
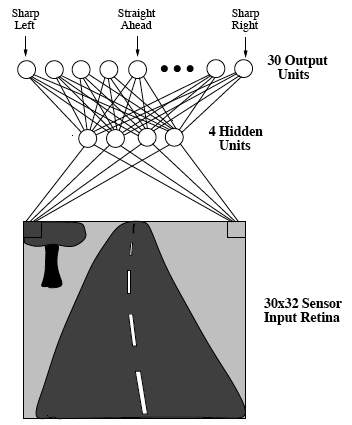
Autonomous Land Vehicle
|
|
Initially, a human driver controls the vehicle for about 5 minutes while the network learns weights starting from initial random weights. After that one epoch of training using the 200 examples in the buffer pool is performed approximately every 2 seconds.