The first object-oriented language was Simula, developed in Scandinavia in the late 1960's and early 1970's and it was truly and completely object-oriented. Several languages have been developed since then that implement the Simula object model more or less completely.
A Taxonomy of Object Languages
About 10 years ago, Peter Wegner of Brown University developed a taxonomy of object systems that attempted to define a range of possibilities from not object-oriented at all (C or Pascal) to completely object-oriented (Smalltalk).
Wegner's taxonomy, brought up to date, is a linear scale with five points. Each level is an extension of the previous level and assumes all features of that previous level.
(1) No object facilities -- e.g. C and Pascal.
There is no facility for encapsulating state and process simultaneously. State may be encapsulated in records/structs, and process may be encapsulated in functions.(2) Object based -- system uses objects. e.g. Self, Modula-2.
Objects encapsulate state information along with the processes that manipulate that state. These objects may be defined using various mechanisms, including direct construction from parts. The procedures/functions that manipulate the state are called methods. Asking an object to execute a method is called a message.(3) Class based -- system uses objects that are defined by classes. e.g. Actor, CLU, and Ada-8x.
The objects in the system are defined by a type definition mechanism called a class. A class describes a family of similar objects, with identical structure. Each object defined by a single class has the same methods and state variables.(4) Inheritance enabled -- system uses classes and inheritance. e.g. C++ without virtual methods.
Classes within the system may be defined as extensions and specializations of other classes making it possible to build hierarchical (or DAG based) taxonomic type structures in the language. Methods may be statically (by the compiler) dispatched. Methods may be overridden.(5) Object-oriented -- system uses classes, inheritance and polymorphic (virtual) methods. e.g. Smalltalk, Simula, Beta, Java, Eiffel, Modula-3, Oberon II, Ada 95, Cobol 97.
Focus of execution control switches from client to server. A message sent to an object is interpreted by the object which then chooses a procedure to execute. Every message sent to an object is interpreted in the context of the most specific type of the object. Methods are dynamically dispatched.C++ can be programmed with an object oriented (level 5) style, though it is most often used at levels 3 or 4. This will be explained below.
Some readers may not be familiar with object-based languages so some explanation. In Modula-2, a module can be used to define an object. The module interface can define a (single) stack and export functions to manipulate it. Importing the module creates a single stack. You cannot create two stacks by instantiating it twice, however. If you want two stacks you need to write two modules. This is object based but not more. Note that other mechanisms of Modula 2, such as exporting a type from a module are not even at this level, since the procedures to manipulate the type are defined outside the type. Some languages like Self are object based (state & method encapsulation) without having classes but go a bit further than Modula-2. Any object can be directly created and can serve as a prototype (through cloning) for the creation of other similar objects.
Next, some languages are class based but nothing more. The original version of Ada has generic packages. A generic package encapsulates state information about a structure such as a stack but also exports all procedures that may manipulate that state. A generic stack package may be instantiated several times to create several stacks. Inheritance is not possible here. If you want a more specialized sort of a stack structure, you need to write a different generic package, unrelated to the first.
Niklaus Wirth, in his elegant type extension work that culminated in the Oberon language, defined a system with objects defined by classes and classes extensible with inheritance. A subclass is a specialization of its parent. A superclass defines objects that are projections of objects defined by its subclasses. (Note: Wirth did not invent inheritance, as it existed in Simula. However, he factored it out as a separate facility.)
Truly object-oriented languages however go beyond these compile-time mechanisms and modify the run time behavior of systems. In a fully object-oriented system the static text of a program does not precisely reveal which functions are being executed. This is because the system uses run-time information to dispatch methods. A variable may refer to objects of different types (i.e. polymorphic). If that variable is used to send a message to the object to which it refers, then that object will interpret the message and execute its own corresponding method. Thus the same message statement, executed twice, could do vastly different things on each execution, if the variable named in the message refers to different objects in the separate executions. In a language that defines facilities up to level 4, message sending is equivalent to ordinary procedure invocation.
What is Dynamic Dispatch?
In a hybrid language like C++ not all messages sent are interpreted polymorphically though it is often useful to adopt a single mental model (message passing) for both static and dynamic dispatch. So, to explain dynamic dispatch and its consequences, let me suppose a fully object-oriented system like Smalltalk or Java as the base. I will mention at the end how to do the same thing in C++.
The underlying assumption is that objects are autonomous and encapsulate the methods within themselves. The methods that are invoked in response to a message (client request) are not outside the objects, but inherent as part of the objects permanent state.
In normal procedure invocation, the focus of control is with the caller. The caller decides precisely which procedure will be called and precisely what code shall be executed. The data are passed to the procedures as parameters but are static, being acted upon by the procedures and exercising no control over the process by which they are modified.
Envision a system with the following characteristics --fairly common in practice.
a) the system is built by a team, with different individuals responsible for
different parts.
b) the system must process many kinds of items, some of which are quite similar
to each other
Suppose person A builds parts AX and AY and person B needs to use them. Suppose the parts are similar. One way to define "similar" parts in C or Pascal is to use tagged typed unions (C) or variant records (Pascal).
Person B will write a procedure to manipulate an AX or an AY and the code will use a switch(case) to distinguish cases and "do the right thing" in each case. In any case person B has the responsibility to choose the code that will be executed. Note that if there are others C, D, ... who must also manipulate AX and AY, then there will be various switch statements throughout the system distinguishing the cases.
If needs change, then all those switches need to be found an modified. If we add a new part AZ, then all the switch statements need to be found and extended. This is because the focus of control is on the client of AX and AY and there are probably several clients.
Note also that person A, the original developer of AX and AY has reduced responsibility for the correct use of AX and AY and limited ability to control it. Person A may define several procedures for the correct manipulation of these parts, but person B... are free to write additional procedures.
Now envision an object-oriented system. In which person A builds objects AX and AY and encapsulates all code that manipulates their state within them. The AX cases from all of the switch statements of the first system will now appear as individual methods of AX. Similarly for AY. AX and AY are defined by classes. These classes are subclasses of a common base class. Therefore AX and AY are "similar". The base class defines how similar they are. The base class defines some methods that enforce the similarity. Suppose that draw is one of these methods.
Now, person B, desiring to manipulate AX and AY sends messages to the objects and each object itself "does the right thing" by executing the code that it has internally. The client (B) does not control what code is executed, only what service is requested. The object itself controls what code is executed. Now the focus of control is not with the client but with the server.
If AX and AY are indeed similar, then it is possible in an object system that the same variable could refer to each of them at different times. The variable would have declared type to be the base type of the classes of AX and AY. In particular we might see the code
M.draw();
where M is an object reference and draw is the service (message, method) name. This statement may be executed several times and each time it is executed the variable M might refer to a different object--even an object of a different class. If that is the case the code executed on the separate executions of this statement will be different each time, controlled by which object M refers to on that invocation. So the focus of control really is with the server (the object to which M refers) not the client (this statement.) This methodology of invocation is known as dynamic dispatch since it can only be done (in general) at run time. In a level 4 or less system, the dispatch would be static, based on the declared (compile time) type of the variable M. In a level 5 system, the dispatch is based on the actual (run time) type of the object to which M refers when the statement is executed.
Why Dynamic Dispatch?
The effect of this in a large system is to give person A, more responsibility for the correct behavior of AX and AY and to focus that responsibility and control in a single place in the program--the definition of the classes that define AX and AY, rather than distributing it throughout the client code. In fact person A should have the responsibility for the correct behavior of AX and AY. This is because these objects are service providers and person A is responsible for correctly defining the services that they provide. Object technology simply gives the developer of the server code the tools to enforce a usage protocol. This level of control (control of potential error) is harder to achieve in a procedural program. It is especially hard to guarantee it in a procedural program.
By the way, an object programmer when looking at a switch statement will always ask "Have I got a proper object decomposition? Should the code in this switch be distributed to objects?". The answers aren't always NO-YES, but they often are. A switch (logic bottleneck) is a flag signaling potential poor object design.
This has a positive effect on maintenance of the system. If AX turns out to be broken, we know where to look for a fix. We don't have to find all of the switches in which AX is manipulated. It is manipulated only within its own methods and this code is not mixed up with code manipulating other objects. Similarly if the behavior of AX needs to be modified then it is the methods of AX's class that must be changed-- and perhaps no other part of the system (as long as its interface and semantics don't change too much). If the system needs to be extended, then we don't modify any existing software, we write a new class description for the extension (a class for AZ) that encapsulates the behavior of AZ and turn it loose for clients to use.
More on Dynamic Dispatch-- C++
To achieve Wegner's level 5 situation in C++ requires that all objects be referred to indirectly, either by pointers or reference variables, and that the methods invoked be virtual. Otherwise what we call a message send is really just a (client controlled) procedure invocation. Note that the "this" variable in C++ is a pointer to an object (const pointer, actually) so that all virtual methods invoked on "this" are polymorphic. Likewise virtual methods invoked on pointer or reference parameters of a function are virtually bound.
Dynamic binding is very subtle but very powerful. One of the consequences of it is that you can guarantee the execution of code that doesn't yet exist when you write the invoking call. The following is a bit technical and can be skipped on first reading.
void A()
{ b(); // i.e. this->b();
}
};
class derived: public base
{public:
void b()
{ cout <<"I'm a derived" << endl;
}
};
void main()
{ base B;
derived D;
base * XXX = &B;
XXX->A(); // calling a method of base
XXX = &D;
XXX->A(); // ditto
}
OUTPUT:
I'm a base
I'm a derived
class base
{public:
virtual void b()
{ cout << "I'm a base"<<endl;
}
If b were not virtual then the two outputs would be the same ("I'm a base"). Likewise in a level 4 language with only static dispatch.
A Mental Model for Object-Oreinted Programming
Adapted from [1], Chapter 2.
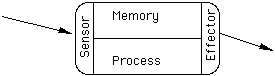
Object oriented programming using virtual methods with pointers and reference variables in C++ requires that a programmer will adopt a certain mental model, or set of ideas, about the nature of the computational system that she or he is using. In many ways this system is similar to the model used in standard C or Pascal, but its differences are important. Rather than thinking of a single computing mechanism (CPU) with a single memory, it is useful to think of a single processor and many memories. Each object in the system should be thought of as having its own memory. In fact, the most useful model considers each object to be composed of four parts: memory, process, sensor, and effector. (See Figure 1.) An object sends messages to other objects using its effector. This is just an outward directed communication channel. Likewise it receives messages through its sensor.
Figure 1.
Within the methods of a class, the receiver of a message (who must be in the class of the method), is referred to by the standard identifier "this." The model of execution is that the object itself executes the method (rather than a "computer" executing a procedure). The object currently in control is the object executing the method and it knows "itself" by the name this. Therefore within a method of a Stack class, a procedure or other message may be called, and the object "this," which is executing, may pass itself to that other procedure or method using the reference variable this.
When an object receives a message via its sensor, it matches the message with some method in its own process part. It then executes that method. As a consequence of executing the method it may change some values in its memory part and it may also use its effector part to send messages to other objects, or even to itself. Thus a system in execution might be depicted statically with a picture like Figure 2. Here we have several objects in the system. The arrows indicate messages that have been sent at some time.
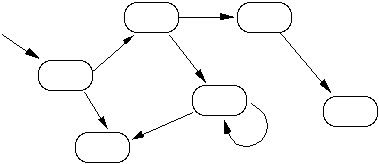
Figure 2.
We might refine this picture to give it a more dynamic element, which is really the case in a program in execution. Recall that our model has only a single processor, or CPU. At any given time some object in our system has control of this processor. Suppose we indicate the object with control using a filled oval as in Figure 3.
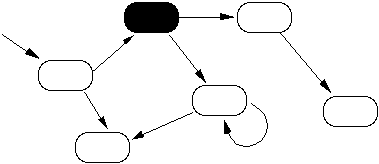
Figure 3
When the object in control sends a message to another object, it passes control of the CPU along the message path to the other object. This might leave us in the situation of Figure 4.
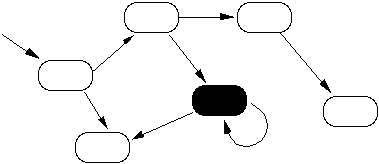
Figure 4
Eventually, all messages directly and indirectly sent because of our sending the message that just took us from Figure 3 to Figure 4 would complete. At this point the processor would be passed back along the message path and we would again be in the situation of Figure 3. If the message is functional, then results will be passed back along with the processor. However, each of the objects that received messages as a result of this one message send have had control of the CPU, have executed methods, and have, perhaps, changed their own memory variables as a result. Notice that a simple modification of this model would permit there to be several CPU's. Therefore, the object programming model can be used as a simple way of thinking about parallel programs.
A slightly more accurate picture of a single object is shown in Figure 5. Here we indicate a possible implementation of objects. The effector part is nothing more than the presence of instance variables in an object whose types are class types. Here we indicate two such variables, though there could be any number of them. An object gets access to another object, enabling it to send messages to that other, by maintaining a reference to it. Therefore the effector is, in reality, just part of the memory. The memory may also have values that are not references to other objects. These values might be integers ,or arrays, or whatever else is appropriate to the class of the object.
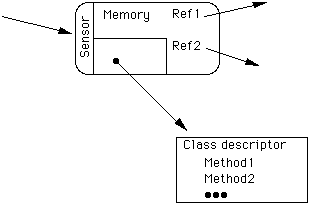
Figure 5.
An object gets access to its process part by maintaining a reference to a class descriptor stored in the running computer. This descriptor contains all of the methods defined in a given class. When an object is created within a class it is given a reference to this descriptor and it can never change it. Thus, an object, once created within a class, is always a member of that same class. Inheritance is implemented by also giving each class descriptor a reference to the descriptor of the parent class of the given class. Therefore, an object has a way to get access to the methods of its own class, as well as the methods of ancestor classes.
Notes.
C++ notes. Constructors are never virtual. "Virtuality" in a method is always inherited, so that we don't need to mark derived:: b as virtual, though we may for documentation purposes. I usually do myself. If a class has any virtual methods then it should have a virtual destructor--even if that destructor does nothing. This is to guarantee that the correct destructor is invoked in some situations (when a base class pointer points to a derived class object and we destroy via that pointer). A class with a virtual method is called polymorphic. Polymorphic classes require a different (slightly more expensive) runtime layout than non-polymorphic classes. If a class is polymorphic then you can obtain run-time-type-information (RTTI) about objects of the class--not otherwise. In particular you can query an object from a polymorphic class as to its most specific type.
Java notes. All methods are virtual so there is no such keyword in Java. All objects are accessed via reference variables (i.e. indirectly) so all messages are dynamically bound and polymorphic. The indirection is not as obvious in Java as it is ubiquitous. All objects support RTTI. All objects in Java are specifically created with calls to operator new and are therefore heap based. There are no destructors, as a garbage collector handles cleanup. Programmers may write "finalize" methods so that objects may be guaranteed to release global resources (file handles...) before they are garbage collected. The garbage collector has very low impact on the system. All inheritance is public.
Generic programming (templates) is independent of object orientation. It is often seen within object based languages, but could be implemented in other kinds of languages as well, even functional languages. Object orientation and templates are often found together since both are useful in abstract data types, though they perform complementary functions.
Frameworks and pattern based solutions are independent of object orientation though they seem to have grown up within the object technology community. Frameworks can be easily developed as class hierarchies, however.
Direct manipulation graphical user interfaces are independent of object orientation as are graphical application builders. For example, Visual-Basic is not object oriented in any sense. Object orientation, however, offers advantages to GUI builders.
Bibliography and Further Reading
[1] Bergin, Data Abstraction: The Object-Oriented Approach Using C++, McGraw-Hill, 1994.
[2] Wegner, "Dimensions of Object-Based Language Design," OOPSLA '87 Proceedings, ACM SIGPLAN, 1987.
Last Updated: March 31, 2000