framework, they can more quickly and easily absorb the content. The pattern syntax I suggest we start with is very simple. I've selected sixteen elements by scavenging from the book Pattern Languages of Program Design 3, edited by Martin, Riehle, and Buschmann (Addison-Wesley, 1998). I'm not sure that these are the right elements, and some of them clearly overlap with others. To express a pattern in this pattern syntax you just fill in the sixteen elements. Feel free to omit an element if it is not applicable, but you might be better entering TBA (To be announced) rather than omitting an element. You can also reorder the elements as appropriate or supplement this list with other elements. Doing so might eventually cause the pattern syntax itself to evolve.
In any case, here are the sixteen initial elements of the syntactical form with a very brief explanation of each. This is a particularly simple kind of syntax, by the way. Basically you just fill in the blanks under the various titles to get a pattern.
Every pattern should have a name. The name also includes a version number. Patterns evolve.
Who wrote the pattern?
What does the pattern do?
What other names is this pattern known by?
What problem or class of problems is this pattern trying to solve?
Why do we want this pattern?
When would we expect to see this pattern?
A concrete example (code) of the pattern in action.
What constructs are necessary for implementing this pattern?
How do the parts fit together?
What can be changed and still consider this to fit the same pattern?
When would you try to apply this pattern?
What outcomes will occur if this pattern is used?
Some examples of how the pattern has been applied in the past.
Names of some other patterns that are similar to this one or are needed by this one.
Where can the learner get more information about this pattern and its context?
There are two ways that such a pattern structure could be used. First, a pattern could be created from it intended for use by students learning a particular skill. But the same syntax could be used in a different way to transfer teaching techniques between educators. It is necessary to think about who the audience is when writing a pattern. In what follows, I'm not sure that I did a particularly good job of making this distinction. It needs refinement. That is why all patterns have version numbers.
Also, the "author" tag shouldn't be taken too literally. Patterns are not about something new that was created by a certain person. Patterns are about common practice. All the author has done is abstract the practice into a form that permits its analysis and refinement. Also, ideally, once a pattern is submitted by an author, it is analyzed and refined by others. Pattern writing is really a team effort. The author is really just the person who proposes a pattern. This requires more humility than we (professors) often show. In pattern workshops, one technique for analysis of a pattern is to have the author present but not allowed to participate in the discussion of his or her pattern.
If our patterns were intended for more advanced audiences, it would be important to include two additional sections.
What are the forces, constraints, social and ethical consderations,...that lead to this pattern?
How does this pattern find equilibrium between the forces?
In other words, "why is this pattern 'best practice' in this context?" The patterns community considers this to be the essential part of a pattern. I left this out of the syntax as these are intended for novices, but some of this material is discussed in notes in the patterns that I've included here. Maybe they should be included even for novices.
Now that we have a simple pattern syntax, we can try to express some simple design problems in it. I've chosen some here that are simple, but not all equally simple. All can be used in a CS1 course at various points. They are not intended to be profound, but simply to illustrate the possibilities. They are also probably incomplete, but note that most patterns should be expressible in from a few paragraphs to a few pages. Fifteen pages seems to be a common length for the complex patterns in the PLoD3 book mentioned above. Some patterns for novices should be shorter, but not necessarily all, since a novice might need more explanation when the pattern is subtle or has a few parts.
There is a joke in the pattern community that someday someone will try to submit the Linked List Pattern to a PLoP conference. I won't do that, but I do present that pattern here. After all, patterns ain't just for the big kids.
I've assigned all of these patterns version number 1.0. Perhaps that is overstating their level of development. Maybe 0.3beta would be better.
index: value:
0 10
1 25
2 31
3 42
Suppose that we have an array with four elements as above and we wish to display that data along with the index at which we can find each value. The following C++ fragment will achieve this.
for(int i = 0; i < 4; ++i)
{ int value = A[i];
cout << " " << i << " " << value << endl;
}
In the example above, the three parts were made explicit. The first line controls the loop. The second is the data generator (for the array values at least) and the third is the output statement.
In programming we often have independent choices to make with different processing needed for each of the combinations of choices.
if(x > = 0)
{ if(y >= 0)
{ System.out.println("First");
}
else
{ System.out.println("Second");
}
}
else
{ if(y >= 0)
{ System.out.println("Third");
}
else
{ System.out.println("Fourth");
}
}
However, if we reverse the inner and outer structures we must proceed differently.
if(y > = 0)
{ if(x >= 0)
{ System.out.println("First");
}
else
{ System.out.println("Third");
}
}
else
{ if(x >= 0)
{ System.out.println("Second");
}
else
{ System.out.println("Fourth");
}
}
Another variation is when you have more than two independent choices. In this case the number of possibilities expands by powers of two. More than three independent choices (eight possibilities) leads to code which is difficult to read and understand, however, so the use of this pattern for large number of independent choices is discouraged.
If the two decision criteria are truly independent, then the if statements should nest in either order. However it may be that partial dependencies may require that one nesting structure is much better than another.
// Independent choice pattern, two choices.
if(... outer test ... )
{ if(... inner test ... )
{ ... both true
}
else
{ ... only the first true
}
}
else
{ if(... inner test ... )
{ ... only the second true
}
else
{ ... neither true
}
}
Pattis, Roberts, Stehlik, Karel the Robot, 2ed. Chapter 4, Wiley, 1995
Since a variable can refer to different objects at different times, the client may not know explicitly which server it is corresponding with since it uses a variable to get access. In an object-oriented system, with polymorphic types, it is not even clear what specific type (class) the server belongs to. Therefore the client does not, in fact, specify which code is to be executed, but only which service is desired.
For this to work two things are required, one structural, and the other logical. First, structurally, all of the possible services must provide the same service interface so that clients may correspond with them. This is usually achieved by having all servers derive from a common base class or all implement a common interface.
Secondly, and more important to the correctness of the program, the fulfillment of the service must be predictable from the clients viewpoint. Each server, no matter what its class, must "do the right thing" to fulfill the service request on behalf of the client in the way that would not be unexpected. Different servers in different classes provides a way to achieve different implementations and a variety of services, but not chaos.
For example, in the real world, when you go to a bank to cash a check, you don't know (or care) what specific procedures the bank uses behind the counter to fulfill the request as long as the results are accurate from an accounting standpoint. In fact, different banks use different procedures, but from the client standpoint they all "seem" the same.
A client within the scope of a server requests service by naming the server and one of its services. Additional information is passed as parameters in the service request. The client usually waits for the service to be performed.
The server receives the request and the parameters and carries out some processing on behalf of the client. The server then returns any generated results to the client.
The client receives the results and continues.
Note that the server may require help in fulfilling a client request and may itself act as client with respect to another object that acts as server to help carry out the original request. This can proceed recursively, but each request finally returns and the object making the request resumes.
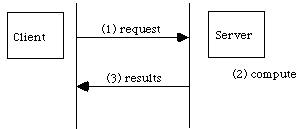
The following two patterns work together. As such they form a trivial example of a pattern language. This language could be extended with Stack and Queue patterns also. I am also an advocate that students should see formal design methodologies early on and begin to work with them. CRC (Class-Responsibility-Collaboration) cards are one simple tool that is easy to use as well as powerful. The simpler aspects of the Unified Modeling Language (UML) are also accessible to novices. In the Linked List pattern I've included CRC cards and a Class Diagram in the style of UML. The sequence diagram in the above pattern is also standard.
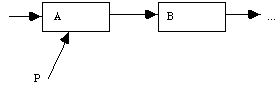
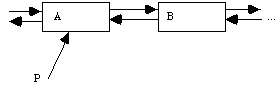
We require some reference (pointer), P, to the node A. Conceptually, we want to clone the node A to which P refers to achieve the following situation.
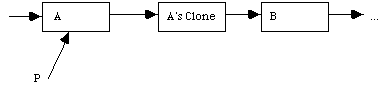
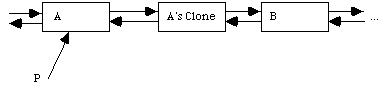
We then normally put a new value into either A or its clone. In almost all cases it is the clone that gets the new value.
(a) a new node must be obtained.
(b) the link field of the clone must be made to be a copy of that from A.
(c) The link field of A must be made to refer to the new node.
Using C++ code this looks like the following.
temp = new Node();
temp->next = P->next;
P-> next = temp;
We may then insert a new value into either the node to which P refers or the one to which temp refers. This step can be performed at any point after step (a). The two cases are detailed below.
If the new value is to be placed into the newly created node (standard) then we complete the operation with
(a') insert the new value into the newly created node.
temp->value = ...;
If the new value is to be put into the original node (uncommon), then we must first copy the old value into the new node to complete the clone operation which was left incomplete above.
(a') copy A's value into the node referenced by temp
(b') insert the new value into A.
temp->value = P->value;
P->value = ...;
In some languages the linkage code does not all appear together. For example, in C++ a Node constructor might provide steps (a) and (b), in that order. For example
class Node
{ Node(T v, Node* n): value(v), next(n){}
...
}
The usage is then just
P->next = new Node(v, P->next);
(a) create the new node.
(b) set its next link to be a copy of that from A.
(c) set its reverse link to be a reference to A itself (as P is originally).
(d) set A's next link to refer to the new Node.
(e) set B's reverse link to refer to the new Node.
temp = new Node();
temp->next = P->next;
temp->reverse = P;
P->next = temp;
P->next->next->reverse = temp;
The operation is then completed by setting values as was done in the case of single linking. Again, the values may be set any time after step (a). Note that the relative orders of steps (d) and (e) are critical to the success of this pattern. Steps (b) and (c) may be reversed, but (b) must also occur before (d).
The suggested pattern of assignments is safe and easy to remember. It has three parts. (1) create the new node (2) fill it in correctly (3) adjust the other links (from A and B) working from left to right.
(1) Node: A node is the basic building block. It contains a data value and a reference to another node.
(2) List: This is the structure as a whole. Its implementation requires a reference to one or more nodes. Additional information is also sometimes maintained such as the number of values in the sequence
(3) Iterator: This represents an abstract reference to a value within the list. Its implementation uses a reference to one node, or perhaps two adjacent nodes. Occasionally an iterator will also maintain a reference to the list itself as well.
CRC cards for the Linked List Pattern follow.
Class: Node Responsibilities: Maintains a data value or a reference to a data value supplied by the user. Maintains a reference or "link" to one other node. This reference may be "empty" or null, or it may be another properly initialized node. Can yield its value to a user when needed. The value can be changed. The "next" link can be changed. Collaborators: List, Iterator |
Class List Responsibilities: Maintains the first of a sequence of nodes. Collaborators: Node, Iterator |
Class: Iterator Responsibilities: Provides access to the values stored in an associated list. Maintains a single location within the associated list, by referencing a particular Node. Can successively refer to each of the elements in the list, starting at the first. Collaborators: Node, List |
The Class Diagram for the Linked List Pattern follows.
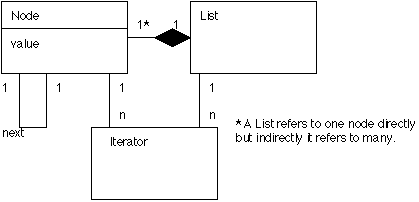
This pattern has certain required classes and the classes have a certain required minimal functionality.
class Node
{ SomeType value;
Node * next;
public:
...
}
class List
{ Node * first;
public:
Iterator newIterator();
bool empty();
...
}
class Iterator
{ List * myList; // Recommended, but optional.
Node * here;
public:
void insert(SomeType v);
// Insert v after this location in a new node.
void remove(); // Remove the value after (not at) this location.
void setValue(SomeType v); // Insert v into this location.
SomeType getValue() // Return the value at this location.
void advance(); // Set the location one place forward.
bool atEnd();
...
}
Note that the Node structure is recursively defined. A special value is often used to provide a base case for the recursion. In C++, the value NULL is used. The Node class is not normally used publicly, but is actually an implementation type for the List and Iterator types.
Most of the functionality is maintained in the Iterator type, not the List type.
Linked lists may also be linked circularly, with the last element connected to the first.
Another variation puts a special "header" and/or a special "trailer" node at the beginning/end of each list. This node does not contain normal data, but is used to simplify testing of position. Such additional nodes can also be used to break the recursive cycle. Sometimes the next field of a trailer node refers to that node itself.
One very important variation does away with the Iterator altogether and provides only access to the head of the list and the rest of the list (its tail). Such lists must necessarily be processed recursively if complex algorithms are to be created. The language LISP is fundamentally based on this idea.
If generic programming facilities are provided in the implementation language, it is recommended that the value type stored in the nodes be generic.