Naive Bayes
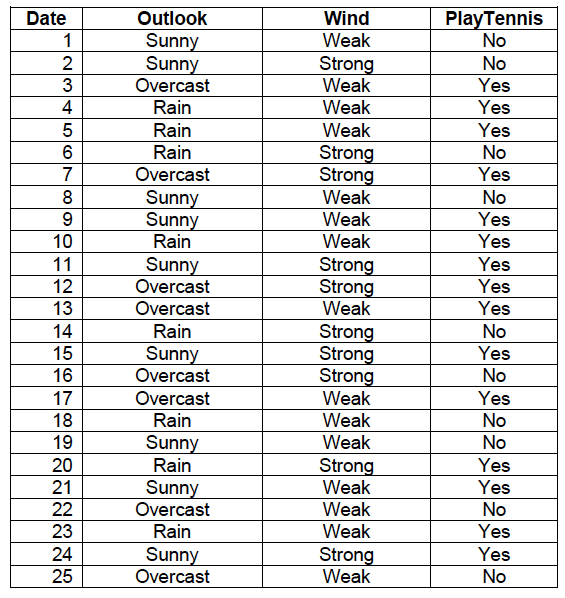
Assume we have the following data set that recorded (i.e., in a period of 25 days) whether or not a person played tennis depending on the outlook and wind conditions.
Each instance (example) is represented by the three attributes.
- Outlook: a value of {Sunny, Overcast, Rain}.
- Wind: a value of {Weak, Strong}.
- PlayTennis: the classification attribute (i.e., Yes means the person plays tennis; No means the person does not play tennis).
 We want to predict if the person will play tennis in the three future days.
We want to predict if the person will play tennis in the three future days.
- Day 26: (Outlook=Sunny, Wind=Strong) -> PlayTennis=?
- Day 27: (Outlook=Overcast, Wind=Weak) -> PlayTennis=?
- Day 28: (Outlook=Rain, Wind=Weak) -> PlayTennis=?
Part 1: Manual Computation
Compute the predictions (i.e., the person will play tennis or not) for the three future days (Days 26-28) using the Naive Bayes classification approach.
Part 2: Analysis with WEKA
-
Convert the dataset provided above (i.e., Days 1-25) into the ARFF format (supported by WEKA), and save it in the "play_tennis.arff" file.
- For the three future days (i.e., Days 26-28), set the values on the PlayTennis attribute by the predictions (i.e., computed manually in Part I, by the Naive Bayes classification approach). Convert the data of these three days (i.e., Days 26-28) into the ARFF format, and save it in the "play_tennis_test.arff" file.
- Launch the WEKA tool, and then activate the "Explorer" environment.
- Open the "play_tennis" dataset (saved in the play_tennis.arff file). For each attribute and for each of its possible values, how many instances in each class have the feature value (the class distribution of the feature values)?
- Go to the "Classify" tab. Select the NaiveBayes classifier. Choose "Percentage split" (66% for training) test mode. Run the classifier and observe the results shown in the "Classifier output" window.
- How many instances used for the training? How many for the test?
- How many instances are incorrectly classified?
- What is the MAE (mean absolute error) made by the classifier?
- What can you infer from the information shown in the Confusion Matrix?
- Visualize the classifier errors. In the plot, how can you differentiate between the correctly and incorrectly classified instances? In the plot, how can you see the detailed information of an incorrectly classified instance?
- How can you save the learned classifier to a file?
- Now use a separate test dataset. In the "Test options" panel select the "Supplied test set" option. Activate the nearby "Set..." button and locate the "play_tennis_test.arff" file. Run the classifier and observe the results shown in the "Classifier output" window.
- How many instances used for the training? How many for the test?
- How many instances are incorrectly classified?
- What is the MAE (mean absolute error) made by the classifier?
- What can you infer from the information shown in the Confusion Matrix?
- Compare the test results with those observed in the previous experiment (i.e., using the splitting test mode).