
In this chapter we will learn about programming with arrays and pointers. In the Standard Template Library, arrays and pointers are one fundamental component, though they are unchanged from standard C++. Most of the major features of the STL are generalizations and abstractions based on features of arrays and pointers.
An array is a block of memory consisting of several items of the same kind. These items are called components of the array. The components are arranged sequentially, one after the other, in computer memory. The computer will store the array with no wasted space in a single block of data. This storage method is sometimes called dense or contiguous storage. An array has a fixed number of components, defined at the time the array is created.
Figure 2.1, an Array
There are two ways to define an array in C++. We are required to give the type of components of the array as well as its length in the definition. The easiest is to use a definition like the following, which defines an array of 12 doubles.
double monthlySalary[12];
This definition actually defines two things, which are most often treated as if there were only one. The first thing created is the array itself. If doubles require 4 bytes of storage, then this array will require a single block of 48 bytes. The second thing created is the address of this block. The address of the block is also the address of the first component of the block. The name monthlySalary actually has a value equal to this address. The location of a component of an array is called a cell. The individual cells of the array are named monthlySalary[0] through monthlySalary[11]. These cells are variables like any other and can hold a value that can be changed. monthlySalary itself is a constant, meaning that it will always refer to this same block of data. Notice that the length of the array is 12, and, since we start with a cell numbered 0, there is no cell numbered 12.

Figure 2.1, an Array with markings indicating cell numbers.
When used as a cell number, an integer is called a subscript. This comes from mathematical usage that would probably write Ai, for the computer scientist's A[i]. A subscript is also called an index.
A very common pattern of use of arrays is the following for loop, which reads 12 doubles from the standard input and assigns them to the 12 components of the array.
for (int i = 0; i < 12; ++i)
cin << monthlySalary[i];
Notice from the above, that subscript expressions may, in fact, be variables. They may also be arbitrarily complex integer valued expressions. C++ has no restrictions here.
The location of the block of data defined by the array definition is up to the compiler to arrange. If an array definition appears at the global level or is marked static, then the block will continue to exist as long as your program continues to run. If the definition is local to a function or to an object, then the array only exists while the function is running or the object exists. Because the lifetime of the array is managed by the system, such data are often called automatic. This applies to all data, not just to arrays.
Be careful with array definitions. The following defines a single double (called a scalar to distinguish it from an array) and an array.
double thisMonth, monthlySalary[12];
Suppose we are building a game program in which the player guesses integer numbers. Suppose that the game needs to remember the guesses made by the player in the order that they are made. One way to do this is to create an array whose length is the maximum number of guesses allowed, together with an auxiliary variable called an index.
long guess[ 10 ];
int nextGuess = 0;
Then, when a guess is made by the player we execute
guess[ nextGuess ] = playerGuess;
nextGuess++;
which first increments the index and then uses that value as a subscript into the array to determine the component into which we save the player's guess. We can, of course, combine these two statements into the single one:
guess[ nextGuess++ ] = playerGuess;
Finally, we can process all of the guesses actually made with
for(int i = 0; i < nextGuess; i++)
... guess[ i ] ...
For automatic arrays the built in function sizeof will tell us the number of bytes required by the array. We can apply sizeof to either a value, such as a variable, or to a type. If we want the number of components, we can divide the size of the array by the size of the component.
Often we want to create arrays in which the components are to be a user defined type, especially a type defined by a class. There are special requirements that enable this to be done. C++ requires a class used in this way have a default constructor: a constructor with no parameters. Since all classes should have such a constructor anyway, and since C++ will provide one if you don't provide any constructors at all, this is a light requirement.
Recall the CountedInt class from Chapter 1. This class has a default constructor since we may call one of the constructors with no arguments. Now we can fill an array with CountedInt values and look at what we have.
void main()
{ CountedInt All [10];
// The default constructor is called for each cell.
for(int i = 0; i < 10; i++)
cout << All[i].getOrder() << endl;
}
Exercise. Test the above code. First anticipate what it will produce. Are you correct?
The second way to define an array actually splits the definitions of the two parts (name and block) into two definitions. We may define a variable that will be used to refer to an array of doubles with
double* dailyCosts;
Here, the variable dailyCosts is defined to be a pointer variable. While pointers can be used in many ways in C++, one of the most important is to make them "point to" arrays. Note that dailyCosts is a variable, not a constant, and so it could hold different values at different times. The above declaration does not give it any value however. It is useful to give every variable some value and C++ provides a value named NULL for use in initializing pointer variables. This is normally just the constant 0, but it guarantees the pointer has a specific value that can be tested. A better definition of dailyCosts would be
double* dailyCosts = NULL;
This both defines the variable, and initializes its value. This looks like an assignment, but it is technically not. It is an initialization.
None of the above defines an array, just a variable that could be used to refer to an array. We could actually define such a variable and make it point to our monthlySalary array with:
double* someSalary = monthlySalary;
This assumes that monthlySalary was previously defined. This defines someSalary as an alias of monthlySalary, and someSalary could be used just as monthlySalary is used. An alias is a name that refers to the same thing, usually a variable, as another name. Note that someSalary is a variable while monthlySalary (as a name) is a constant. We could set the sixth monthly salary using an assignment such as
someSalary[5] = 1200.0; // Set the sixth monthly salary.
However, since someSalary is a variable, it can be used to refer to any array of doubles (or to any single double, for that matter). One way to make someSalary refer to an array is to create the array at run time. The computer reserves a large amount of storage in a structure called the free store or heap which can be used to create things as the program runs. We always refer to things in the free store with pointers, though pointers may refer to locations elsewhere as well. We create things in the free store by using the C++ operator new. Operator new creates variables that are called dynamic. The lifetimes of dynamic values are determined by the programmer, they are not automatic.
someSalary = new double[6];
creates a new array of 6 doubles on the free store and assigns a value to someSalary which is the address of, or a pointer to, this block of data. Having done this, someSalary[0] through someSalary[5] are defined and legal, though the computing system will not be able to detect an expression like someSalary[8] as an error. An important lesson to learn about arrays is that the legality of subscript expressions is up to the programmer to guarantee. The system provides little help here.
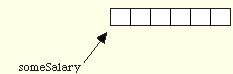
Figure 2.3. A pointer variable and the value it points to.
The C++ system does not guarantee a particular layout of memory, so the following may not work exactly as shown, but some variant will. Suppose we define two automatic arrays with
long array1[5], array2[5];
Then array1[9] might well refer to the same component as array2[4]. This would be the case if array2 were laid out exactly after array1 in the memory.
Exercise. Try the above on your computer and report on what you learn.
We need to distinguish between the pointer variable that refers to an array and the array itself. Given the above, someSalary is an automatic variable that refers to a dynamic value. If someSalary were local to a function, then its lifetime would end when the function returns. The array itself, however continues to exist until the programmer deletes it using something like
delete [] someSalary; // Delete an array.
The delete operator is the inverse of new. It returns previously defined free store values to the heap. Note that delete is used for other values besides arrays. To use the above, however, we would need to write it in a place where the name someSalary is defined. It is possible for a dynamic value to outlive the variable used to create it. Consider the following
double* getNewSalaries()
{ double* result = new double[12];
for(int i = 0; i < 12; ++i)
cin >> result[i];
return result;
}
This function creates and returns an array. Notice that the variable result is automatic and ceases to be at the end of this function. The array itself, however is returned to the caller. Actually, the array itself isn't returned. A pointer to it is returned. The array itself just continues to exist in the free store. It is then the responsibility of the caller to see to its eventual deletion. A function that returns a new dynamic value should clearly say so in its documentation, since deletion of the value becomes a user responsibility.
Automatic arrays in C++ may be initialized with constant values. Suppose, for example that we need an array of strings, and we know the values of these strings in advance. Then we may define and initialize the array at once with something like:
char* days[7] =
{"Sun", "Mon", "Tues" ,"Wed", "Thur", "Fri", "Sat"};
Here days is an array of seven strings (char *). The system will create the array defined by the initializer and make days a constant pointer to it. We could write out the contents of this array with
for(int i = 0; i< 7; ++i)
cout << days[i]<<endl;
We cannot initialize dynamic arrays in the same way. The problem is that a dynamic array must exist before we can give its components values, while an initialization such as the above must exist before the pointer that is to refer to it. In particular, the following will not work.
long* values[5] = new double[5]; // Create a new dynamic array.
values = { 2, 3, 5, 7, 11 };
At the end of this sequence, values will be pointing to a static array and the dynamic array on the free store has no pointer pointing to it. It is a lost block in the heap that cannot be recovered while the program runs. In general, you should never follow a free store allocation by an assignment to the same variable. Between such statements you should either delete the item or create an alias, so that you always have at least one pointer to each free store item. This is true of arrays as well as other things in the free store.
If you define an array dynamically, the sizeof function won't tell you the size of the array if you apply it to a pointer to the array. This is because you are asking for the size of a pointer (often 4 bytes), not the sizeof the array. Therefore, the sizeof(days) will probably be 4. If you ask for sizeof(*days) you will likely get 1, the sizeof a char. The best way to know the size of a dynamic block is to remember it when you allocate it. Save the length you use in a variable.
If we have a pointer variable, we often need the thing that it points to. The prefix operator * is called the dereferencing operator and it will give us the value to which a pointer points. For example, in the above string example, the array variable days is a pointer that points to the beginning of the array. In other words it points to its first component (days[0]). Therefore *days and days[0] may be used interchangeably.
One can also always create a pointer value. Suppose that we have a double value salary. We can create a pointer to it with &salary.
double salary = 4500.00;
double* aliasOfSalary = &salary;
Now salary and *aliasOfSalary are variables that refer to the same entity, namely the 4500.00. Thus the following will increase the salary by 2000.
salary += 1000.00;
*aliasOfSalary += 1000.00;
Thus & and * are inverse operators. One gives us an address from a value and the other a value from an address.
We can apply the above to arrays and array components as well.
double* sal = &monthlySalary[4];
gives us in sal, the address of monthlySalary[4]. Notice that we are using two operators in this expression, operator& and operator[]. The latter has the highest precedence so this is the address of monthlySalary[4] not the fifth component of &monthlySalary (which doesn't really exist since &monthlySalary isn't an array).
Some arithmetic operators can be applied to pointers. In particular an integer may be added to or subtracted from any pointer, and the difference between two pointers (to the same type of thing) may be computed. The meaning is illustrated in the following examples.
long values [10] = { 10, 20, 30, 40, 50, 60, 70, 80, 90, 100 };
long* somewhere = values; // Points to the 10.
somewhere++; // Points to the 20.
cout << (*somewhere) + 2; // Prints 22.
cout << *(somewhere + 2); // Prints 40.
cout << *somewhere + 2; // Prints 22.
cout << *(somewhere + 22); // Prints garbage outside array.
cout << somewhere - values; // Prints 1; the number of
// componenents betweent the two values.
cout << *somewhere - *values; // Prints 10.
Note that the addition operator has lower precedence than the dereferencing operator.
We can generate a pointer to the cell immediately following our array values with
long * afterEnd = &values[10];
It would not be safe to dereference this pointer, but we shall see that we will eventually need this value in the STL.
If we have an array A, then A is a pointer and the expression & A[i] is exactly the same as the expression A+i. In fact the pointer duality law specifies the equivalence of these two expressions. Note that A+i does not refer to a location i bytes past the beginning of A, but the location i components after A. This will be true independent of the component type of the array.
Using the pointer duality law implies that the following for loop will process all of the elements of our array, values.
for(long* p = values; p < afterEnd; ++p)
cout << *p;
What can happen if you are not careful about your array subscripts and equivalent pointer expressions? That depends on whether you are reading values or writing them. If you are reading values from the "array" and your subscript does not fall in legal bounds, then you will get a value, but the value will be meaningless. The computer will interpret the values retrieved as if they had the component type, but, of course, they may not. It is for this reason that (a) you get garbage, and (b) it is hard to recognize as such, since it has the correct form.
If you are attempting to place data into the array (write the array), then the situation is much worse. If you write into a valid cell then you change it, of course. If you write into an illegal cell, one outside the legal bounds, then you change something. That location in the computer memory is very probably being used for something else, and when the value of that item is later retrieved, it will not have the last value that was correctly placed into it, but some value placed by our incorrect reference. There is no guarantee that the value written has the same type as the value read, but any sequence of bits can be interpreted according to (nearly) any type, so the user of that other data item will find a legal value, but the wrong value.
In the worst case, on some computers, you can do serious damage by making illegal array references. For example, on many small computers, a technique called memory-mapped I/O is used in which physical devices such as disks and printers are installed in such a way that they look just like memory. They are controlled by "writing" into their device control registers, which are just memory locations. If an out-of-bounds array reference were to accidentally write to a device register, that device would do something. Perhaps, if it were a disk drive, it would erase that disk. This would be a very unhappy event.
A few final words on pointer arithmetic. Notice that it is bi-directional. You can subtract from a pointer just as you can add. Therefore, continuing the above examples, afterEnd - 1 is a pointer to the last cell of our array.
Actually, pointers are more than just bi-directional. They are actually random access. This means that from a pointer to any cell in the array, we can move immediately, in one step to any other cell. For example, suppose that third is a pointer to the third cell of some array. Then third + 5 is automatically a pointer to the eighth cell, if such exists. Using the pointer duality law, if A[i] represents the third cell, then A[i+5] represents the eighth. In either case we can move from any cell to any other, without visiting the intervening, or any other, cells.
Finally, we may subtract two pointers into the same array. Thus, again referring to the array values from above, afterEnd - values is the number of components of the array; 10. Note again that it is not the number of bytes of storage occupied by the array, indeed some computers are not even byte oriented. Rather it is the number of cells between the two pointers.
In C++ multiple dimension arrays are not technically possible. It is, however, possible to define arrays whose components are arrays, and this has much the same effect. We can give an alternate definition of our days array with:
char days[7][5] =
{"Sun", "Mon", "Tues", "Wed", "Thur", "Fri", "Sat"};
Here we have an array of 7 arrays, each of 5 characters. We describe the array as "7 by 5" or as having 7 rows and 5 columns. We need the "inner" arrays to hold 5 characters, since Thur has four letters plus the terminating null character. The extra character is wasted in the other names, except Tues, of course. In C++ we may have an arbitrary number of dimensions in this way, but be careful since the size of the resulting structure is the product of the sizes in the individual dimensions and the size of the ultimate component type, here char. A large number of dimensions could result in a very large structure, even if the length in each dimension is small. Sometimes an array with two dimensions is called a matrix.

Figure 2.4, a Matrix with 7 rows and 5 columns
This new declaration of days defines a slightly different structure than the original however. In this new definition it is clear that there are a few wasted bytes, since each interior array is required to have five, though most of the values stored require only four. In the original, this wasted space will not be present. The former method of definition is somewhat more flexible because it admits components of differing sizes. The first definition of days defines an array whose components are pointers to characters. The second defines one whose components are arrays of characters. Similar, but not quite the same. Use sizeof to discover the difference.
Just as we can get access to the individual strings by indexing, we can also get access to the individual characters, though we need to use double indexing.
days[ 2 ] [ 0 ]; // Refers to the T of Tues.
days[ 5 ] [ 2 ]; // Refers to the i of Fri.
days[ 4 ]; // Refers to the array containing Thur.
One of the topics in artificial intelligence is machine learning. In this section we present a simple game that learns from its mistakes. It is almost too simple to be called artificial intelligence, but it is only intended to introduce you to the concept and to show programming with arrays.
The French Military Game is played on a graph with 11 nodes, numbered 0 to 10. The game has two sides: the Police and the Fox. The Fox has only one piece, that begins the game at cell 5. The police have 3 pieces, originally at 0, 1, and 3. The police move first and the players alternate. On a turn each side may move one piece along one of the arcs. The object of the fox is to reach cell 0. The police, who may only move vertically and to the right, has the objective of trapping the fox against a sidewall, For example, if the fox is at 6 and the police at 3, 5, and 9, then the police win. If the fox reaches cell 0 then it wins. A game with over 20 moves is forfeited to the fox. (The fox is a spy, trying to elude the police and reach its base.) Play the game a few times with two human players to get a feel for it. Note that there is only one side for the police, not three separate players. When "The Police" moves, it may move only one piece.
1--4--7
/|\ | /|\
/ | \|/ | \
0--2--5--8--10
\ | /|\ | /
\|/ | \|/
3--6--9
In this computer simulation, the computer plays the fox. Initially the computer plays randomly, with a bias toward moving left. However, the fox learns from its mistakes and after only a few games it becomes nearly impossible for the human player to win.
To represent this game board, we use a two dimensional array of integers.
0 2 2 2 0 0 0 0 0 0 0
1 0 2 0 2 2 0 0 0 0 0
1 2 0 2 0 2 0 0 0 0 0
1 0 2 0 0 2 2 0 0 0 0
0 1 0 0 0 2 0 2 0 0 0
0 1 1 1 2 0 2 2 2 2 0
0 0 0 1 0 2 0 0 0 2 0
0 0 0 0 1 1 0 0 2 0 2
0 0 0 0 0 1 0 2 0 2 2
0 0 0 0 0 1 1 0 2 0 2
0 0 0 0 0 0 0 1 1 1 0
This is a definition of the board. It has 11 rows and 11 columns, one for each cell in the graph. A zero at a row, column entry indicates there is no arc from the row entry to the column entry. A non-zero entry indicates an arc, hence a possible path for the fox. The police can't travel all arcs in all directions, so a 2 is used to show a legal police move. The 2 on row 1 (the second row, since they are numbered from 0) and column 2, indicates it is legal for the police to move from cell 1 to cell 2. Such an array is called an adjacency matrix, since it defines which cells in a graph are adjacent (have arcs between them).
One can store this game board definition in a file of 121 integers. This file is read in at the beginning of play and stored in a two dimensional array.
The key to the learning aspect of this game is that there are only 165 legal positions for white. and 11 positions for black. During one play of the game, the computer keeps a record (in an array) of all of the positions that occur.
A single game is stored in a two dimensional array with 20 rows and 2 columns. Column 0 is used for a police position (a number from 0 to 164), and the second column is used to store the fox position (a number from 0 to 10).
At the end of the game it updates a 165 x 11 matrix of weights, increasing all the weights of positions occupied if the computer won, and decreasing them if it lost. When the computer tries to choose a move, it consults this table and chooses one with the highest weight value. This means that the complete results of all positions of all games played can be summarized in a rectangular array of 165 by 11 integer entries. Finding a best move is just searching for the maximum value in a portion of an array. Very simple.
The police position is translated into a number by computing 2a + 2b + 2c, where a, b, and c are the cell numbers occupied by the police. Since no two police pieces can occupy the same cell, and since they are all less than 11, the maximum value of this is 29 + 28 + 210 and no two positions result in the same value. Only 165 different values actually occur (The number of ways to choose 3 items from a set of 11 without replacement, in the language of combinatorics. 165 = (11!) / (3!)(8!)) The 165 different values of this sum are all between 7 and 1792. These are stored in another array. We search this latter array for a police position value and the cell number in which we find the result is used as a row index into the memory array.
From this description you can try to build the game.
In the Standard Template Library there are several other data structures that have components. These data structures are called, collectively, containers. Each of them has some feature different from arrays. Vectors are like arrays except that their length may be changed. Deques can grow also, but at either end. Lists do not use dense, contiguous, storage. Sets don't have a linear or sequential structure. There are several other container classes as well.
Pointers are generalized in the STL to objects called iterators. An iterator has the property that it refers to a specific location in a container, and that this location may be moved by doing simple arithmetic operations. One of the features of iterators in the STL is that they may be used with for loops in a way completely analogous to the way we use pointers and for loops with arrays. Some iterators, like pointers, are bi-directional. Some iterators, like pointers are random access. Other iterators are more restricted, such as forward iterators that can only move in one direction through their container. Different kinds of containers support different kinds of iterators.
The algorithms provided by the Standard Template Library for the manipulation of containers are all defined in terms of iterators. In other words, to manipulate a container using one of these algorithms, we pass the algorithm one or more iterators over that container. This philosophy that the algorithms are defined in terms of the iterators, rather than the containers themselves, makes it possible to write the algorithms in a very general way. In particular, an algorithm that works for lists may well also work for sets or for vectors. Finally, this philosophy makes it possible for these same algorithms to work with the built in arrays of C++ as well as the components of the STL proper.
When we save data in some container, we often want to retrieve the values we have stored. The efficiency with which we can do this is greatly determined by the ordering of the data within the container. Sorting is the problem of putting a collection of data into some particular ordering or relationship. Searching is the retrieval process itself.
One common problem that occurs in dealing with arrays is that of searching for an element that may or may not be in the array. While loops are especially helpful in this. Suppose we have an array A in which we are certain that a value x occurs and we would like to know the cell number that it occurs in. The following loop will tell us.
int i = 0;
while(A[i] != x) i++;
This loop exits as soon as A[i] == x and so we have the desired index. If we are not certain whether x is in the array or not, however, we need to be a bit more careful to avoid searching past the end of the array. The following will serve, where we replace lengthOfA with the actual length of the array A.
int i = 0;
while (i < lengthOfA && A[i] != x) i++;
The test for the length must be made first, so that we can guarantee that an index used to retrieve a value (A[i]) represents a legal subscript. C++ will guarantee that if i >= lengthOfA the second test will not be evaluated and the loop will exit. This is the advantage of short circuiting the evaluation of Boolean expressions. The value is returned as soon as enough of the expression is evaluated to make the answer clear. The same is true of the OR operator; ||. Note that in this search, if the item is not present, the value of i will be left at lengthOfA. This can be tested for. Remember that when you write a loop with a compound exit condition such as here, that when it exits, you don't know which condition caused the exit. Therefore an additional test after the loop is often required.
A for loop can also be used in conjunction with the break statement.
for (int i = 0; i < lengthOfA; ++i)
if ( A[ i ] == x ) break;
this loop will also exit with either A[ i ] containing the desired value or the index equal to lengthOfA.
Exercise: Use the pointer duality law to change the above for loop into an equivalent one that uses pointers instead of subscripts.
The above process is called sequential search, since we look for the item of interest sequentially, starting at the first component. If the array is long, then this can take quite a while. It is possible to search faster if the array is sorted as we shall see.
Next we attack the problem of putting an array in order, assuming that the elements in the array are "sortable." To be sortable, means that the elements of the component type must support operator<. This is certainly the case for the built-in types of C++ and it may be true for user defined types since it is possible for the programmer to give alternate definitions of operator< for user defined data.
One of the simplest algorithms for sorting is called selection sort. The idea behind selection sort is to remove the smallest element from the array, then sort the remainder with the same process, and then to attach that smallest element back to the beginning. The picture in Figure 2.1 should help.

Figure 2.5, Selection Sort Outer Loop
This is intended to be a picture of the sort function in the middle of its operation. The implication is that there is an index i, somewhere between 0 and length-1, and all cells strictly to the left of cell i have been sorted and also contain the smallest values in the entire array.
Each array picture that we draw, called an array section, is intended to represent the state of some array part way through an algorithm. Usually they represent the state of some loop or recursion partly completed. The above picture actually represents a for loop with control variable i in the middle of its execution, as we shall see. When we put a value below the rectangle representing the array we intend it to represent a subscript. When it is inside the rectangle it represents a value. A vertical bar in the rectangle separates the array into two parts that may have different characteristics. If something is known about the elements in some section then we write a description within the rectangle. The positioning of subscripts and vertal lines is significant and in the above case the fact that the subscript i is to the right of the vertical line indicates that the description "Sorted and Smallest" applies only to subscripts 0 through i - 1.
Our job is to complete the process by getting i up to value length-1 so that the part to the left will be the entire array except for one cell. Since that part is sorted and since its values are no greater than the value in cell i = length-1, then the entire array is sorted, which is our aim. The problem then is how to get this figure true, keep it true, and get i up to length-1.
First, it is easy to make this picture true. All we need to do is to set i to be 0. Since there are no cells to the left of i = 0, it is certainly true that it is sorted. Likewise nothing there is any larger than any thing in the part from i through length-1, since there are no cells at all in that left part.
The goal of getting i up to length - 1 can be achieved if we keep increasing i as we progress. We will use a for loop to do this for us. The part about keeping the picture in Figure 2.1 true is the challenging part, and this is where the original idea comes in.
What we want to do is to find the smallest value in the part i...length-1 and move it to cell i. Then, when we increase i, the picture is still true. Make sure that you understand why.
To handle this last part of the task it will be helpful to consider the picture in Figure 2.2.
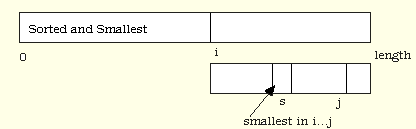
Figure 2.6. Selection Sort, Inner Loop.
The implication here is that we have a picture of the portion between i and length-1. In this section we have an index j and an index s, and cell s contains the smallest element in the section between i and j. If we can get this true, keep this true, and get j up to length-1 we will have found the smallest value in i...length-1. We can then swap cells i and s to achieve our goal of getting the smallest value to cell i. We can make this true initially just by setting s and j to be i and keeping an auxiliary value named small to hold the smallest value discovered so far, the one in cell s. We can get j increased with a for loop. We can keep the picture true just by setting s to value j whenever we discover a smaller value at j as we move j along. This leaves us with the following code for the selection sort. Note that the only requirement we make on the type to be sorted is that it support operator<.
const int length = ...;
float elements[length];
...
void selectionSort()
{ for(int i = 0; i < length - 1; ++i)
{ int s = i;
float small = elements[s];
for(unsigned j = i + 1; j < length; ++j)
if(elements[j] < small) // operator< used.
{ s = j;
small = elements[s];
}
elements[s] = elements[i];
elements[i] = small;
}
}
This is not a very good function, since it will only sort an array named elements, and only if its length is named length and only if it contains floats. We can do better. One way is to pass in the array to be sorted along with the length, so the function sorts its parameter instead of a global value. That would certainly be an improvement. In C++ this would look like the following.
void selectionSort(float elements[], int length)
{ for(int i = 0; i < length - 1; ++i)
{ int s = i;
float small = elements[s];
for(unsigned j = i + 1; j < length; ++j)
if(elements[j] < elements[s])
{ s = j;
small = elements[s];
}
elements[s] = elements[i];
elements[i] = small;
}
}
This is much better, but we still can sort only floats. One way to improve this further is to turn it into a function template . The result won't be a function, but a means of creating functions as needed.
template < class T >
void selectionSort(T elements[], int length)
{ for(int i = 0; i < length - 1; ++i)
{ int s = i;
T small = elements[s];
for(unsigned j = i + 1; j < length; ++j)
if(elements[j] < small)
{ s = j;
small = elements[s];
}
elements[s] = elements[i];
elements[i] = small;
}
}
Note that here, both occurrences of the type float have been replaced by a reference to the template parameter T. This parameter is a type. Later if we need to sort an array of ints, then the system will use this function template, with T equal to int, to create a sorting function for us. It will also be used to create a different function that will sort floats if we need it. The compiler sees to this creation (instantiation) of functions from the template by examining which functions we make use of in our code. This instantiation of template functions from function templates is automatic, but note that it requires the system create different functions for different values of the template parameter.
int intArray[6] = {5, 4, 3, 6, 2, 1};
float floatArray[5] = {1.2, 3.4, 2.5, 0.4, 1.1};
selectionSort(intArray, 6);
selectionSort(floatArray, 5);
One requirement that the writer of a function template must remember, is that the template parameter must appear int the parameter list of the function itself. This is the means that the compiler uses to determine which template function to create. It is not enough to specialize the return type or the body of the function. The template parameter must appear in the function parameter list.
Another means of improving on our selection sort algorithm is to include it as a member function in a class. Suppose we build a class Array to provide additional support that C++ arrays do not have. For example our Array class could provide bounds checking which C++ does not do for built-in arrays. This class would actually be a class template rather than a class, with the element type (component type) as the template parameter. If this were the case, and it is attractive to do, then we might consider making selection sort one of the member functions of this class. In this case, the array elements would be one of the member variables of this class, implementing the class with a built-in array.
These last two solutions, a function template or a member function, are both great improvements over our original version, but note that they still have a restriction. They can only sort arrays. In the function template case we have used an array declaration as the type of one of the parameters. If we have a member function of class Array we are obviously restricted to sorting objects of that type.
However, if we apply the pointer duality rule uniformly we can remove even this requirement. We are going to change selectionSort again. Suppose we pass in two pointers, one that points to the first component of the array and one that points just after the array. A typical call might look something like the following.
int elements[20];
int * start = elements;
int * after = &elements[20];
...
selectionSort(start, after);
To make this work we change the prototype of the function template to
template < class T >
void selectionSort(T* start, T* end)
Now, selectionSort can sort elements without referring to an array directly in any way. The important thing to recognize is the pointer duality law, which states that if A is any pointer to the start of an array, then A[i] is equivalent to A + i. The replacements we shall make are defined as follows:
replace elements[s] by *loc or equivalently &elements[s] by loc
replace elements[i] by *where
replace elements[j] by *inner
See Figure 2.7 and compare it to Figure 2.6.
This gives us the following version, which no longer makes reference to any array, only to pointers that point in to the array.
template < class T >
void selectionSort(T* start, T* end)
{ for(T* where = start ; where < end ; where++)
{ T* loc = where;
T small = *loc;
for(T* inner = where + 1; inner < end; inner++)
if(*inner < *loc)
{ loc = inner;
small = *loc;
}
*loc = *where;
*where = small;
}
}
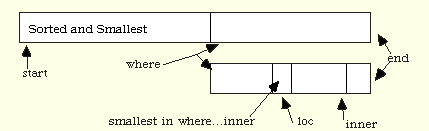
Figure 2.7. Selection Sort, Inner Loop with Pointers
The algorithms of the Standard Template Library are all defined using this last idea. While it is entirely equivalent to the above when we are sorting arrays, the fact that the algorithm doesn't refer directly to arrays but only to pointers means that the same algorithm can be used for other structures that have the property that they can be referred to by pointers. Do note however, that this last version is not nearly as easy to read. Especially for novices. Being less easy to read and understand, it is more likely to have an error.
What essential features of pointers have we used in the above? All we need to do is examine the uses. We have applied operator++ to the pointer variables in several places. We have used operator* to dereference the pointers in several places. We have used operator< for pointers (as well as their dereferenced values). We have assigned one pointer value to another with operator=. We have done pointer arithmetic (e.g. where + 1). Finally, we have implicitly assumed that if we execute start++ sufficiently often then eventually start < end will be false. The implication of all this is that we don't even need pointers. Any datatype that has these essential features could be used in place of pointers here. The iterators of the STL have all of these properties.
It is important to note that we refer to the contents of a container in the STL using two iterators. The first of these refers to some element in the container: its "first" element. The other, however does not refer to any element. It refers to a location "past the end" of the container. In mathematics a range of real numbers is called an interval. There are several kind of intervals depending on whether they include or exclude their endpoints. The interval [a, b], for exammple, includes all of the numbers between a and b, including both of these values, as well. This is called a "closed" interval. The open interval (a,b) excludes both endpoints, but contains the values strictly between a and b. The half open interval [a,b), includes a, but excludes b. In the STL we uniformly use something like this half open interval to refer to our containers, except that the "end points" are iterators, rather than numbers.
It is also possible to sort an array into decreasing order, in which the largest value is first, rather than last. To do so we replace operator< with operator> of course.
Once an array is sorted, it is possible to search in much more efficiently than if it is not. One commonly used mechanism is called binary search which is similar to a guessing game that you may have played. One player announces that she has thought of a number, say between 1 and 100. The other players guess what the number is, and for each guess the original player informs the guesser whether the guess is correct, too high, or too low. A correct sequence of guesses can arrive at the remembered number quite quickly. In fact, if the number remembered is between 1 and one million, it only requires about 20 guesses to arrive at the answer.
The correct next guess, of course, is half way between the largest previous guess that was too low, and the smallest previous guess that was too high. So your first guess in the 1...100 version is 50 and if that is too high you next try 25, which if too low, you next guess either 37 or 38, etc.
In binary search over a sorted array, we first look in the cell in the middle of the array. If that is the desired value we are done, but if that value is larger than the one we seek, then, since the array is sorted, the desired value must be to the left (assuming the sort was increasing). Binary search is called "binary" by the way, since it splits the portion of the array yet to be searched into two equal parts at each step. In other words, each failure reduces the remaining work by a factor of 2.
Here is a recursive version of binary search over an array. It returns the cell number in which it finds the item, or an arbitrary cell number if the target is not present. Because the process is recursive over a portion of the array, we must pass parameters to indicate the subscript bounds of the search.
template<class T>
unsigned int binarySearch
( T* elements, // Array of Ts.
const T& t, // Searching for t in elements.
unsigned int first, // Starting here.
unsigned int last // Ending here.
)
{ if(first >= last) return first;
unsigned int mid = (first + last)/2; // Middle.
if(t == elements[mid]) return mid;
if(elements[mid] < t )
return binarySearch(t, mid + 1, last);
else
return binarySearch(t, first, mid - 1);
}
Exercise. Modify Binary Search by applying the pointer duality law throughout. The parameters of your modified version should be the target plus two pointers, one to the first cell of interest, and the other to the location just after the last. It should return a pointer to the cell that contains the value if found, and an arbitrary pointer into the array otherwise. Be careful about the translation of mid. Test both the original version and your new version.
Quicksort is called quick because it sorts faster than sorts like selection sort. This is because it does more work each time they scan the array. In particular, what we will attempt to do is to establish the truth of the logical statement embodied in Figure 2.8.

Figure 2.8
The idea here is to split the array approximately in the middle around a value t with the property that all values to the left of t are less than or equal to it, and all values to the right are strictly larger. Once we establish this "partition step" we will then recursively sort the two side pieces: the piece from 0 to m-1 and the piece from m + 1 to length - 1. Since this is to be done recursively, and since we need to say in the recursion step what the limits of the sorting are to be, quickSort will need to have two parameters so that we may pass in these bounds. We can establish our plan in an outline as follows
quicksort(first, last) is
if (first < last)
partition, finding m
quicksort(first, m-1)
quicksort(m+1 last)
There are a variety of ways to carry out the partition step. One of the clearest and easiest follows. What we will do first is establish the truth of Figure 2.9.

Figure 2.9
This will be a bit easier to do, since we know where the special "pivot" value will be -- always in cell first. Instead of m, we now use an index named lastLow, that marks the cell in which we find the last "small" value. Note that if we can establish 2.9 then a swap of cells first and lastLow will establish Figure 2.8.
To establish Figure 7.4 we will carry out a process described in Figure 2.10.

Figure 2.10
What we do here is to use an index i, which we move along so that it is eventually equal to last. Cells between first+1 and lastLow are <= t, those between lastLow+1 and i are > t, and we don't know about those beyond i, since we haven't examined them yet. We make this picture true initially by setting i and lastLow to be first. Then all parts are empty except the first cell and the ?? part. We get i to be last eventually, by increasing it in a for loop. We keep Figure 2.10 to be true in the following way. Each time we increase i we examine the new cell i. If its value is > t then nothing needs to be done. On the other hand, if it is <= t, we can increase lastLow and then swap cells i and lastLow. This will reestablish the truth of 2.10 for the new i. Putting all of this together we arrive at the following code for quickSort. We employ an auxiliary function swap, that exchanges the values of two cells.
template<class T>
void swap(T* elements, int i, int j)
{ T temp = elements[i];
elements[i] = elements[j];
elements[j] = temp;
}
template<class T>
void quickSort
( T * elements,
unsigned int first,
unsigned int last
)
{ if(first < last)
{ T t = elements[first]; // t is the pivot.
unsigned lastLow = first;
for (unsigned i = first + 1; i <= last; i++)
if(elements[i] < t)
{ ++lastLow;
swap(elements, lastLow, i);
}
swap(first, lastLow);
if(lastLow != first)
quickSort(elements, first, lastLow - 1);
if(lastLow != last)
quickSort(elements, lastLow + 1,last);
}
}
Note that the portion of this algorithm up to the recursive calls is called the partition step and its result (Figure 2.8) is called a partition of the array.
Exercise. Modify QuickSort by applying the pointer duality law throughout. Your function should have two parameters. They are pointers to the beginning and the "after" position as usual. Test both the original version and your new version.
After correctness, the most important aspect of any algorithm is its efficiency. There are two aspects to efficiency, namely the efficiency of the algorithm itself and the efficiency of its implementation. It turns out that the latter measure is not nearly so important as the former and merely requires that the programmer take care not to execute unneeded instructions. The essential efficiency of the algorithm itself is much more important as it sets limits that no details of implementation can overcome.
Efficiency can be measured various ways. One measure is the space required. If an algorithm is written to run on a multi-processor system then the number of processors required may be an important measure. Usually, however, efficiency means time efficiency. How much time can we expect an algorithm to take to complete?
It must first be recognized that this question cannot be answered in specific, concrete, exact terms. Computers differ in their speeds. Disk drives have differing transfer rates. Multi-user computers have different loads that affect the speed of programs running on them. Most importantly, each time we run a program we likely do so with a different set of input data. This can have a large effect, and we expect that a run with a small amount of data will be faster than one with a large amount of data.
Therefore efficiency is always expressed in terms of some measure of the input requirements (size of the data) or the resources required (memory, processors, ...). Here we will consider only the time efficiency of our algorithms as a function of the size of the input data. We also adopt a measure that will be independent of the speed of a particular computing system on which a program implementing the algorithm might be run.
Some algorithms always take the same amount of time when run on a given system in a given start state (system load, available memory...). For example, an algorithm that returns the first element of an array can be expected to run in constant time independent of the size of the array. However, an algorithm that uses a simple for loop to sum the elements of an integer array must visit each cell of the array, so we expect that its running time will be proportional to the size of the array, approximately doubling if we double the size of the array. But this doubling isn't a precise measure either, since any such algorithm will have a certain amount of overhead (initializing the sum...) that must be done no matter what the number of data items that it processes. Therefore, for example, summing an array of two items using our for loop algorithm will not run exactly twice as long as when applied to one element. However, between 1000 and 10,000 elements the time will be very nearly related in a 1 to 10 ratio, since this fixed overhead will be "amortized" or spread out over a large number of repetitions.
In order to be as precise as possible when presenting the run-time characteristics of an algorithm, we resort to a mathematical means of expressing the upper and lower bounds of functions, here the running time, as a function of the amount of the data processed. What we do, essentially, is to compare the running time function to functions of well known behavior, such as polynomials, logarithms, and exponential functions. These functions have been extensively studied and characterized using Calculus. When the value of function g is always less than the value of function f for a given input x, we say that f dominates g, or gives an upper bound for g. If, on the other hand, function g is always greater than function h at each point of the domain, we say that h forms a lower bound of g. If functions f and h are also quite close together at all input values then we have pinned down the behavior of function g quite well.
Computers run relatively fast today, so the behavior of an algorithm on a small amount of data is only seldom of interest. For most algorithms the time is "nearly instantaneous." The problem gets interesting only when the data set gets large, the time gets long, and we reach the limit of how long we are willing to wait for an answer. So, we are usually willing to ignore the bounds problem for small inputs. With all of this in mind we can give a definition of a precise measure of the upper bound of a function, in terms of another function.
Let f and g both be functions of an integer variable. We say that function g is O(f), read "big oh of f, provided that there is an integer M and a constant C, such that for all x>M it is true that g(x) <= C . f(x). The purpose of M is to ignore small values of x (the size of the input in our application). In effect, this lets us ignore the fixed overhead of the algorithm. The purpose of C is to provide a constant of proportionality that lets us ignore the specific speed of processors. Different systems will just have different values of C.
Note that if our running time is O(f) for some function f, this just means that the running time for input size n is less than some multiple of f(n) for all n that are relatively large. It might be nearly C.f(n) or considerably less. To get a "sharp" estimate of the running time we also need a lower bound.
Lower bounds are expressed quite differently, though it sounds similar. We say that a function g is [[Omega]] (f), read "big omega of f", if there is a constant C such that for any integer N there is an n > N such that g(n) >= C.f(n). Said another way, g is bigger than a fixed multiple of f for infinitely many values. All this means is that it is sometimes "large", not that it is necessarily always large. In terms of running time this means that for some sets of inputs, the program will run for a long time and that this behavior will be observed for more than just a finite number of values.
Normally however, when we give a "big oh" bound for a function, we mean that the running time is indeed close to that bound. So, while it is technically true to describe a function as O(x2), when it is also O(x), that won't normally be done. Note that if a function is big O of some polynomial function then it is also big O of xn, where n is the degree of that polynomial, since any given polynomial of degree n, is O(xn).
We call an algorithm linear if it is O(x), since f(x) = x is a linear function. An algorithm that is O(x2) is called quadratic. One that is O(x3) is cubic. As one extreme, an algorithm with constant running time is O(1), and at the other extreme an algorithm is called exponential if it is O(2n). Exponential running time algorithms take extremely long to execute on large sets of data as illustrated by the following exercise. Another commonly used bound function is the logarithmic function log2(n). An algorithm with such a bound is described as logarithmic.
Exercise. Suppose that you have an exponential algorithm that takes 1 second to complete if the size of the input is 16 items. For each additional item the time doubles. How much time does it take on a set of 64 items? Suppose your computing cost (cost of time and depreciation on the machine + electricity consumed) is one penny for 16 items. What does it cost for 64 items using the same formula?
The sequential search algorithm presented above is linear, of course. The number of steps it executes is directly proportional to the length of the array as can be inferred from the use of the for loop. Likewise the selection sort algorithm is quadratic, since it contains two nested loops, each of which is linear. In general, algorithms built out of loops are relatively easy to analyze for their run time bounds. Recursive algorithms and some others are a bit more challenging.
One means of analyzing the running time of an algorithm is to write down an equation that describes the running time and then to solve it. Even though we know that sequential search has linear running time, let us use this technique to analyze the efficiency as an illustration of how to go about it.
In sequential search we look at one item in a set of n and if that is not the target of the search we still need to examine n-1 others. Therefore if there is a single item in our container we take one unit of work to verify whether or not that item is the target. If there is more than one item, say n, then the work required is one unit to check the first item plus the work required for the other n-1 items. If we write down this work equation, where Wn represents the work done for n items and Wn-1 the work for n-1 items, we get the following.
Wn = 1 + Wn-1, if N > 1 and W1 = 1.
We can solve this by repeated substitution, replacing a work term on the right hand side by its definition using this formula itself. Notice that we start with n-1 on the right and a single 1. If we substitute the meaning of Wn-1 = 1 + Wn-2 into the above formula we get:
Wn = 1 + ( 1 + Wn-2 ) = 2 + Wn-2
If we repeat this we get
Wn = 2 + Wn-2 = 3 + Wn-3 . . . = n
That is to say, the work to process n items is n times the work to process one item. This again justifies the statement that the work of sequential search is proprotional to the length of the array.
Suppose that we try to analyze the running time of binary search in this same way.
The binary search proceeds by doing one unit of work to look in the center location in the array. If that is not a hit, then the recursion says that the binary search must do the same process over a data set half as large. Of course, if the array only has one item it only takes one unit of work. We just verify that that item is, or is not, the target of the search. Suppose that we again let Wn represent the work done (time expended) for exactly n items. Then an equation defining this work that corresponds to the first two sentences of this paragraph is
Wn = 1 + Wn/2, if n > 1, and W1 = 1.
This can be solved if we substitute n = 2k into the equation and then do repeated substitutions on the right hand side using this definition itself.
W2k = 1 + W2k-1, if n > 1, and W1 = 1.
= 1 + 1 + W2k-2
= 1 + 1 + 1 + W2k-3
. . .
= k
Therefore Wn = k = log2(n), and we have a logarithmic algorithm. This is very good, since the log of a number is small in comparison to the number. This justifies our earlier claim that we can binary search an array with a million items with only about 20 repetitions.
Exercise Normally the quick sort exhibits the following behavior. The partition step splits the array into two parts of about equal size. Therefore the work done is the work done to do the partition, which is linear, plus the work done to quick sort the two halves. But this is just twice the work required to sort an array half as big. Of course, an array with only one element takes no work at all to sort, since it already is sorted. Use this idea to verify the claim that quick sort is O(n log2(n)).
Some algorithms work well on most data sets but perform badly on a few. Quick sort as presented here is such an algorithm. In an average case the quick sort is O(n log2(n)). However, the algorithm as presented has a very strange behavior if we give it a sorted array to start with. In this case, the partition doesn't divide the array into two parts of equal size, but into one part that is empty and the other which has just one less element. So, in this case, the running time is the time required to do the partition (linear) plus the time required to sort an array with one less item. Now the recurrence is
Wn = n + Wn-1, if n > 1, and W1 = 0.
It is easy to show that the solution of this "recurrence relation" is a quadratic function of n. Therefore, quick sort is no better than insertion sort on a few cases. For quick sort we say that the average running time is O(n log2(n)), but the worst case running time is O(n2). As a shorthand we will use lg(n) in place of log2(n) as the log base 2 commonly occurs when measuring efficiency.
There is another measure of running time that is occasionally useful, though not for these algorithms. Suppose we want to build a class to implement arrays that can be expanded. A nice technique is to do the following. The class has a member variable that is a dynamic array of some convenient size at creation. If we later learn that the array was too small we "expand" the array as follows. Allocate a new array, twice as long as the original, copy the elements from the old array into the new one, and then delete the old array, assigning the new one to the member variable. If we ask how much time it takes to insert an element into this "array class", the answer is that it depends. If it is not time to expand, the time is constant, If an expansion is required the time is linear in the number of items currently stored, to account for the copying time. But if we average this out over all insertions, we find that the (average) time is still constant, actually about twice the time of one of the atomic instructions. Note that to make this work you must double the size when you expand, not just increase it by a fixed amount. Such an algorithm is called "amortized constant," since we amortize the cost of an expensive operation out over several cheap operations, with the average being constant.
Most of the algorithms provided with the Standard Template Library work for arrays as well as those additional containers provided by the STL itself. This was one of the primary design decisions of the STL. They work because pointers into arrays satisfy the requirements of random access iterators. Since most of the algorithms work with such iterators, they work with arrays.
To use the algorithms you must include the header <algo.h> provided with the STL and probably provided with your C++ compiler. To sort an array, we need a pointer to the beginning of it and a pointer to the cell that would immediately follow the array (not a pointer to the last cell, a pointer to the following cell). Consider the following test example
int testArray[5] = { 3, 1, 4, 2, 5 };
int * first = testArray;
int * last = &testArray[5];
sort(first, last);
for (int i =0; i< 5; ++i)
cout << testArray[i]<<endl;
This produces
1
2
3
4
5
Notice that the sort function doesn't mention the array that it is sorting. It only needs pointers to the first cell and the "last" position. Technically, in the language of the STL, sort takes two iterators as arguments and sorts the section of the container between the two iterators, including the item at the location of the first iterator and not including the position of the second. Sort works for many (but not all) of the container classes, and most algorithms take one or more iterators as arguments.
There are two requirements for using the sort routine of the STL. The first is that the pointer must dereference to a type that supports operator<. In other words, the component type must support this operator. The second is that the operator< of that type must have the property that if a < b then it is not true also that a == b. If your type doesn't meet this specification then you might get a compiler error that operator< is not defined, or if it is but the operator fails to satisfy its condition, then using sort may result in an infinite computation.
A somewhat less obvious requirement of the STL sort is automatically fulfilled by arrays and array pointers. Sort requires that the iterators (here pointers) passed in satisfy the requirements of random access iterators. Since array pointers have this property this is not a problem, but applying sort to some other data structures (e.g. linked lists) might not be possible.
The STL sort algorithm is a variation of quicksort. It is a bit more sophisticated than the one shown above, as it works efficiently for already sorted arrays, though it will be inefficient for some collections of data. The STL has other sort routines that are slower on average than sort, though they can be guaranteed to always be faster than quadratic algorithms like selection sort. See heap sort in the index, for example.
Another STL algorithm that can be used in exactly the same way as sort is reverse, which reverses the elements of an array (or other container).
Note that when you apply one of the STL algorithms using an iterator, the value of that iterator may change. It may no longer point to the location to which it originally pointed. We say that an iteration "consumes its iterator."
One of the important problems in computer processing is how to efficiently and effectively store large amounts of information. The solution is called a database. We shall present an extremely simple solution here, that is not really adequate for large amounts of data, but it introduces a few key concepts.
Data is stored so that it may later be retrieved. Usually the data is stored once, updated infrequently, but accessed frequently. Eventually the data will likely be removed. For example, when a new employee is hired a new record is placed into the employee database, describing the relevant information about that person. The data is modified or updated only when some piece of information changes, such as name or address. The data is retrieved at least as frequently as the pay cycle, since it is needed to write a paycheck. Finally, when the person leaves employment the data is removed from the active part of the database, though the information may simply be moved to an archival region.
Since retrieval is done more frequently than creation/modification/removal, it is important to organize the database so that lookups are fast, even if this somewhat slows the speed of insertions. One of the chief ways that this is achieved is to choose from among all of the data to be stored, some portion that can be guaranteed to be uniquely associated with the data entity (here person) and that will not be the same for any other entity. This portion of the record is called the key, and the remainder of the data for that entity is called the information. Therefore, data is a collection of key-information pairs. Social Security Numbers are often used in the United States as a key for employee records, since they are required to be maintained by employers (for taxing purposes) and they are also (supposed to be) unique. In general, however, the type of the key and the type of the information differ from one database to another, and even from one portion of the same database to another, so it is useful to abstract these types. We can do this with a class template.
template <class Key, class Information>
class DataRecord
{ public:
DataRecord(Key k, Information v):key(k), information(v){}
Information getInformation() const
{ return information;
}
bool match(const Key k) const
{ return k == key;
}
private:
Key key;
Information information;
DataRecord(){} // Needed to create arrays of DataRecords.
friend class Database<Key, Information>;
};
We can now build a database using an array to hold DataRecords. This solution, as mentioned before, is overly simplified as it requires that we know the maximum size of the database in advance, which is seldom the case.
template <class Key, class Information>
class Database
{ public:
Database(int size)
: currentSize(0),
storage(new DataRecord<Key, Information> [size] )
{
}
void store (const Key k, const Information v)
{ storage[currentSize++] =
DataRecord<Key, Information> (k, v);
}
Information retrieve(const Key k) const
{ for(int i = 0; i < currentSize; i++)
if(storage[i].key == k) return storage[i].information;
return Information();
// The default value of type Information;
}
private:
DataRecord<Key, Information> * storage;
// Save the data in an array.
int currentSize;
};
We can now store information into our database, where it is saved in the next available slot in the array. We can also retrieve the information associated with any key, though it takes a sequential search of the database to achieve it. Thus, though it works, it does not satisfy the efficiency requirements that specify that lookups should be fast. Here insertions are fast but retrievals are very slow.
To create a database you need to specify the key and information types as well as the maximum size.
Database< int, char*> BonMot(100);
BonMot.store(22, "Have a nice day.");
BonMot.store(11, "Have an OK day.");
BonMot.store(33, "Have a wonderful day.");
BonMot.store( 5, "Have a day.");
cout << BonMot.retrieve(11) << endl;
cout << BonMot.retrieve(99) << endl; // Prints garbage.
Exercise. Speed up retrievals, even at the expense of insertions. One way to do this is to sort the database after each insertion. This requires that DataRecords have an operator<, which you will need to write. This operator should consider only the keys and ignore the information values.
Exercise. Devise a better mechanism for signaling that the data sought is not to be found. You can turn retrieve into a bool function that returns its information value in a reference parameter, for example. Throwing an exception is another possibility.
If we assign a value to some component of an array, then a copy of the value is made and stored at that component. Sometimes we want to avoid this copying because of its cost, or because the logic of the problem dictates that we not make copies of things. In this case we may store pointers to values rather than values themselves as the components of the arrays. This same technique may be applied to other containers as well, of course.
For example, in a database, it might be desirable to store the same objects in several places without copying. We try to keep only a single copy of data in a database to simplify the problem of updating values. If several copies of a piece of data are stored, then all must be updated at the same time. One way to achieve this is to avoid copies altogether, keep one copy of each piece of data and use pointers as needed to simulate replication.
To do this our database will store pointers to data records rather than data records. Each cell of the array will contain just a pointer to some actual data record, or possibly be NULL.
Aside from the avoidance of copying, there is another major advantage of using pointers as the contents of our containers. This is the possibility of making the containers heterogeneous: of storing different types of things in the same container. This can't be done with complete freedom in C++, however, since pointers have a type that includes the type of the thing that they point to. However, we may use the object oriented features of C++ to achieve heterogeniety. We return again to derived classes.
Since we define a new class when we derive one class from another, we have different types. However these types are partly compatible with each other. In particular, a pointer to a base type may hold a value that is a pointer to a derived class. This means that if we have a container, such as an array, defined to hold pointers to some class, then it may in fact hold pointers to any class derived from that class. For example, we may create an array of pointers to SpreadSheetCells and store pointers to NumericCells and FormulaCells as well.
SpreadsheetCell* lotsOfCells [100]; // Array of cell pointers
lotsOfCells[0] = new FormulaCell(...);
lotsOfCells[1] = new NumericCell(...);
As a final brief note, we mention that pointers may be used to refer to other things than arrays. One of the most fruitful uses is to use pointers as links to chain data cells together. Each cell will now contain not only a value, such as an array cell does, but also the address of another cell. In this way the cells do not need to be stored contiguously, but can be anywhere in the free store. The advantage of this is that it is quite easy to insert a cell "between" two other cells and nothing needs to be moved. All that is required is that the addresses that impose the physical ordering on the cells be updated. In this way we can build sequential structures called linked lists. More generally, we can use more than one such address in a cell and build non-sequential structures such as trees and graphs. Lists will be taken up in detail in Chapter 8.
Make certain that you understand each of the following terms
Array
Array Section
Alias
Big O
Binary Search
Cell
Component
Half Open Interval [a, b)
Index
Iterator
Pointer
Pointer Duality Law
Quicksort
Searching
Selection Sort
Sequential Search
Sorting
Subscript
1. Build a calendar generation program. Fill in a 6 by 7 array with numbers representing the days of a month. Consider columns to represent the days Sunday, Monday, ..., Saturday. Input a date a build a calandar for the month containing that date. If a cell does not correspond to a day in that month, give it a zero or negative value. Provide a print routine to print nicely formated monthly calendars.
More sorts
More use of stl
apps