| CS631p- Human-Computer
Interaction |
| Spring 2001 |
| Lecture 8 |
Speech,
Language, and Audition
Communication between humans
- speech/hearing -> audio
Communication between humans and machine
-> not so
Issue of Speech
General characteristics of speech:
-
Described as:
-
An acoustic signal - speech is generated by the articulatory
apparatus, and perceived by the auditory system.
-
Tightly structured system of symbols and meanings
- linguistic information in speech signals is always described in terms
of discrete and static symbols, like speech sounds, syllables and words.
-
Speech sounds are generated in the vocal tract - the
non-uniform tube formed by the throat (pharynx), the oral cavity (the shape
changed through tongue and jaw movements) and the nasal cavity, the shape
of which is constant (but very different between speakers).
-
The dynamically changing tube is acoustically excited at
the very far end (by air pulses released through the vibrating vocal folds)
or closer to the near end (the lips), by the turbulence caused by air that
is forced across sharp ridges.
-
Different speech sounds correspond with different shapes
of the vocal tract, and with different excitation sources.
-
Speech signals are described by spectro-temporal characteristics
. Best way is to stack short-time spectra,
short segments of the signal.
Below: oscillogram (top) and spectrogram of
a short utterance
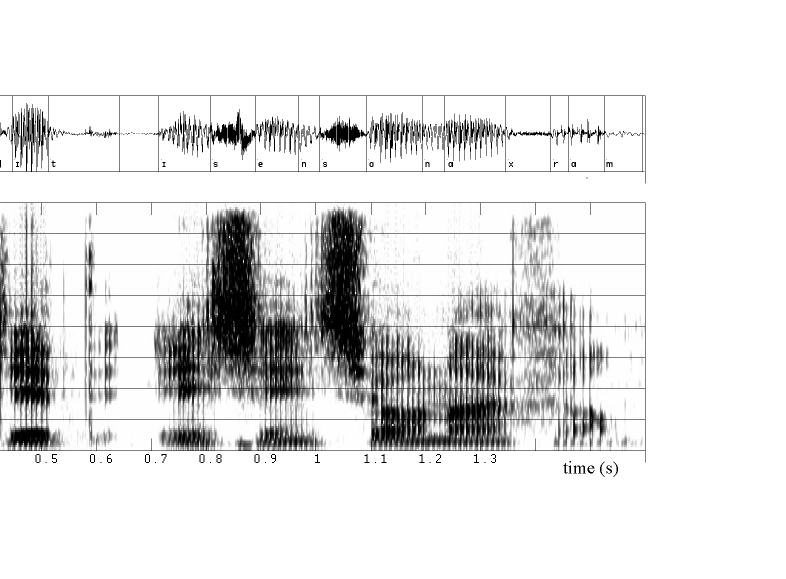
-
The vocal tract is described by its resonance frequencies.
Very useful for vowel sounds, which have the excitation at
the far end of the tube. The resonances are often termed formants. Two
such formants suffice to uniquely identify a vowel.
Below: Figure showing vowel sounds
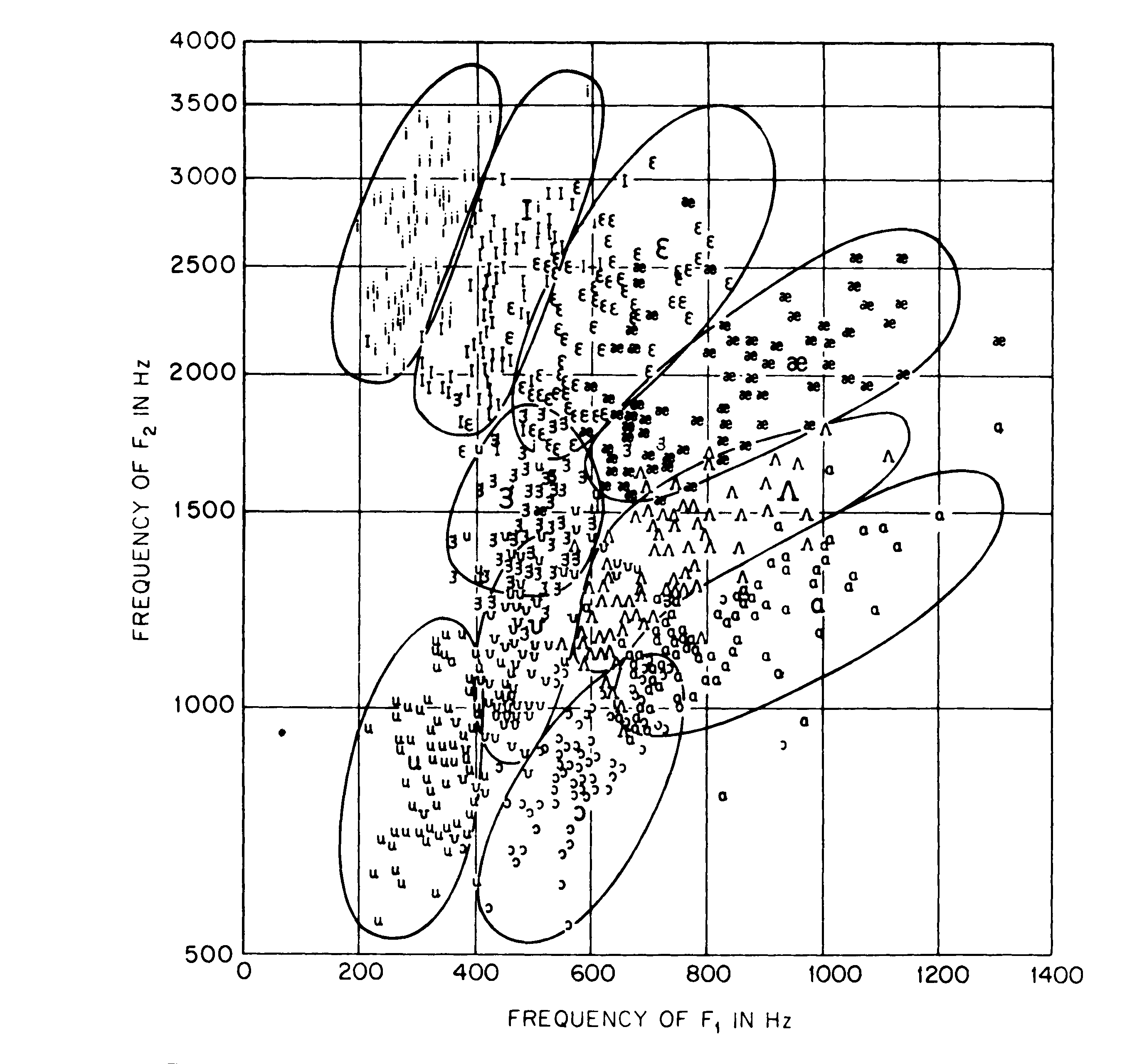
Speech and natural
language interfaces
-
Hopes: make interaction with machines
resemble interaction with people.
-
But: conversing with CPU as with
a friend neither technologically feasible nor always desirable
-
Yet : speech and natural language
technologies are practical and useful - often recognition and understanding
not required (eg. voice mail, voice, and annotation)
-
Speech is far more effective when coupled with other modalities
of interaction such as gestures
Designers must worry about:
-
Faster to speak than write
-
Faster to read than listen
-
But
good for input but not output
-
Spatial and temporal relationships often better articulated
with gestures and markings
-
Audio is spatially ubiquitous, while visual channel is localized
(e.g. can't see from behind, but can hear 360 degrees)
Stored Speech
-
good for computer mediated human/human interaction.
(e.g. voice mail)
store-and-forward technology - good for integrating
with other document types
-
Comparison of Voice vs. Written Annotations
- Voice: used for global, high-level comments
- Written: local, low level
- Conclusion : both kinds of annotations can be supported
simultaneously
-
Research by Levine and Ehrlich on Freestyle:
- Annotate e-documents by writing using an electronic
stylus or by voice
- Point, mark, speak simultaneously
- Have result captured for later use
- All this could be distributed via email
-
Problem with Speech files - searching and retrieving information.
-
Wordspotting research underway
Speech Synthesis
-
Standard on PCs
-
ASCII text to sound output
-
Follows set of production rules
Not context checking (so is wind pronounced wind or wynd)
-
Cheap
-
Can be used to deliver stored system messages rather than
voicemail
-
Voice quality varies based on application
-
Example: Bell Labs Text-to-Speech
System
Speech Recognition
-
Recognize spoken words
-
No idea what words mean, just words
-
To interpret send up to higher-level software
-
"Words" in speech recognition system not necessary words
- acoustic patterns looked for with acoustic template
-
Systems appear in PC for special use:
-
PC
Magazine Evaluation of Voice Recognition Software
-
Metroplex
Voice Computing: Application to Math
-
Difficulties in Speech Recognition:
-
Speaker - dependent or - independent:
Does system need to be trained separately for each user?
-
Size of vocabulary:
State of art systems recognize up to fifty thousand words
-
Isolated words or continuous speech
-
When does one end and next begin?
-
Must separate words by gap of 350ms.
-
-
Automatic speech recognition is best treated as a problem
in Information Theory - sender and receiver
-
During human speech production some message is encoded and
transmitted through a channel that is at best partially known and that
often is noisy.
-
The recognisers task is to decode the message.
-
All existing automatic speech recognition devices
attempt to solve the problem by building probabilistic models of all relevant
messages, and to compute the likelihood that a given signal corresponds
to (the model of) each of the possible messages.
-
Messages are defined in terms of words. The way in which
words are modelled depends very much on the number of different words in
the vocabulary, and on the way in which words can be combined to form complex
messages.
-
If the number of words in the lexicon is small, it is
best to build models of full words.
-
Otherwise it is necessary to build models of the 45 or so
different speech sounds used to form all the words in a language.
Words are then modeled as sequences of sounds, or more precisely, sequences
of sound models.
-
For decoding messages, prior probability of the words
is used via a Bayesian statitical analysis.
-
We want to know p(w|X) - the probability for
the sequence of words w, given the sequence of acoustic observations
X.
-
p(X|w) can be estimated if there is a sufficient
number of tokens of the words w spoken by a relevant set of speakers.
-
If a single speaker will use the recogniser, that specific
speaker best produces the training speech. However, in practice it is
-
Information Theoretic framework speech recognition boils
down to searching the (sequence of) words that maximise the likelihood
p(X|w).
-
Big Issues:
-
Accuracy
-
Repeatability of performance
-
Vocabulary size
-
Ease of modification
-
Location of microphone
-
Complete voice control over system
-
Performance in variable conditions
-
Problems: speech vs. mouse - 18% faster than mouse,
but use of speech interfered with short-term memory
tasks.
Speaker Recognition
-
Identification of speaker from speech.
-
Two different actions - require a data base of identity codes
and voice patterns of all persons who are known to the system.
-
Speaker Identification - the machine must use a speech
utterance to determine which of the persons has spoken (or whether the
speaker was an unknown person -- and therefore probably an intruder).
-
Speaker Verification - a speaker claims to be one
of N persons in the data base of the system, and the task is to decide
whether or not that claim can be substantiated.
-
Speaker
Recognition Demo
Natural Language
Recognition
-
Natural language systems input and output ASCII text rather
than speech.
Speech understanding systems operate on phrase or pattern
matching - no deep understanding
-
Try to combine natural language with speech.
-
Need to understand:
Syntactic - grammar/structure
Prosodic - inflections, stress, pitch, timing
Pragmatic - where in discussion utterance takes
place - location, time, cultural practices, speakers, hearers, surroundings
Semantic - having to do with word meaning
Natural Language
Generation
-
Messages from computers sometimes come in form of natural
language systems - status, errors, options.
-
They are not natural language systems - they are pre-set
- they are not generated on the fly - no conversation
-
This stuff is AI problem.
Speech, Gesture
& Multimodal Interaction
-
Natural language systems are not always most natural way
to interact
-
Gestures can convey intent of utterance much more naturally
than speech or written language
Pointing is easier than trying to say what you want
-
But natural language is better for others
e.g. Put That There (Architecture Machine Group
, MIT)
- Interface consisted of a large room, one wall of which
was a back projection panel.
- Users sat in the center of the room in a chair wearing
magnetic position sensing devices on their wrists to measure hand position.
- Users interacted with objects so wall-sized map using
voice input controlled with pointing
- Graphic feedback on map and by speech - uses text-to-speech
technology
- Pronouns that and there linked to gesture
-
Taxonomy of gestures
-
Symbolic gestures - gestures within culture that have
single meaning (e.g. OK!)
-
Dietic gestures - gestures of pointing or directing
attention
-
Iconic gestures - convey information about size, shape,
or orientation
-
Pantomimic gestures - showing use of movement of some
invisible tool.
-
Only first gesture can be interpreted within further context
-
See also: Put
That Where? Voice and Gesture at the Graphics Interface by
Mark Billinghurst
Applications
Most work on voice-based interfaces focuses on telephony
Non-speech Audio
-
Audio messages from computer systems fall into:
-
Alarms and warning systems (Dominate video games)
-
Status and monitoring indicators
-
Encoded messages and data
-
To make audio cues more effective user must know meaning
of each
Learning and Remembering
-
Assist users in remembering non-speech audio by using metaphors
- sounds on CPU have similar meaning to real world.
e.g.:
Reverberation clunk with empty space. When file saved,
the amount of reverberation would provide clue as to how much free space
on disk
Musical and Everyday Listening
Two approaches to non-speech audio:
-
Musical listening - "message" is derived from relationships
among acoustical components of sound such as pitch, timing, and timbre
-
Everyday listening - what one hears is not the acoustical
attributes of sound but source of sound
e.g. hearing a door slam - pay attention to fact it was
a door
For auditory design, based on musical listening we
have equivalents to typography, layout, and color:
Pitch - bases for melody - 96 different pitches
in western musical system.
Rhythm - change in timing and attack - most prominent
characteristic.
Tempo - speed of events
Dynamics - relative loudness - e.g., crescendo
could be used to give the idea of zooming a window.
Timbre - spectral content over time (e.g. sax
vs. flute)
Location - where sound originates
e.g. musical themes to identify characters in Peter
and the Wolf
-
Auditory Icon (Bill Gaver)- everday sounds
mapped to computer events that are analogous to the sound that the user
might expect if the actors involved in the interaction with material tangible
objects.
e.g. Sonic Finder (1989) - drop in replacement for the
standard finder of the Apple Macintosh
| Finder
Events |
Auditory
Icons |
| Object Selection |
Hitting Sound |
| Opening Folder |
Whooshing Sound |
| Dragging |
Scraping Sound |
| Drop-In |
Noise of object Landing |
| Copying |
Pouring sound |
-
SonicFinder's strength is the way it reinforces the existing
desktop metaphor by creating an illusion that the components of the system
are tangible objects.
-
Earcon (Stephen
Brewster, U.of Glasgow) - non-verbal audio messages that are used in
the computer/user interface to provide information to the user about some
computer object, operation or interaction. Earcons are constructed from
simple building blocks called motives (See above list). Earcons
are constructed from motives. Rules for creating earcons:
Repetition: Exact restatement of a preceding motive
and its parameters.
Variation: Altering one or more of the variable
parameters from the preceding motive.
Contrast: A decided difference in the pitch and/or
rhythmic content from the preceding motive.
-
Sample
Experiments
Testing and Validation
e.g. Operating Room:
-
Staff only able to identify 10 to 15 of 26 alarms
-
Only 9 to 14 of 23 alarms identifiable in ICU
-
Result - too many alarms in critical areas and those poorly
designed
Human Factors
-
Prime Attribute - messages can be conveyed without making
use of video channel
-
Visual channel focused, audio more omni-directional
-
Some people's audio icon is other's noise
Pragmatics of using
sound on computers
Perception and Psychoacoustics
-
Psychoacoustics tells about relationship between perception
and physical properties of acoustic signal