


The Basic Model
Speech Recognition is split into two main phases: transforming the
signal into phones, and then the phones into words.
Signal processing:
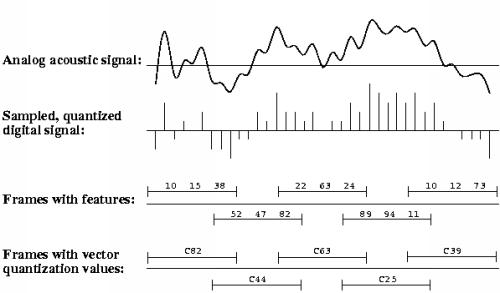
- analog speech signal (energy) to digital
- sampling rate of 8-16 KHz (8000-16000 times per second)
- The quantization factor determines the precision of the sample
and is 8 to 12 bits
- 8000 samples/sec * 8 bits/sample = 64000 bits/sec = 8000 bytes/sec
which yields ~0.5 MBytes / minute
- speaker environment greatly affects the performance
- accents, vocal tracts
- amount of background noise
- filter out for general-purpose speech recognition
- need for speaker identification
Transforming Phones to Words:
- Define each word's pronunciation as a sequence of phones.
- Then transforming phones to words can be done by lookup.
- Homophones are two words with same sound, e.g. heh, hay.
There are also words with multiple pronunciations, e.g. Caribbean.
- Segmentation is separation between words. A fluent language has
little silence.