|
CS835 - Data and Document
Representation & Processing |
|
Lecture 14 – Document Engineering |
References:
OASIS
Universal Business Language (UBL)
Document
Engineering: Analyzing and Designing the Semantics of Business Service Networks
Document Engineering for e-Business.
Why Businesses
use Documents
Documents are Everywhere
• Documents are a purposeful and
self-contained collection of information.
– Interfaces for people.
– Interfaces to business processes.
• Documents cover a spectrum of types to
suit their target audience.
• Using documents as interfaces allows
for loosely coupled business processes.
– The document (and only the document)
connects the processes.
Using
documents for exchanging business information is natural and intuitive.


Doing
business by document exchange
• Every major advance in technology has brought
a corresponding evolution in business processes and the document exchanges they
require.
• We don’t use pottery, papyrus, and
parchment anymore, and electronic versions have replaced many paper documents.
BUT
• The basic idea of document exchange has
changed very little.
Pottery
Tax Receipt 2500

|
XML
Tax Receipt 2001 CE <?xml version="1.0" ?> <!DOCTYPE < <PERIOD_DATE_FROM>01042001</PERIOD_DATE_FROM> <PERIOD_DATE_TO>30062001</PERIOD_DATE_TO> < <PAYMENT_DUE_ON>28072001</PAYMENT_DUE_ON> <EMAIL_ADDRESS>maddy.maxie@practiceeci.com</ <EFT_CODE>
97999 999 999 9360</EFT_CODE> <BILLER_CODE>75556</BILLER_CODE> <TAX>500</TAX> <TAX_REFUND>200</TAX_REFUND> < </ |
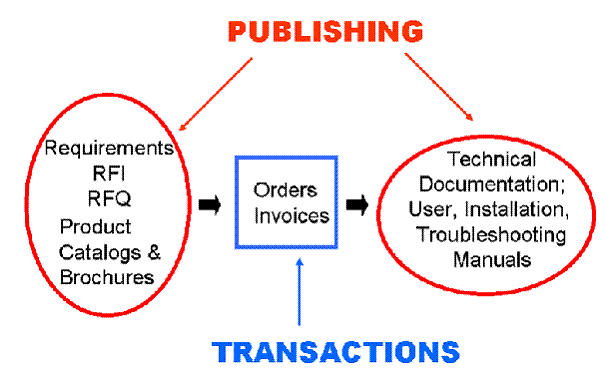
Document Exchange
• Document exchange is the mother of all
business patterns.
• Business model patterns:
– marketplace, auction, supply chain, build to order, drop
shipment, vendor managed inventory, etc.
• Business process patterns:
– procurement, payment, shipment, reconciliation, etc.
• Document patterns:
– catalog, purchase order, invoice, etc.
• Some new business models are
only document exchanges.
Motivating "Document
Engineering"
Scenario:
1. Customer selects book from catalog on an
online bookstore
2. Customer pays with credit card
3. Book arrives via express shipper two days
later
4. From the customer's perspective there is
only one "transaction"
5. But the bookstore is a virtual enterprise that
follows the drop shipment pattern to coordinate the activities of 4 different
service providers transacting with each other
6. This coordination - or choreography - is
carried out with document exchanges
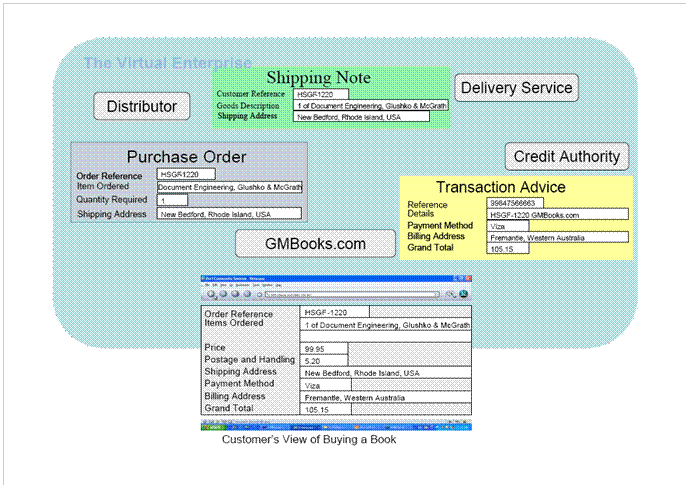
Example:
Buying a Book Online - GMBooks.com
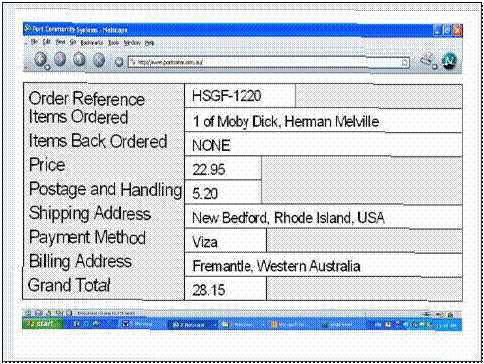
The
Real Question is “What” not “How”
• But what should these documents
contain?
• The real challenge is
understanding what the content of documents mean.
–We call this
“interoperability”
• Technologies for Web Services don’t
address interoperability - They ignore it.
Interoperability
• A basic requirement for two businesses
to conduct business is that their business systems interoperate.
– The meaning
of the information exchanged is understood as intended.
• This has always been true, regardless of
the technology used.
• Interoperability requires:
– that parties can exchange information and use the
information they exchange.
– that the information being exchanged is conceptually
equivalent.
• Easy to express but hard to achieve.
– Variations
in strategies, technology platforms, legacy applications, business processes,
and terminology.
– Different “contexts of use”
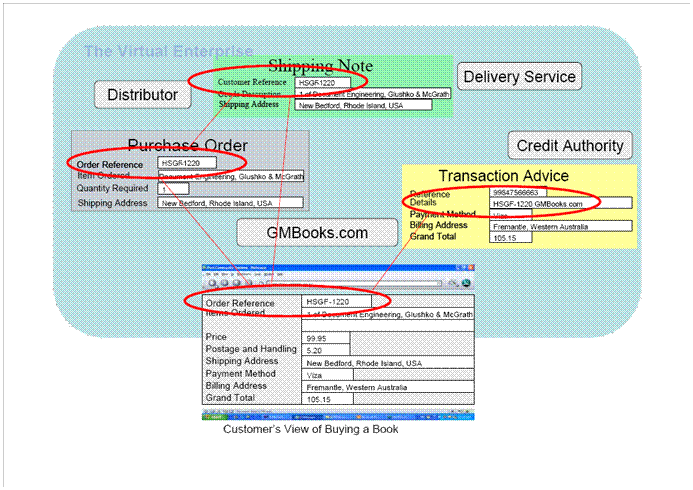
Approaches to Interoperability
• Interoperability doesn’t require that
business systems be identical.
• There are two alternatives:
1. Build
expensive customized tightly coupled solutions,
or
2. Engineer
equivalent conceptual models.
What Do We Mean by a Conceptual Model?
• Simplified description of a subject:
– abstracts from its complexity.
– emphasizes
some features or characteristics.
– intentionally de-emphasizes others.
• Remove the features for implementation
technology and focus on meaning.
– Not “how”
but “what” (again!)
• Note: an XML schema is a “physical”
model
– Describes
the XML expression of documents that share a common information model.
– Limited by the technology.
Problems with Modeling Documents
• The names of components are only a
small part of their semantic definition:
– XML is not
self-describing.
– modellers will often choose different
names for the same component.
• Different document samples can lead to
incompatible models.
• All model expressions have
technological limitations – XML schemas cannot do everything.
• How do we solve this challenge?
Def: Document Engineering
• An approach to modeling the document
exchanges between enterprises as a means of customizing them for particular
industries or domains (contexts of use).
• Comprised of a set of analysis and
design techniques that yield meaningful models of document exchanges.
• Encourages re-use of common patterns
for models.
• Synthesizes ideas from:
– business process analysis.
– task analysis.
– document analysis.
˗˗ data analysis.
Encouraging the use of Patterns
·
Patterns
are models that are sufficiently general, adaptable, and worthy of imitation
that we can use them over and over again.
·
Document
exchanges for businesses follow common patterns.
·
Using
patterns ensures applications and services are robust but adaptable when
technology or business conditions change (as they inevitably will).
·
Business
model or organizational patterns:
marketplace, auction, supply chain, build to order, drop shipment, vendor
managed inventory, etc.
·
Business
process patterns:
procurement, payment, shipment, reconciliation, etc.
·
Business
information patterns:
catalog, purchase order, invoice, etc. and the components they contain for
party, time, location, measurement, etc.
Patterns
Promote Interoperability
·
Interoperability
requires all members of a trading community to understand the documents.
·
This
is facilitated when their syntax and semantics conform to common
patterns.
·
XML
has become the preferred syntax for representing information in
documents.
·
Now
we need to define common patterns for the semantics of business
documents using XML syntax - a “universal” business language
The Model Matrix
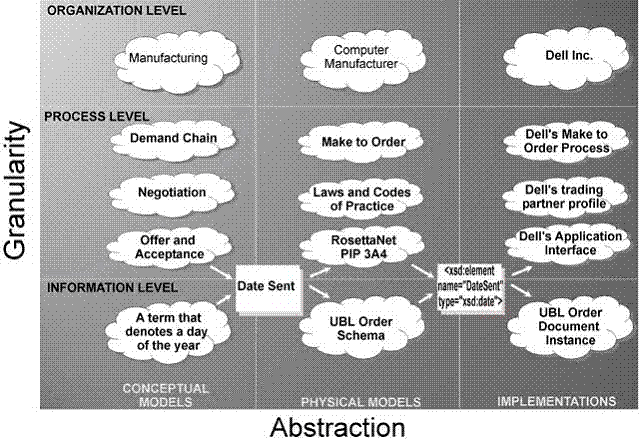
The "Pattern Compass"
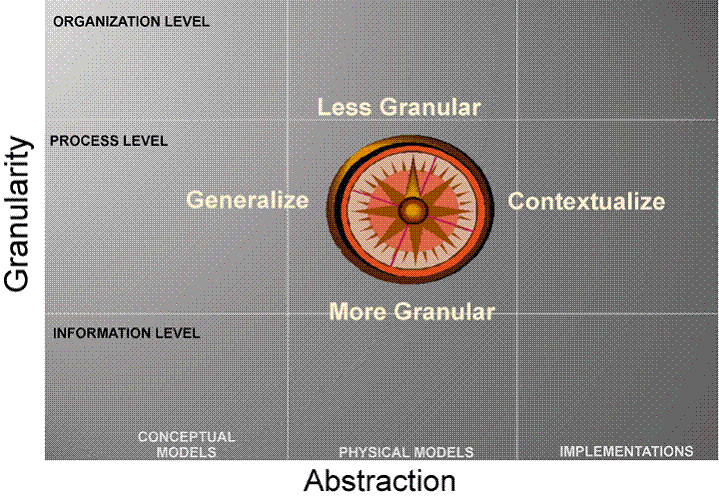
Patterns in Document Engineering
·
The
essence of Document Engineering is its systematic approach for discovering and exploiting
the relationships between patterns of different types
·
Working
from the top down to ensure that a business model is feasible
·
Working
from the bottom up to ensure that we are designing and optimizing the
activities that add the most value
·
We
need models of the desired business processes and the documents that they will
produce and consume at the same level of detail and implementability
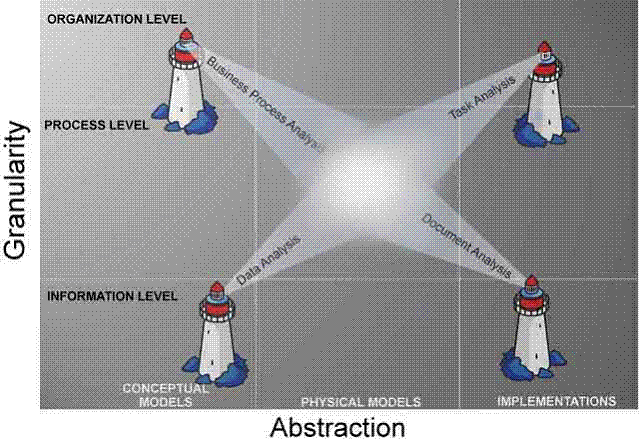
Meeting in the Middle
·
Need
to achieve both business and technical interoperability – the former is
necessary but insufficient for the latter
·
Need
models of:
1. the desired business processes
2. the documents that they will produce and
consume at the same level of detail and implementability
·
This
is represented in the Model Matrix as "meeting in the middle"
·
Document
Engineering is a systematic approach for "getting to the middle"
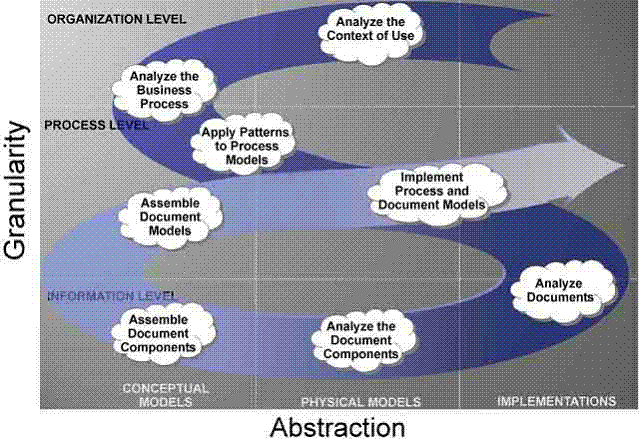
The Document Engineering Approach
A Checklist for Describing Projects and Case Studies
·
D --
data types and document types
·
O --
organizational processes
·
C --
context (types of products or services, industry, geography, regulatory
considerations)
·
U --
user types and special user requirements
·
M --
models, patterns, or standards that apply
·
E --
enterprises and ecosystems (e.g., trading communities, standards bodies)
·
N --
the needs (business case) driving the enterprise(s)
·
T --
technology constraints and opportunities
Modeling Documents {and,vs,or} Modeling Processes
·
Documents
are always the result of some process and often the input to another one
·
This
is most evident for transactional documents where patterns of paired document
exchange are the building blocks for supply chains, marketplaces, auctions and
other business patterns
·
By
understanding the information in the documents, we learn what kinds of
processes are possible
·
By understanding
the processes, we learn what kinds of information are needed
A Process-Centric Depiction
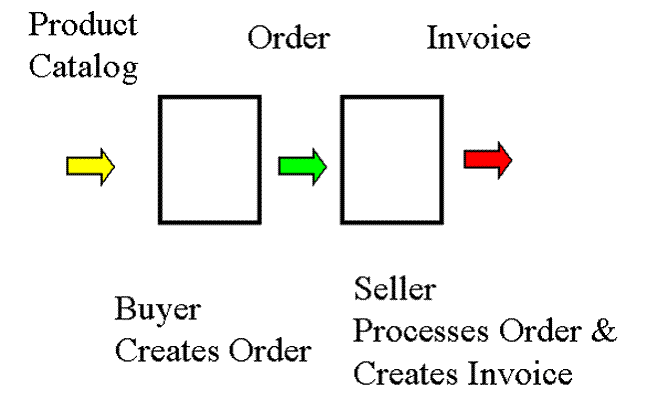
A Document-Centric Depiction
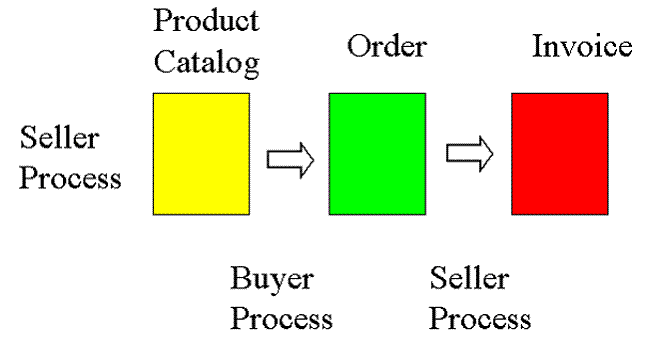
Benefits of a Document-Centric
Modeling Approach
·
Documents
are more tangible than processes, easier to analyze and communicate
·
SOA
emphasizes documents as the public interfaces to private processes
·
David
Cohn: 100,000 nouns enable us to understand the meanings of 10,000 verbs
The Equivalence Problem
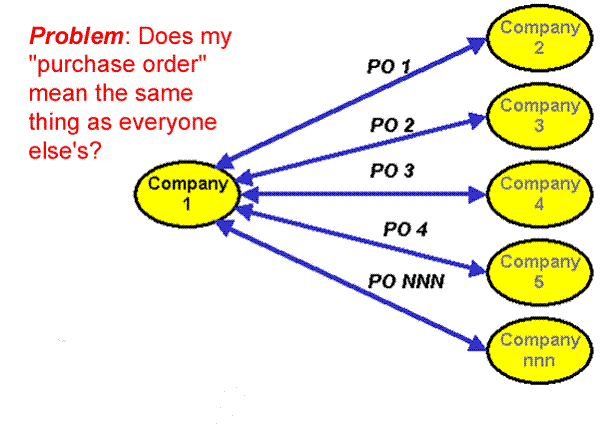
The Target Model For
The Interoperability Scenarios
Validation Does Not Imply
Interoperability
·
Cases
where interoperability may or may not be possible because the conceptual or
implementation models differ
·
Suppose
the document validates against the recipient's schema
o
The
semantics can still be different in important ways (the ID
o
The
recipient may not be able to validate all of the business rules that are
important
o Good argument for industry standards /
reference models / in your conceptual models or using XML vocabularies that
represent them in authoritative ways
METHODS FOR MODELING COMPONENTS
Documents vs. Data
·
Many
people have contrasted "documents" and "data" and concluded
that documents and data cannot be understood and handled with the same
terminology, techniques, and tools.
·
This
document vs. data distinction is embedded and reinforced in XML textbooks,
technology, and product marketing
·
And it
doesn't always help
Mixing Data and Documents
Data or
Document?

The
Document Type Spectrum

Crossing the Chasm with Document
Engineering
·
Document
Engineering harmonizes the terminology and emphasizes what they have in common
rather than highlighting their differences:
·
Identifying
the presentational, content, and structural components
·
Identifying
and organizing the "good" content components
·
Assembling
hierarchical document models to organize components to meet requirements for a
specific context for information exchange
Three Types of Information in
Documents
·
We
need a vocabulary to classify different kinds of information that we find in
documents and sets of data
·
Content
– "what does it
mean" information
·
Structure
– "where is it"
or "how it is organized or assembled" information
·
Presentation
– "how does it
look" or "how is it displayed" information
·
The amount
and relationships among these three kinds of information varies in different
kinds of
documents
Presentation Information
·
Human-oriented
attributes for visual (or other sensory) differentiation (type font, type size,
color, background, indentation, pitch, ...)
·
Good
user interface design correlates this with structural or content information
·
May be
concealing structural or content information
Presentation View of a Lecture Slide
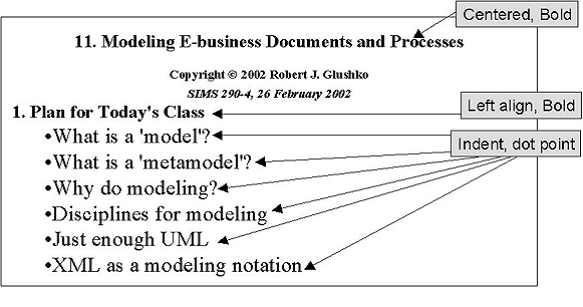
Analyzing Presentation Components
·
Presentation
affects structure and content by applying transformation rules to them
·
To
understand the structure and content we must identify and record these rules
·
Some
transform rules are explicit
·
Some
transform rules are implicit or ambiguous or misleading
Structural Information
·
Physical
piece of a document (e.g. table, section, title, header, footer)
·
Frequently
a close relationship between structural and presentation items, especially in a
paper document. This goes some way to explaining why the document-centric
school places such strong emphasis on structural components.
·
Embody
the rules on how content components fit together, often hierarchical
·
Often
driven by context of document use (e.g. overseas address vs. local address)
Structural View of a Lecture Slide
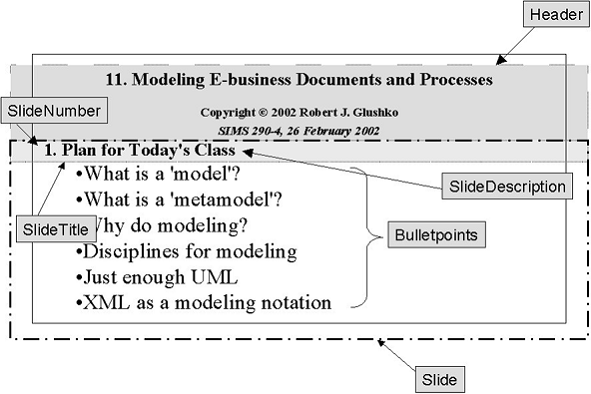
Analyzing Structural Components
·
The
structural components provide the hierarchical "skeleton" or
"scaffold" into which the content components are arranged
·
Structural
components are often identified by the names attached to pieces of information
– think of the outline or table of contents or lists of various kinds
·
Metadata
to capture
o
Depth
of hierarchy
o
Sub-structures
included within a structural container
o Rules for applying numbers or names to
content in the hierarchy
Content Components
·
Content
components are the "nouns" in documents or sets of data – things like
"topic," "summary," "name," "address,"
"price"
·
In
publications a lot of the content isn't easily identified by "component
type" – it may be "just text" that could be playing any of a
very large number of roles in the document
·
Sometimes
you get no help from the set of style or formatting tags in word processors or
in HTML, which are very format or structure oriented and not content oriented
at all
·
Need
XML so we can invent the vocabulary of tags needed to describe component
content in a specific document type
Relationships Among
Content Components
Content components can be related to one
another
·
Derivational
relationships
·
Referential
relationships
Analyzing Content Components
·
What attributes
about each type of content should we record in our analysis?
·
Names/synonyms/homonyms
(what it is called)
·
Definition
(what it "means")
·
Roles
(what it does)
·
Cardinality/Optionality (occurrence rules)
·
Restricted
values, code sets, defaults
·
Data
Type (text, numbers, date, video)
·
Relationships/Associations
·
Origin
(Is this new information, or from some other source? Who maintains it?)
·
Access
(who is allowed to view/change/copy/etc. it)
·
Context
(is this information "general purpose" or "core" or is its use
limited to specific contexts?)
·
Permanence
(is it static or dynamic? how often does it change?)
Content View of a Lecture Slide
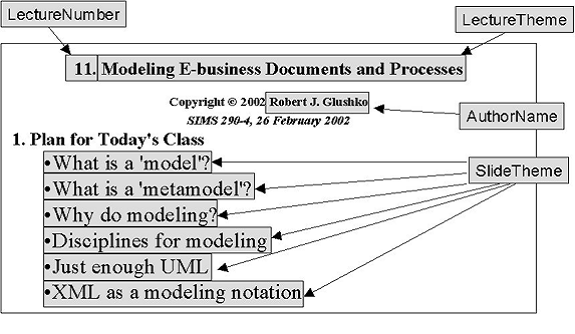
Harvesting and Consolidation
·
Harvesting
– Create a set of
candidate content components by extracting them from the information sources
while removing presentation and structure
·
Consolidation– Identify synonyms and homonyms among the
candidate content components, assigning a unique name to each unique meaning as
part of a controlled vocabulary
Table of Content Components

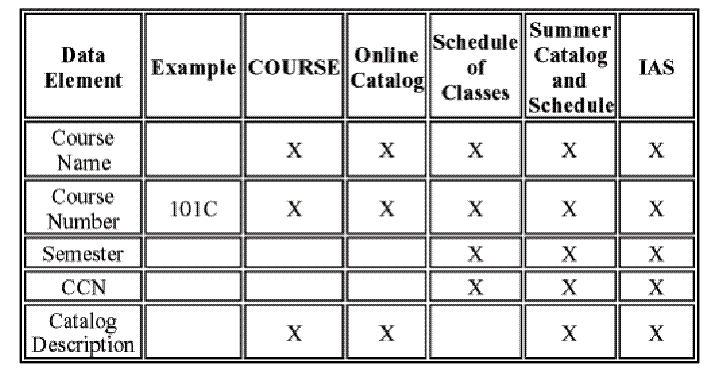
Consolidating the Harvest
·
Can
begin consolidation with the candidate components from any of the information
sources, but we recommend using the one you believe is the most authoritative
or that yielded the most components
·
The goal
is to combine components that are synonyms (different names for the same
meaning) and to distinguish any homonyms (same names for different meanings)
·
It is
desirable for a set of components to enable one and only one way to describe
something because duplication or redundancy implies choices that could lead to
inconsistent models and non-interoperable schemas
Example Consolidation Table --
Courses
Motivating Aggregate Components
·
Atomic
components that hold
individual pieces of information Especially in transactional documents, where
atomic components have a natural representation as primitive data types
("string," "Boolean," "date") or as data types
that are derived from these by restriction
·
Document
components that assemble
smaller components into the set of information needed to carry out a
self-contained purposeful activity
o Especially in transactional contexts, where
documents have a natural correspondence to some unit of work that initiates,
records, or responds to a clearly-defined event
·
Aggregate
components are composed of
atomic ones and are reused in the assembly of document components
o
They
are easier to identify in transactional contexts because they are often the key
information that flows from one document to another
o
"Address"
or "Person" are obvious examples of aggregates composed of smaller
ones
o
Two
key questions:
§
How do
we select and group atomic components into aggregates?
§
How
many aggregates should we create?
Identifying Two Kinds of Component
Aggregates
·
Structural Aggregates -- sets of components defined by
parent-child or containment relationships
·
Conceptual Aggregates -- sets of components that "go
together" because of logical dependency
Identifying Aggregate Components in
Non-Transactional Documents
·
Aggregates
are more elusive on the narrative end of the DTS because there are limits to
the rigor with which components can be grouped
·
"Mixed
content" models arise when there are few or weak constraints on where
atomic components can appear
·
Presentation
often masks the atomic components in potential aggregates
·
Structures
are often based on conventions for organization and presentation than on
semantic relationships
·
But
there will still generally be components that "go together" to form
reusable structures
·
And
"going together" means different things for each set of components
·
Aggregates
can be created in two "bottom-up" ways that focus on the atomic
components:
o
The
first is by rebuilding or making explicit the structures that we took apart in
document analysis
o
The
second is by creating structure in "blobs" of poorly structured
information written in an overly narrative style (with mixed content at best)
o A more modular style for the information
will increase its regularity and reusability; it will eliminate content that
has little value to users and reinforce its use as "boilerplate" or
via links
Normalization
·
Normalization– Applying techniques for reducing
redundancy and increasing integrity in information models
o
The
consolidated list of unique candidate components is equivalent to 1NF in
relational theory
o
Data
normalization techniques can be applied to further refine the set of candidate
components (if used sensibly)
o Components that are functionally
independent of each other are separated and their bi-directional relationships
are recorded
The Component Model
·
Primitive
and aggregate components
·
Used
heuristic or formal means (or both)
·
The
methods used and the results reflect the mixture of transactional and
non-transactional documents in our context
o
Number
of components
o
Size
of components
o Precision of rules for data types,
associations, cardinality
The Component Model is a Set of
Relations
Representations of Normalized Models
- UML Class Diagram
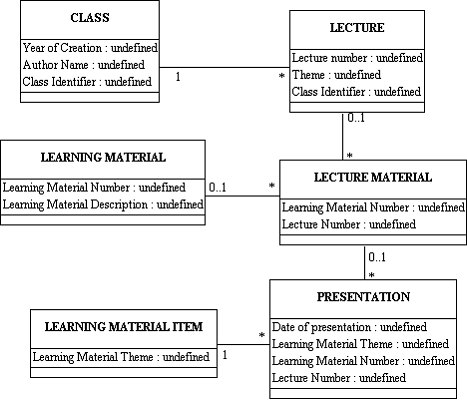
METHODS FOR MODELING DOCUMENTS
Why We Need Hierarchical Document
Models
·
A
relational model simultaneously describes all of the associations among the
components - it doesn't highlight any particular association
·
But
when we exchange information, we do so to satisfy the requirements in some
context
·
If
there are multiple ways to interpret the content we will not achieve
interoperability
·
Hierarchies
(tree structures) provide unambiguous structures
·
So we
impose a contextual interpretation when we create a hierarchy on a relational
model
Multiple Paths through the Component
Network
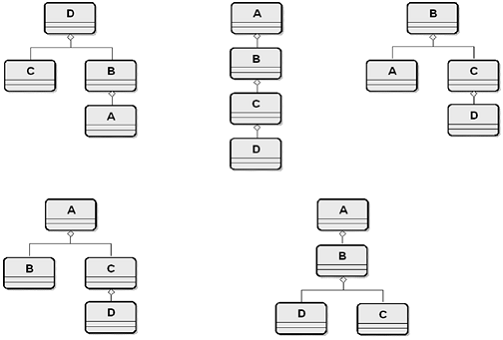
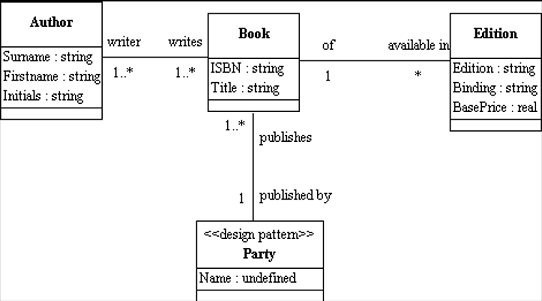
Simple Example -- Book / Author /
Edition / Publisher
e.g Hierarchical Interpretation of the
"Book" Model (other hierarchies possible)

Document Model Assembly
·
Document
model assembly is the process of creating a model of a document type –
hierarchical and nested – by drawing on the "pool" or library of
content and structural components
·
Assembly
involves designing (or selecting a pattern for) the top level structure as an
entry point and then navigating through the relationships in the conceptual
model collecting the components in the order that best satisfies your
requirements
·
Assembly
order can differ whenever there is a bi-directional relationship between
components – whenever two components are functionally independent, an assembly
order chooses one of the relationships to enforce an interpretation on the
assembled document
·
The
direction of following the relationship determines which of the structural
roles is being used
·
End up
with a specific context-sensitive view of the model
·
This
is the logical basis of the document schema – all we have left to do is to
encode it as an XML schema
The Universal Business Language
·
International,
royalty-free library of electronic business documents patterns.
·
Piloted
many of the ideas for Document Engineering.
·
Designed
in an open and accountable vendor neutral OASIS Technical Committee.
·
Fills
the “payload” slot in B2B web services frameworks
Document Model Assembly and the
Document Type Spectrum
·
The
basic problem of assembly is the same for all types of documents but the
solution is different at different points on the spectrum
·
Non-transactional
/ narrative / publication type documents usually have fewer content-based
rules, but their assembly is often shaped by structural or presentation rules
Document Model Assembly –
Transactional Document Types
·
Since
transactional documents and data-intensive contexts tend to have more rules,
their component models are more complex and there are more alternative document
assembly models
·
These
alternate assembly models may differ in which information from the instance
they present (they may be queries or views of the instance rather than a
one-to-one rendering) and in the order or structure with which they present it.
·
If the
sequence is important it should be a component in the model and assembled in
our logical documents (e.g. SequenceNumber in our
Lecture Notes example)
The Rules of Assembly
The rules represented in the component model
must be followed during any document model assembly:
·
Mandatory
associations must be followed
·
Mandatory
components must be included
·
Optional
associations are followed if they meet the requirements for the context.
·
Optional
components are included if they meet the requirements for the context.
·
Even
if one role is the usual or canonical interpretation, it may not be a
requirement for the context of this specific document assembly
Assembly Order and Containership
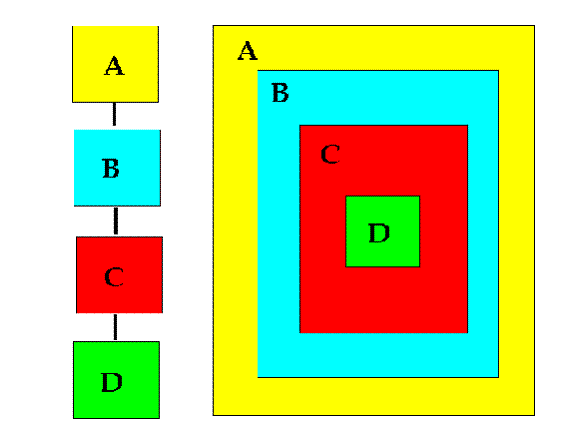
·
The
structural depth of the document model is determined by how many associations
in the component model are followed
·
The
order in which associations are followed determines the nesting or container
structure in the model
Document Model Assembly -
Non-transactional Document Types
·
Requirements
for structural or presentation integrity may be more important than content
constraints
·
There
are conventional assembly patterns for many types of documents (perhaps these
can be viewed as default requirements) (Maler and el Andaloussi call this the "shape" of the document
type)
·
Some
document types seem naturally "flat" – just 2-level deep "list
of things" documents
·
Sometimes
documents can be arbitrarily deep with chapter, section, subsection, etc
divisions but from a component type perspective this is a simple recursive
structure with few or no content distinctions
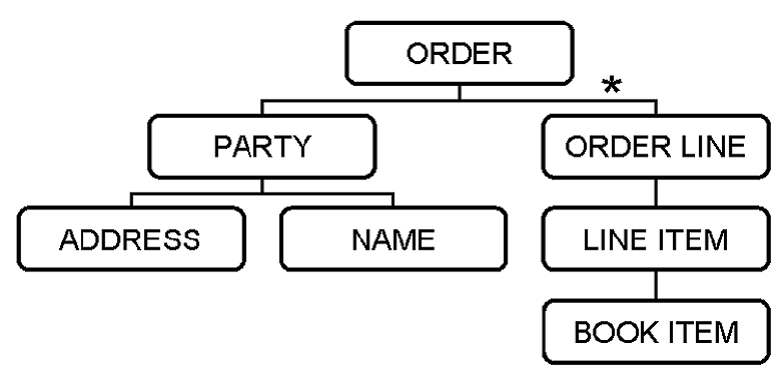
A Common Document Assembly Pattern
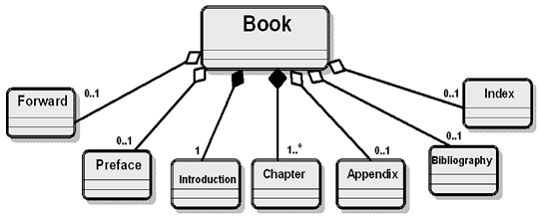
UBL
is a business vocabulary for XML
HTTP + HTML
= Web Publishing
ebXML/WS + UBL = Web Commerce
Example
of a UBL Conceptual Model
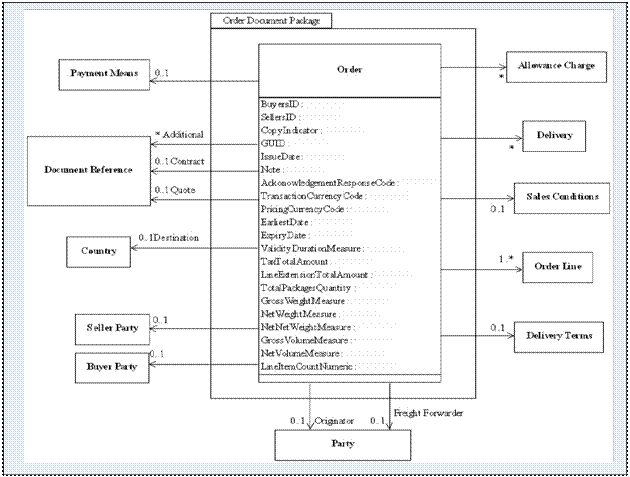
Example
of a UBL schema
|
<xsd:element
name="Order" type="OrderType"/> <xsd:complexType
name="OrderType"> <xsd:sequence> <xsd:element name="BuyersID"
type="udt:IdentifierType" minOccurs="0" maxOccurs="1"/> <xsd:element name="SellersID"
type="udt:IdentifierType" minOccurs="0" maxOccurs="1"/> <xsd:element ref="cbc:IssueDate"
minOccurs="1" maxOccurs="1"/> <xsd:element ref="cbc:Note"
minOccurs="0" maxOccurs="1"/> <xsd:element ref="EarliestDate"
minOccurs="0" maxOccurs="1"/> <xsd:element ref="cbc:ExpiryDate"
minOccurs="0" maxOccurs="1"/> <xsd:element ref="ValidityDurationMeasure"
minOccurs="0" maxOccurs="1"/> <xsd:element ref="cbc:TaxTotalAmount"
minOccurs="0" maxOccurs="1"/> <xsd:element ref="cbc:LineExtensionTotalAmount"
minOccurs="0" maxOccurs="1"/> <xsd:element ref="TotalPackagesQuantity"
minOccurs="0" maxOccurs="1"/> <xsd:element ref="cac:BuyerParty"
minOccurs="1" maxOccurs="1"/> <xsd:element ref="cac:SellerParty"
minOccurs="1" maxOccurs="1"/> <xsd:element ref="OriginatorParty"
minOccurs="0" maxOccurs="1"/> <xsd:element ref="FreightForwarderParty"
minOccurs="0" maxOccurs="1"/> <xsd:element ref="cac:Delivery"
minOccurs="0" maxOccurs="unbounded"/> <xsd:element ref="cac:DeliveryTerms"
minOccurs="0" maxOccurs="1"/> <xsd:element ref="cac:SalesConditions"
minOccurs="0" maxOccurs="1"/> <xsd:element ref="DestinationCountry"
minOccurs="0" maxOccurs="1"/> <xsd:element ref="cac:OrderLine"
minOccurs="1" maxOccurs="unbounded"/> <xsd:element ref="cac:PaymentMeans"
minOccurs="0" maxOccurs="1"/> </xsd:sequence> </xsd:complexType> |
Example
of a UBL Document
|
<BuyersID>20031234-1</BuyersID> <cbc:IssueDate>2003-01-23</cbc:IssueDate> <cbc:LineExtensionTotalAmount
amountCurrencyCodeListVersionID="0.3" amountCurrencyID="USD">438.50</cbc:LineExtensionTotalAmount> <cac:BuyerParty> <cac:Party> <cac:PartyName> <cbc:Name>Bills
Microdevices</cbc:Name> </cac:PartyName> <cac:Address> <cbc:StreetName>Spring
St</cbc:StreetName> <cbc:BuildingNumber>413</cbc:BuildingNumber> <cbc:CityName> <cbc:PostalZone>60123</cbc:PostalZone> <cac:CountrySubentityCode>IL</cac:CountrySubentityCode> </cac:Address> <cac:Contact> <cbc:Name>George
Tirebiter</cbc:Name> </cac:Contact> </cac:Party> </cac:BuyerParty> |
Example
of a UBL Implementation
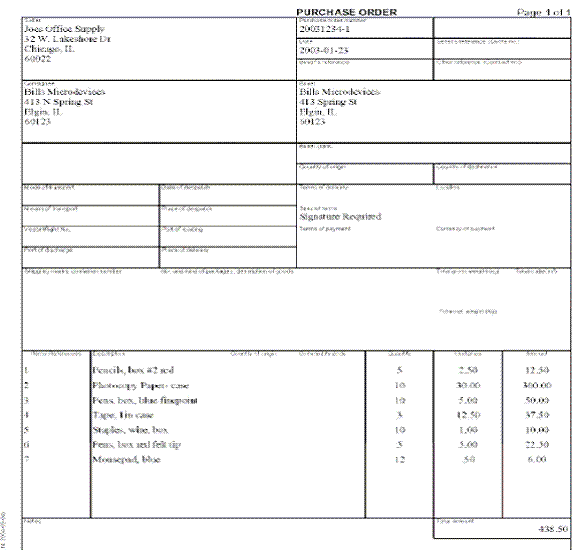
UBL 1.0
·
Released
·
Basic
Procurement Business Process Model
·
Order
to Invoice
·
XML
Schemas (W3C XSD)
·
Order
to Invoice Documents
·
Re-usable
Common Component Library
·
XML
(XSD) Naming and Design Rules
·
Guidelines
for schema customization.
·
Pattern
library of conceptual models.
·
Forms
Presentations and sample documents
·
Download
at : http://www.oasis-open.org/committees/ubl
Recent UBL Developments
• UBL
International Data Dictionary:
– 600
elements translated into Chinese (Simplified and Traditional), Japanese,
Korean, and Spanish.
• UBL Naming
and Design Rules (NDR)
– adopted by
chemical industry (CIDX), petroleum (PIDX), agriculture (RAPID), real estate
(OSCRE/PISCES), U.S. Department of the Navy (
• UBL Invoice
used by the Danish Govt.
– February to
April 2005, more than one million invoices exchanged.
– Estimated
savings 94 million Euro annually.
• UBL Invoice
used by the Swedish Govt.
– Announced
September 2005.
• Small
Business Subset
– Simple implementation guide for SMEs.
Work Plan for UBL 2.0
• Extended
library.
– Extended Procurement Process (
– Transportation Process Documents (
– Electronic Catalogue process (
• Improved
library.
– Improve architecture.
– Better document engineering.
• Aligning
with UN/CEFACT projects.
Core Component Type library.
UN/eDocs.
• Release
early 2006.
Summary
• The basic idea of document exchange
has changed very little.
• Using documents as interfaces allows
for loosely coupled business processes.
• Some new business models are only
document exchanges.
• The real challenge is
understanding what the content of documents mean.
• Interoperability requires that parties
can exchange information and use the information they exchange.
• The best way to support
interoperability is to engineer equivalent conceptual models.
• Document Engineering comprises of a
set of analysis and design techniques that yield meaningful models of document
exchanges.
• Document exchanges for businesses
follow common patterns.
• Interoperability requires all members
of a trading community to understand common patterns of document syntax and
semantics.
• The Universal Business Language is an
international, royalty free library of electronic business documents patterns