CS835 - Data
and Document Representation & Processing
|
|
Lecture 3 – Hypermedia I |
V. Balasubramanian http://www.e-papyrus.com/hypertext_review/chapter1.html
HYPERTEXT
Hypertext:
·
an approach to
information management in which data is stored in a network of nodes connected
by links
o Nodes can contain text, graphics, audio, video, source code, or other forms of data
o Linking capability allows a nonlinear organization of
text.
·
It is a
representation scheme, a kind of semantic network, which mixes informal textual
material with more formal and mechanized processes.
·
It is an
interface modality that features link icons or markers that can be arbitrarily
embedded with the contents and can be used for navigational purposes
Advantages
- Ease of
tracing links
- Ease of creating new references
- Information structuring
- Global views
- Customised documents
- Modularity of information
- Consistency of information
- Task stacking
- Collaboration
Disadvantages
- Risk of
disorientation while navigating the information space is one of the major
usability problems with hypertext systems.
- Cognitive
overhead is another problem with hypertext systems.
- May be
difficult for group members to become accustomed to the additional mental
overhead required to create and keep track of links.
- In general: the additional effort and concentration necessary to maintain several tasks or trails at one time may be experienced as a burden.
History
1965 – Ted Nelson –
invented the term "hypertext" (non-linear text)
·
defined as a body of written or pictorial material
interconnected in a complex way so that it could not be conveniently
represented on paper.
·
Could contain:
o
summaries or maps of its contents and their
interrelations;
o
annotations,
additions and footnotes
1945 - Vannevar Bush - realized that an era of
information was approaching. (As We May Think PDF
)
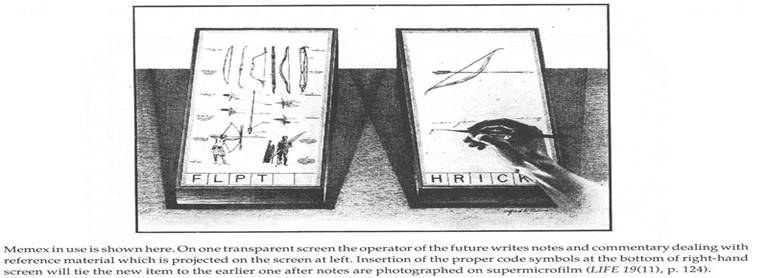
He designed Memex:
·
A memex is a device in which an individual stores all
his books, records, and communications, and which is mechanized so that it may
be consulted with exceeding speed and flexibility. It is an enlarged intimate
supplement to his memory.
·
It
is conceptual machine that could store vast amounts of information, in which a
user had the ability to create information "trails": links of related
text and illustrations.
·
This trail could then be stored and used for future
reference.
·
The Memex would store information on microfilm kept on
the user's desk.
·
The desk would contain many translucent screens on
which several microfilms could be projected for convenient reading.
·
The would be a keyboard and sets of buttons and
levers.
·
The Memex would have a scanner for user input of new
material and it would also allow users to make handwritten marginal notes and
comments.
·
Memex supported:
o
Conventional form of indexing
o
Associative indexing - any item may be caused at will
to select immediately and automatically another.
o
Essential feature of memex -The process of tying two
items together

Memex animation: http://www.dynamicdiagrams.com/case_studies/mit_memex.html
Nodes and Links
A hypertext system is made of nodes (concepts) and links
(relationships).
- A node
usually represents a single concept or idea.
- It can
contain text, graphics, animation, audio, video, images or programs.
- It can be
typed (such as detail, proposition, collection, summary, observation,
issue) thereby carrying semantic information
- Nodes are
connected to other nodes by links.
- The node from
which a link originates is called the reference
- The node at
which a link ends is called the referent.
- Links connect
related concepts or nodes.
- They can be
bidirectional thus facilitating backward traversals.
- Links can
also be typed (such as specification link, elaboration link, membership
link, opposition link and others) specifying the nature of relationship
- Links can be
either referential (for cross-referencing purposes) or hierarchical
(showing parent-child relationships).
Basic Features of a
Hypertext System
1.
Graphical User Interface, with the help of browsers
and overview diagrams, helps the user to navigate through large amounts of
information by activating links and reading the contents of nodes.
2.
Authoring system with tools to create and
manage nodes (of multiple media) and links.
3.
Information retrieval mechanisms such as keyword searches,
author searches etc.
4.
Hypermedia engine to manage information about
nodes and links.
5.
Storage system that can be a file system or
a knowledge base or a relational database management system or an
object-oriented database management system.
Early Hypertext
Systems
Augment/NLS – 1968 -PDF
- Doug Engelbart of SRI developed a system
called NLS (oN Line System) with hypertext-like features.
- Used to store
all research papers, memos, and reports in a shared workspace that could
be cross-referenced with each other
- Demonstrated
NLS as a collaborative system among people spread geographically.
http://www.treelight.com/software/collaboration/NLS_video.html
http://sloan.stanford.edu/mousesite/1968Demo.html
Xanadu – 1965 - PDF
- 1960 -
developed the idea of "nonsequential writing" - text as a
non-linear entity.
·
Xanadu isTed Nelson’s life’s work – 40 years and
counting
·
His vision of a "docuverse" (document
universe) where "everything should be available to everyone.
o
Any user should be able to follow origins and links of
material across boundaries of documents, servers, networks, and individual
implementations.
o
There should be a unified environment available to
everyone providing access to this whole space."
- Xanadu - a
repository publishing system "intended to store a body of writings as
an interconnected whole, with linkages, and to provide instantaneous
access to any writings within that body."
- This system
has no concept of deletion - a write-once system.
- Once
something is published, it is for the entire world to see forever.
- As links are
created, the original document remains the same except for the fact that
a newer version is created which would have references to the original
version(s).
- Since
conventional file systems are not adequate to implement such a system,
Project Xanadu has focused its attention on the re-design and
re-implementation of file systems.
http://www.iath.virginia.edu/elab/hfl0155.html
Intermedia - 1986
- Developed at
- Integrated
environment that allows different types of applications (word processors,
editors, and other programs) to be linked together
- Collection of
tools for authors to link together the contents of text, timeline,
graphics, 3-D models and video documents over a network of high-powered
workstations
- Intermedia
includes:
·
a text editor
(InterText),
·
a graphics editor (InterDraw),
·
a scanned image viewer (InterPix),
·
a three-dimensional object viewer (InterSpect),
·
a timeline editor (InterVal).
- Hypermedia
functionality of the system is integrated into each application so that
the creation and traversal of links can be intermixed with the creation
and editing of documents.
- The system
provides consistent, modeless, direct-manipulation applications. Strict
conformance to user interface standards throughout the system makes it
easy for the user to interact with all the applications in a similar
manner.
- Intermedia
supports the concept of webs, composite entities that have many nodes and
links between them.
·
A link can belong to one or more webs.
- Supports
shared and concurrent access to documents based on a system of access
permissions.
http://www.iath.virginia.edu/elab/hfl0032.html
NoteCards - 1987
- Framework - a
semantic network composed of notecards connected by typed links.
- Has tools for
displaying, modifying, manipulating, and navigating through the network.
- four basic
constructs: notecards, links, browsers, and fileboxes.
- Notecards
contain information embedded in text, graphics, images, voice or other
media.
- Links
represent binary relationships between cards.
- Browsers
display node-link diagrams of portions of the network.
- Fileboxes
provide a mechanism to organize cards into topics or categories.
- NoteCards can
be integrated with other systems running in the Lisp environment such as
mail systems, databases, and expert systems.
KMS - 1988
- Knowledge
Management System (KMS), a descendant of ZOG, developed at
- Designed to
manage large hypertext networks across local area networks.
- Based on the
basic unit called the frame.
·
A frame can contain text, graphics, or images.
·
Frames are connected to other frames via links.
- Links:
- tree items
to represent hierarchical relationships
- annotation
items to represent referential relationships.
- No
distinction between browsing and authoring modes.
·
Users can make changes to a frame or create links at
any time and these changes are saved automatically
- Used for
collaborative work, electronic publishing, project management, technical
manuals and electronic mail.
HyperTies - 1988
- HyperTies
started as TIES (The Interactive Encyclopedia System) under the direction
of Ben Shneiderman at the
- Authoring and
browsing tools.
- A node may
contain an entire article that may consist of several pages.
- Links:
·
highlighted words or
·
embedded menus
·
activated using the keyboard or a touchscreen.
- Readers can
preview links before traversing.
- Simple user
interface designed for museum information systems or kiosks.
- Commercial
version used for applications in diagnostic problem solving, self-help
manuals, browsers for libraries, and on-line help

Guide
- Developed by
Peter Brown as a research project at the University of Canterbury, U.K.
- Commercially
marketed by Office Workstations
- IBM PC and
Apple Macintosh.
- Most popular
commercial hypertext system.
- Text and
graphics integrated together into articles or documents.
- Guide
supports four different kinds of links: replacement buttons, note buttons,
reference buttons, and command buttons.
- Navigation
through the replacement buttons initially provides a summary of the
information and the degree of detail can be changed by the reader.
- Similar to
KMS, Guide also does not distinguish between the author and the reader
Textnet
- Textnet was
designed and implemented by Trigg at the
- Developed to
support on-line scientific community in text creation, footnoting,
annotating and critiquing.
- Based on a
semantic network of nodes and labeled links.
- Nodes either:
·
primitive
pieces of text called chunks or
·
composite hierarchies called table of contents (tocs).
- Links:
·
Basic:
·
normal links
·
commentary links.
·
Eighty different types of links with different
functions
Writing Environment (WE)
- Researchers at
the
- Model
explains:
·
·
Writing - reverse process: A loosely structured network
of internal ideas and external sources is first organized into an appropriate
hierarchy or outline which is then translated into a linear stream of words,
sentences, paragraphs, sections, and chapters
- WE was
designed to support the process of writing.
- Contains two
major view windows:
- graphical - allows the user to loosely structure
their ideas in terms of nodes.
- hierarchical
along with commands.
- As some
conceptual structure begins to emerge, the writer can transfer the nodes
into the hierarchy window which has specialized commands for tree
operations.
- Relational database
used for storaging nodes and links in the network.
- Other
windows: an editor window, a query window, and a window to control system
modes and the current working set of nodes.
- WE can be
used both as a hypertext system as well as an authoring system with
advanced graphical, direct manipulation structure editing capabilities
IMPLEMENTATION
ISSUES
Conversion of Text to
Hypertext
·
Logical conversions - manual hypertexts:
·
Encyclopedias
·
Dictionaries
·
Training manuals
·
Reference materials are highly cross-referenced and
are used in a non-linear fashion.
·
Readers look for structural cues;
·
Table of contents
·
Indexing by subject
·
Keywords
·
Authors
·
Page numbers
·
Sections
·
See-also listings
Limitations of Printed Text
Limitations imposed by the printed versions of reference books:
·
Amount of information that can be stored limited
compared to electronic forms of storage.
·
Difficult to search through large volumes of printed
material
·
Difficult to updated periodically
·
Search is predominantly lexical - the table of
contents and the index provide the facility to jump to topics
o
amount of cross-referencing is minimal.
o
Printed index is limited by the size and selection
criteria of the authors and does not always direct the user to all relevant
information.
·
Information cannot be dynamically re-arranged to suit
the individual needs of various kinds of users.
·
Information is spread over a number of volumes and
after some time information retrieval becomes tedious.
Advantages of Hypertext
Format
1.
Hypertext form can support good browsing capability.
2.
Electronic media can store large amounts of
information.
3.
Provides better visual prominence and more rapid
navigation through huge number of entries
4.
Most users would like to:
a.
save their results and queries for future use
b.
use annotation facilities
c.
transfer text segments to other documents
d.
have tools to sort and filter quotation
e.
have tools for statistical analysis of variables.
Conversion Issues
1.
Identifying documents that would benefit readers if
converted to hypertext form.
2.
Determining procedures to convert them to hypertext
format.
3.
Preparing documents in an electronic format from paper
or other forms.
4.
Identifying nodes and links and classifying them into
various types (to capture semantics).
Fragmentation
problem - difficult
to identify text units that can be separate modules and also serve as
cross-references for other entries.
·
Links
should follow some model of the user's need for information in some particular
context.
·
Granularity is a difficult problem:
i.
Too fine the granularity, greater the problem of
fragmentation.
ii.
Too coarse the granularity, greater the need or the
display of large entries.
·
Fragmentation tends to make an implicit structure
explicit, taking away the expressiveness of the statement.
5.
Determining the target of a link as a complete entry,
a sub entry, or a derivative form is a challenging task
6.
Computer monitors - the display of large entries in
their entirety is still a problem
·
Partly solved
by having fisheye views and abbreviations.
·
Structural information can be extracted from the tags
and employed in the construction of a structural view.
7.
Performing the conversion and verifying the results.
Types of Conversion
Two ways to convert existing documents into hypertext form - manual conversion and automated
conversion
Manual Conversion
- Uses a
hypertext authoring tool to create nodes and links manually.
- Depends on
the way the author understands the structure and flow of the presented
material
- Repetitive
process - prone to error.
- Manual
conversion suitable only for small documents.
Automated Conversion
- Facilitates
identification of nodes and links based on pre-defined criteria
- Output of an
automated conversion process can be modified/enhanced by authors
- Large
information spaces such as dictionaries, encyclopedias, and training
manuals can be converted to hypertext format efficiently
- Most linear
documents have structural elements :
titles, sub-titles, chapters, sections, paragraphs, sentences, words,
figures, tables, and indexes.
- Automated
conversion system must be able to:
- recognize
these structural elements
- identify
nodes and links
- construct
the appropriate links to form the hypertext network
- Links can
capture both the hierarchical and referential nature of the material.
Guidelines for Conversion
1.
Use care to identify text units as nodes that can be
separate modules and still be sufficient enough to be cross-references for
other entries.
2.
Design rule - choose as the basic unit of text the
smallest logical structure with a unique name (such as the title for an entry)
3.
Pages or paragraphs are less suited as hypertext units
because they do not form convenient handles for manipulation.
4.
Must understand both the explicit and implicit link
structures in the printed version of the material.
5.
Must understand the user's task and to support links
that follow some model of the user's need for information in some particular
context.
6.
Organization should be open and flexible.
7.
Different kinds of views should be available for
different users.
e.g.
repair manual can contain :
training view
troubleshooting view
routine maintenance view
purchaser's view.
Automatic Link
Construction
Requires intelligence
links created based on the semantic analysis of
the underlying text
Hypertext Templates
- Hypermedia templates
are sets of pre-linked documents that can be duplicated
- Templates
automate the process of creating hypermedia collections by creating the
"skeletons" of documents and linking them.
Requirements for a hypertext system to provide
templates:
1.
Provide generic operations to create, duplicate, edit
or delete a template.
2.
Facilities to add contents to empty documents and
links, to display an overview of the template, to access a template by its
type, by author, or by creation date.
3.
Operations to displayan overview of the template, to
zoom into specific link sets or webs or sub graphs and look at the contents of
documents.
4.
Specify formats and screen layouts for a template and
to add help.
5.
Choices to manipulate the contents of documents within
a template such as editing, deleting, creating new links etc.
e.g. Intermedia
1.
Facility to create templates including the documents
and links that make up the template.
2.
Documents within the same template can be linked.
3.
User can specify the folder or directory under which
each document is created and also the folder where the template has to be
duplicated.
4.
User can find out which template was used to make a
new hypermedia collection.
5.
The original template itself is write-protected so
that users do not edit it accidentally.
General Guidelines for
Authoring Hypertext Documents
A document should consist of the three components - the content part, the organizational
part, and the presentation part
The Content
Part
·
Nodes and links are design objects.
·
Properties (semantics) can be associated with these
design objects in order to introduce coherence in a hypertext document.
·
Content contain information
·
Content links connect content nodes based on semantic
relationships
·
Content nodes can be either atomic or composite.
·
Content links can be typed specifying the exact nature
of the semantic relationship.
- Level One: Links with
no labels.
- Level Two: Links with
labels describing global semantic relationships such as "is discussed
by", "is illustrated by".
- Level Three: Links with
more specific labels such as "is criticized by", "is shown
graphically".
Design rule:
- Composite
content nodes should be used to hierarchically structure the content of
the document into domain specific sub-units of information.
2. The label of a link should be as
specific as possible and should constitute a comprehensible sentence together
with the names of the source and destination nodes.
The
Organizational Part
·
Design objects of the organizational part increase coherence
by structuring the network under a reader-oriented perspective.
·
Structure nodes organize content nodes and
links in a specific manner.
·
Each structure node has a name and a starting
node.
- Sequencing
nodes that allow the author to define the reading sequence through the
content net.
- Exploration
nodes allow the reader to explore - the reader can simply follow the
content links to explore the subnet.
·
Structure nodes can be connected by structure links
which are also classified into two types:
- Sequencing
links associate the content of each sequencing node with a presentation
sequence.
Can be used to define ordering such as linear
sequence, branching sequence etc.
- Exploration
links provide access to exploration nodes.
An exploration link is embedded into a sequencing
node and points to the beginning of an exploration node.
·
Sequencing nodes and sequencing links can present
different presentation sequences such as sequential paths, branching paths, and
conditional paths.
Design rules:
- Choose an
appropriate starting point to serve as an introduction to the document.
- Construct
appropriate paths based on reader's interests and knowledge.
The
Presentation Part
The actual display of structure and content and provide the means of
navigation.
Three styles:
- Textual Style: There is no
graphical display of the structure, the presentation being limited to the
display of the content of one or more nodes.
- Graphical
Style: There is a graphical display, such as an overview map, of the
structure.
- Combined
Style: Both overviews and the ability to open nodes are provided.
Dynamic Hypertext
- No static
links exist in a Web page
- Links are
created "on the fly"
- Dynamic links
are created based on the content of the Web site and the interests of the
user.
- Links could
lead to other Web pages in the Web site or can be used to further a user's
search.
- Can be used
to present conventional text databases as a set of interconnected Web
pages, and to merge them with other information on the Web (e.g.,
conventional static hypertext pages).
- For a further
discussion of dynamic hypertext
- Golovchinsky, G. (1997). Queries? Links?
Is there a difference? In Proceedings of CHI'97,
- Golovchinsky,
G. (1997). What the query told the link: the integration of hypertext and
information retrieval. In Proceedings of Hypertext'97,
- e.g. Basic
concept of dynamic hypertext was implemented in the DynaWeb system
- (Bodner, R.,
Chignell, M., and Tam, T. (Nov., 1997) Website authoring using dynamic
hypertext, Proceedings of WebNet'97, pp.59-64.

- Intended to
be used to present large textual databases as Web pages.
- System
interacts with the INQUERY search engine to retrieve relevant document(s)
in response to a query.
- The titles of
the most relevant documents (e.g., the top ten) are presented
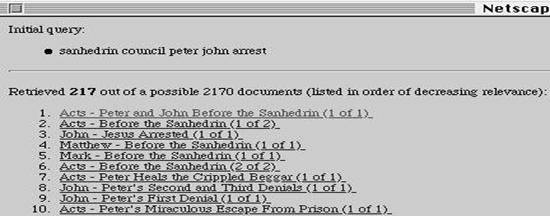
- When the
person selects a document, the document is presented to the person with
hyperlinks which were created "on the fly"
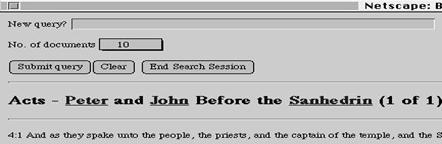
- Selection of
words used as links is based on previous links (i.e., queries) the person
selected.
- The system
also keeps track of the previous queries.
Linearization of Hypertext
·
Reverse problem - linearize a hypertext document for
printing.
·
Printing a branching hypertext document in a linear
fashion poses both technical and conceptual problems
·
Easy to linearize a hypertext document having a strict
hierarchical structure by performing a depth-first tree traversal
o
print the first chapter and its sections and move onto
the next chapter and so on
·
General case - hypertext document is a highly connected
network without any special order - difficult to produce a good linear document
e.g. Lotus SmarText Electronic Document Construction Set
- Automates the
creation and browsing of large hypertext document
- Presents
multiple views of non-linear text in a linear fashion
- SmarText
readers can choose to traverse one path out of many possible paths
- A path is
essentially a linear presentation of specific nodes connected by specific
links
- The text, the
index and outlines are constrained by the selected view or path
DATABASE ISSUES
Introduction
- Large class
of applications for which relational database management systems (RDBMS)
are too limited.
- Characterized
as complex, large-scale, data-intensive programs such as CAD/CAM systems,
documentation management systems, hypermedia systems, and geographical
information systems.
- Require a
database model that is more expressive and flexible than the relational
model.
- Object-Oriented
Data Base Management Systems (OODBMS) for hypermedia applications
developed
Object-Oriented Concepts
and Hypermedia
- Simple nodes
can be compared to atomic objects representing primitive data types such
as integer, character, string, video frame and bitmap.
- Objects or
nodes can be accessed using object identifiers or node identifiers.
- A link can be
represented by a set of at least two object identifiers. Links can also be
treated as objects with their own identifiers (link identifiers) which can
be used to separate index information from content.
- A composite
node in hypertext (made of webs of nodes and links) can be treated as a
composite object or an aggregation of simple objects.
- The concepts
of data abstraction and encapsulation can be applied by defining methods
to create, delete, update and manipulate nodes and links, to traverse links,
and to trigger events.
- Nodes and
links can be grouped under different classes based on structural and
behavioral patterns (semantics). Organizing nodes and links semantically
helps manage the network better, eliminates ambiguity, clearly differentiating
the purposes of these objects.
- Nodes and
links of a particular class can also inherit properties from related
superclasses. This feature can be used in the creation and management of
hypermedia templates - when a user changes a parent template, these
changes can be propagated to all its sub-classed templates.
- Whenever the
properties of nodes and links have to be changed it should be easy to do
so through schema evolution.
- Other
object-oriented concepts that are pertinent to hypertext include
concurrency control, versioning, and persistence.
e.g. HyperBase PDF
- basic class -
HB_Object
- three
subclasses:
- HB_Node - HB_Objects
with content and history
- HB_Link - HB_Object
that connects two existing HB_Objects
- HB_Composite_Object
- collection of references to existing HB_Objects
- Generic
operations of create, modify, copy, delete, retrieve an object (part of or
whole) were supported for nodes, links, composite objects, and attributes.
Requirements for Hypermedia Systems
a. Openness and Distribution
·
Open
hypermedia system can connect to other information systems (both hypertext and
non-hypertext).
·
Distribution allows the system to store at
geographically dispersed sites in a manner transparent to the user.
b. Support for collaborative work or sharing
·
Includes:
o
simultaneous multi-user access to the hypermedia
network
o
robust concurrency control mechanisms
o
broadcasting to users any changes made to the network
by other users
o
tracking contributions made by each member of a team
c. Data integrity/Correctness
·
Database layer should preserve data integrity and
provide traditional secondary storage management and data administration
facilities.
·
Should support either the notion of rules as in
extended relational databases or the concept of semantics as in object-oriented
databases.
d. Dynamism
·
Must be able to
dynamically reconfigure the network in response to changes made to the network
or its contents.
e. Search and query mechanism
·
Should provide efficient search and query mechanisms.
·
Allow two kinds of queries –
o
a structure query to retrieve a part of the network
o
a content query to retrieve a specific node.
f. Computation
g. Composites
- Must deal
with groups of nodes and links
- Requires
making a composite node as a primitive construct in the basic hypermedia
model
h. Versioning
- Versioning is
required in order to keep track of changes to the network.
- Must include
versioning at the level of individual entities such as nodes and links and
also at the level of the hypermedia network as a whole.
i. Multimedia Support
- The database
layer should be able to efficiently store and retrieve multiple media.
- Should also
provide transparent access to different storage media.
j. Extensibility and Tailorability
Ability to handle extensions to the existing data model (schema
evolution) in a flexible and safe manner
- The database
layer should be able to handle:
- the
structural part of the hypertext data model
- the semantic
part to ensure data abstraction and encapsulation of the evolving data
model.
USER INTERFACE ISSUES
Disorientation
·
"Getting lost in space" arises from the need
to know where one is in the network, where one came from, and how to get to
another place in the network.
·
Traditional text - not easy to get lost
o
Cues:
§
table of contents of topics with page numbers
§
index with keywords
§
page numbers
§
bookmarks.
·
Complex hypertext network - thousands of nodes and
links - more likely reader will get
lost.
Cognitive Overhead
§
For authors : Additional mental overhead on authors to
create, name, and keep track of nodes and links
§
For readers : Overhead due to making decisions as to
which links to follow and which to abandon, given a large number of choices.
Designs for Navigation
Graphical Browsers
§
Graphical browsers - overview displays for large
bodies of information
§
Reduce disorientation by providing a spatial display
of the hypertext network
§
Provide an idea about the size of the network
e.g. gIBIS - MCC
Software Technology Program - PDF
·
Users can scroll through the entire network as well as
rearrange the nodes
·
Provides facilities to view the contents of the
browser at different levels of detail.
·
User can zoom in to see any portion of the browser in
detail
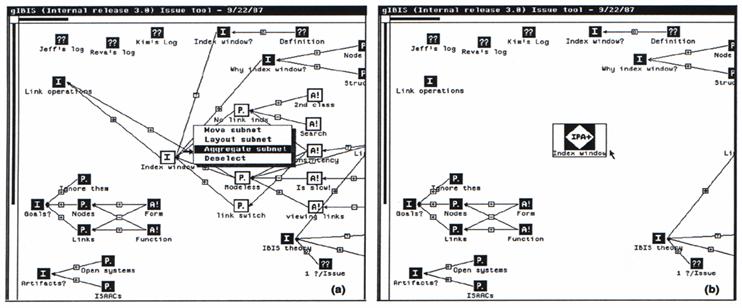
Maps and Overview
Diagrams
·
Maps serve to improve spatial context in a hypertext network.
e.g. Intermedia - a map is a local tracking
map that displays all the documents or nodes linked to the current document
which is dynamically updated.
·
Global overview diagrams provide an overall picture of
all nodes and links in
a document
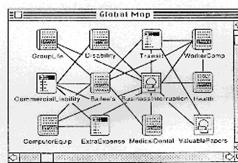
·
Serve as anchors for local overview diagrams.
·
Local overview diagrams show the local context of the actual node
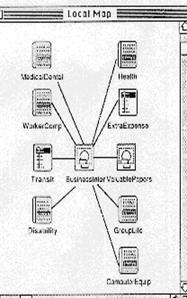
Paths and Trails
·
A path can allows authors to determine an appropriate
order of presentation for a given audience.
·
Reduces both disorientation and cognitive overhead
since users will follow a pre-defined path which will also narrow down their
choices.
o
first enunciated by Bush in "As We May
Think".
In Intermedia, a path is a list of
documents users visited earlier in a browsing session.
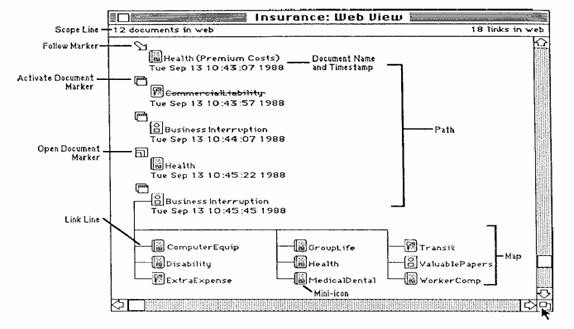
·
Intermedia Web View – path display
·
The display of a path consists of :
o
the name of the document
o
an icon indicating the type of event (opening or
activating documents)
o
a timestamp indicating when the event occurred.
·
A user's path is saved when closing the web and
restored when opening the web, the next time.
·
A path can be used to collect all interesting
documents to form a linear document that can be preserved in printed form
·
Scripted Documents System, XEROX, uses paths which are
procedural and programmable
·
The items in the path (nodes) can be
"active" entries or scripts which can do computations, execute
programs etc.
·
The entries provide the content while the path
provides sequencing
·
Paths can be created and edited using path editors.
·
Readers can get local and global views of relevant
paths.
·
Playback mechanisms are supported which allow users to
play back a path either single-stepped or automatic.
·
Different kinds of scripts provide different paths and
can be used to create presentations for different classes of audiences

o
Multimedia
document contains photos, formatted text, and voice annotations
- Several scripts traverse
the document to show members of various projects and play back their voice
descriptions of themselves
- The user has just
clicked the Scripts button in the document header, which has created a
menu of scripts that start in this document.
- Script entries are shown
as boxes around text.
Guided Tours
o
A guided tour is a system-controlled navigational
tool that can be entered and exited at the user's will
o
Progress can be monitored using maps or overviews of
the hypertext database
o
Paths are typically associated with the idea of a
guided tour, where the author determines an appropriate order of presentation
for a given audience
o
Guided tour may even include annotations explaining
the items on the path
o
e.g., Trigg extended this concept to NoteCards and
called stops along the tour tabletops.
o
Tabletops consist of sets of cards and annotations
arranged on the screen in a particular layout.
o
A guided tour is a graphical interface to a network or
path of tabletop cards, connected by links
o
A tabletop is a snapshot of cards currently on
display, including their positions, shapes, scrolled locations of their
contents and any overlapping.
o
A reader can:
o
start a guided tour
o
traverse a path of tabletops in sequence
o
jump arbitrarily to any tabletop
o
go back and forth between tabletops
o
reset the state of the guided tour.
Backtracking,
History Lists, Timestamps, and Footprints
o
Backtracking allows visiting previously reviewed nodes
o
Path-following principle - preferred method - traverse
in reverse order those nodes that were previously visited
o
Backtracking mechanisms must fulfill two requirements
–
o
should always be available
o
should always be activated in the same way
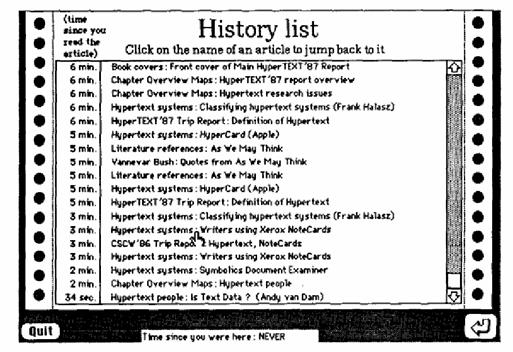
e.g. NoteCards
o Maintains an
ordered list of each notecard that was examined in a particular session
o Users select an item
from the list and look through a browser
o Nodes that have
already been visited in a session are marked with a plus sign, one for each
time visited
o Visual indicators
such as the plus sign or checkmarks or asterisks serve as
"footprints" on overview diagrams and help users to avoid returning
to nodes that have been recently visited.
o A variation of the
history list called the history tree shows the users "how" they
traversed a set of linked nodes, the digressions, and multiple visits to nodes.
e.g. NoteCard’s
history tree
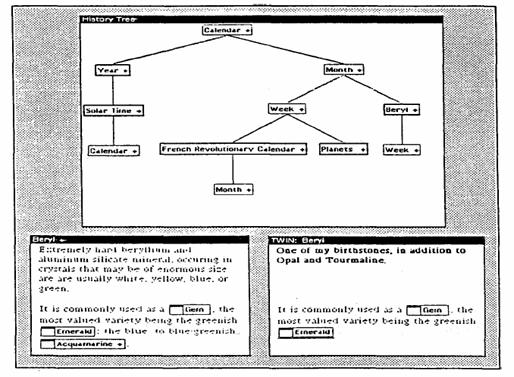
o Both the history
list and history tree can be saved and annotated with text and graphics
o
HyperCard has a graphical history list called the
recent list which has miniature snap-shots of the last forty-two nodes visited.
o
Clicking on a miniature brings that card to the
display.
o Nodes that are
visited can be timestamped (along with the accumulated time spent at each node)
and maintained in a chronological order
Arbitrary Jumps,
Landmarks, and Bookmarks
o
Arbitrary jumps enable users to go to any node in the
system
o
Bookmark is similar to a history list except a
bookmark is placed by the reader.
Embedded Menus
o
Embedded menus allow the user to select an item
embedded within the node
o
Embedded menus are a better way of indexing for
hypertext systems because they highlight semantic relationships over physical
relationships.
Fisheye Views and
Spiders
o
Fisheye view algorithm which is similar to looking at
a scene with a wide angle lens - things of greater interest will be at the
center, while items of lesser interest will be on the periphery. PDF
e.g. Fisheye
Calender

o
Algorithm generates an image of the neighborhood by
computing a relationship between a priori importance of a node and the
distance between that node and the current position in the hypertext network
o
Hypertext as a directed graph with semantics
o
Nodes do not
contain text.
o
Pieces of text are connected to the nodes by text
links
o
nodes are connected to each other by labeled value
links
o
text can contain embedded links, called lexical links,
to other nodes.
o
Directed Graph Browsers
o
e.g.
o
"Spiders" - directed graph browser in
Thoth-II
o
Global map is created dynamically as a user browses
through linked nodes
o
Activating a node expands it showing links to other
nodes which themselves fan out to other nodes.
o
Structure can be moved around to view parts that fall
outside the viewing area.
o
Viewing modes:
·
Browsing mode - user browses through the graph,
manipulates nodes and links
·
Text mode - user views the textual pieces attached to
the nodes.
o
Hyperbolic Space
o
3D Hyperbolic Space Browser - http://graphics.stanford.edu/papers/webviz/htmlnosplit/
H3: Laying Out Large Directed Graphs in 3D http://graphics.stanford.edu/papers/h3/html.nosplit/
Link structure of a Web site laid out in 3D
hyperbolic space
Roam and Zoom
Techniques
·
Hypertext navigation is restricted by the physical
limitations of the display screen
·
Readability affected when the contents of a node do
not fit into one screen
·
Larger displays partially solve problem
·
Scroll bars allow two-dimensional navigation - not
easy to focus on a particular region of interest.
·
Solution – roam and zoom
o
Entire information space shown in miniature within a
map window occupying a small part of the display
o
Wire-frame box or rectangle inside the window shows
the portion of the information space displayed on the main display
o
Main display is the viewport into the information space.
o
Map window provides a clear sense of location within
the information space
o
Size of the wire-frame can be changed using the mouse
thereby zooming in and out of the region
o
Wire-frame box can be dragged around the map window
thus roaming around the information space.
Usability and Evaluation
of Hypertext
1.
Adequacy of the content and the interface
Usefulness of
hypertext depends on its purpose, ease of navigation, and the population domain
2.
Acceptability to readers
Is the hardware/software
system designed to meet the user’s needs?
3.
Adaptability by readers for the task in hand
Must be
appropriate to the tasks that the users are trying to accomplish
4.
Skills of the readers as information users
System should
extend the range of cognitive activities that readers will engage in
5.
Costs of production and dissemination
INFORMATION
RETRIEVAL ISSUES
·
Navigation or browsing is effective for small
hypertext systems
·
Large hypertext databases requires information retrieval
(IR) through queries
Query and Search Mechanisms
Conventional IR
systems:
·
keyword based automatic searching (in conjunction with
Boolean operations)
·
weighting of words based on their statistical
properties
·
ranking of documents according to probability of
relevance
·
automatic relevance feedback for query modification
and query languages
Query and search
mechanisms can be classified into content search and structure search
·
Content search - standard IR technique extended to
hypertext systems
o
all nodes and links are treated independently and
examined for a match to the given query
·
Structure search - will yield the hypertext
sub-network that matches a given pattern
Query facilities
which combine aspects of both content search and structure search are capable
of acting as filters
·
Based on the user's query, the interface will display
only those nodes and links that match the query.
·
Filtered browsers have been implemented both for
NoteCards and Tektronix's Neptune.
o
In NoteCards, a user can filter out information based
on the node or link type.
o
In
§
if query is broad enough, a global view of the entire
network is displayed
§
if query is well refined, the viewing size will be
manageable.
Content Queries and Indexes
- Two-level
architecture for hypertext documents:
- Top level -
hyperindex (containing index information)
set of indexes linked together
- Bottom level
- hyperbase (containing content nodes and links).
·
When an index term describing the required information
is found the objects from the underlying hyperbase are retrieved for
examination
·
Navigating through the hyperindex (not the hyperbase)
and retrieving information from the hyperbase is called "Query By
Navigation".
Effectiveness of
index expressions in the hyperindex include:
1.
Precision: The ratio of relevant
objects associated with the descriptor to the total number of objects
associated with the descriptor.
2.
Recall: The ratio of the number of
objects associated with the descriptor to the total number of relevant objects.
3.
Exhaustivity: The degree to which the
contents of the objects are reflected in the index expressions.
4.
Power: The ratio of a descriptor's specificity to its
length.
5.
Eliminability: The ability to determine
the irrelevance of a descriptor and stop the search.
6.
Clarity: The ability to grasp the
intended meaning of the descriptor.
7.
Predictability: The ability to predict
where relevant descriptors can be found in the index.
8.
Collocation: The extent to which the
relevant index terms are near each other in the index.
Structural Queries
o
A logical query language that allows structural
queries over a hypertext network
o
The basic formulae of the logic are the propositions
and assertions on attributes' values
o
Queries use specifiers to directly retrieve edges,
paths, and cycles.
o
The set of elements retrieved is collapsed into a
hypertext network.
o
The output of a query is a hypertext network that
users can incrementally compose queries.
o
The combination of specifiers, quantifiers, and the
collapsing of query answers into a new hypertext network makes it possible to
express structural queries
Cluster Hierarchies, Aggregates, and
Exceptions
o
Vector space model to organize a hypertext collection
into clustered hierarchies
o
Content of each node or document is represented by a
set of possibly weighted terms.
o
Each document is represented by a term vector
o
Complete document collection is represented by a
vector space whose dimension is equal to the number of distinct terms to
identify the documents in the collection.
o
Similar or related documents are represented by
similar multi-dimensional term vectors.
o
Model facilitates clustering documents based on their
similarity and ranking retrieved documents in decreasing order of their
similarity to the query vector.
o
Comparisons are generally made between the query
vector and the document vectors using one of the standard measures of similarity.
o
Clustering is also helpful in locating neighboring
nodes which discuss related topic(s).
o
The user can incrementally refine the query vector to
retrieve the desired document(s).
o
Object-oriented concept of abstraction
(generalization/aggregation)
o
Abstraction is the concealment of all but relevant
properties of an object or concept.
§
Aggregation is the clustering of related
objects to form a higher level object.
§
Generalization is the property of treating
a set of similar objects as a generic object.
o
Used to simplify hypertext structures
o
A set of related nodes and the links between them can
be treated as a semantic cluster having the following properties:
1.
They form a subgraph of the hypertext graph.
2.
The compactness (the degree of interconnectedness of
the hypertext) of the subgraph is higher than the compactness of the whole
graph.
o
Graph theoretical algorithms such as biconnected
components and strongly connected components can be applied in the formation of
such clusters or aggregates.
o
Artificial Intelligence Techniques
o
A knowledge base and an inference engine built on top
of the hypertext database can add "intelligence" to nodes and links.
o
An interactive filter can be built which will consult
with the user and call up the appropriate node.
INTEGRATION ISSUES
Models and Frameworks
Hypertext Abstract Machine (HAM)
o
One of the first approaches to a generic hypertext
implementation model was the Hypertext Abstract Machine (HAM)
o
A general purpose, transaction-based, multi-user
server for a hypertext storage system
o
HAM's emphasis was on developing an appropriate
storage model.
o
It provided a general and flexible model that could be
used in several, different hypertext applications.
o
HAM contains the following layers
o
User Interface: 
A window-based interactive environment for
applications to communicate with users.
o
Application: The actual application which
may or may not run on the same machine as the HAM.
o
Hypertext Abstract Machine: An engine which
manages all information about the hypertext and communicates with the
application through a byte stream protocol.
o
Host file system or storage system: A repository to
store all the hypertext graphs or databases.
o
HAM storage model consists of five major objects:
1.graphs (networks
of nodes and links containing one or more contexts)
2.contexts
(partitions of data within a graph)
3.nodes
4.links
5.attributes
carrying semantics.
o
Operations performed on HAM objects:
o
Create
o
Delete
o
Destroy
o
Change
o
Get
o
Filter
o
Special
o
The HAM architecture provided version control,
filtering and data security.
Link Engine/Hypermedia Engine/Link
Service
o
Intermedia - multiuser hypermedia framework whereby
hypertext functionality is handled at the system level - linking would be
available for all participating applications
o
The IRIS Hypermedia Services provided an integrated
desktop environment for hypermedia applications such as InterWord, InterDraw,
InterVal, InterVideo, and InterPlay
o
These services contain the following components:
Intermedia Layer, Link Client, and Link Server.
o
Components are independent of both operating system
and Graphical User Interface.
o
Documents are stored as Unix files while the link and
anchor data are stored in a DBMS.
o
Link Engine made up of The Link Client, the Link
Server, and the DBMS
o
Intermedia Layer - responsible for all live data
manipulation
o
Link Engine - responsible for the storage and
retrieval of link data
o
Intermedia documents could be interchanged with KMS
using the Dexter Interchange Format
o
Requirements to make hypermedia an integrated part of
the computing environment:
1.
Integration of hypermedia into the desktop.
o
Link Engine must be integrated into the computing
environment just as the file system.
o
A higher level toolkit or an application programmer
interface (API) must be provided for application developers to issue calls for
hypermedia support.
2.
Hypermedia systems must provide multiple contexts or
multiple webs in order to fully exploit hypertext linking across all
applications.
3.
Hypermedia applications must support filtering and
incremental query construction.
4.
Wide Area Hypermedia - Hypermedia functionality must
be extended to support Wide Area Networks in addition to LANs.
5.
Building an integrated hypermedia environment is made
easier with object-oriented techniques.
o
System-wide
hypermedia engine based on the notion of a generalized hypermedia using bridge
laws
o Bridge laws are translation routines provided by the
application to the hypertext interface.
o They map the elements defined in the application's
original non-hypertext data or knowledge base to entities in the hypertext
engine.
o
Engine would bind independent back-end applications
such as Decision Support Systems, Expert Systems, Databases and front-ends
(interface-oriented applications such as word processors, graphics packages)
through message-passing mechanisms.
o
Bridge laws map the objects defined in the back-end
such as models, variables, calculations to objects in the front-end such as
nodes, links, and link markers.
o
Front-end and back-end requirements for system-level
approaches to hypermedia integration or client/engine cooperation.
Front-end
Requirements:
o
Tracking the location of objects such as link markers
and providing their identifiers to the engine when a link marker is selected.
o
Must request from the engine editing permissions for
insertions, deletions, and modifications.
o
User interface must provide hypermedia prompts.
o
When the front-end saves a document with embedded
hypermedia objects, the objects should also be saved.
Back-end
Requirements:
o
Provide specific information about its structure and
its applications' documents.
o
Bridge laws must be written by developers.
o
Provide control information and interpretive
mechanisms along with the objects that are sent through messages.
o
Support hypermedia engine commands same as the
front-end (command lists and context sensitive information).
o
Incorporate a standard document interchange standard
such as ODA or SGML.
e.g. Sun's
Link Service PDF
o
Extensible protocol to create and maintain
relationships between autonomous front-end applications
o
Editing and storing of data objects is managed by
independent applications which also provide some amount of front-end operations
on links
o
The Link Service stores only the representations of
the nodes rather than the nodes themselves.
o
The definition and granularity of nodes are left to
the individual applications.
o
the storage of node data is independent of the storage
of link data.
o
The Link Service makes it easier for applications to
add hypertext functionality by providing a simple protocol, a shared back-end
or link server, a library, and utilities to manage the link database
o
Applications communicate with the link server through
the Link Service protocol.
o
Service allows independent applications to integrate
linking mechanisms into their standard functionality and become part of an
extensible and open hypertext system.
o
Existing text and graphics editors can be integrated
into such a framework without any modifications.
o
Due to the separation of node and link data, the Link
Service does not provide version control, node content editors, concurrent
multi-user access, or other forms of data integration.
Hypermedia Toolkit
J. J. Puttress and N. M.
Guimaraes. "The Toolkit Approach to Hypermedia"in Proceedings of the
ACM European Conference on Hypertext '90 (ECHT '90),
o
A toolkit that could be used by application developers
to add hypermedia functionality to their existing toolkit, independent of
specific applications or environment
o
The hypermedia toolkit architecture has the following
layers:
o
Application Software
o
Hypermedia Toolkit Layer
o
Storage System,
o
Representation System
Three components:
Storage System
Interface (also called Eggs):
o
Consists of a set of C++ classes, providing a
hypermedia structure to the stored application data.
o
Provides the mapping between the application above and
the storage system below.
o
Similar to the HAM approach, the data model is made of
graphs, contexts, nodes, links, attributes, and symbols
o
Interface does not interpret node data - it is just
considered as a stream of bytes with no structure or meaning.
o
Provides version control and concurrency control
mechanisms.
o
There is finer transaction management under the
control of the application
Application
Interface:
o
This interface is composed of data objects that
communicate with the application above.
Representation
System Interface:
o
Responsible for the presentation of views using user
interface toolkits, independent of the display platform
o
Application Interface and the Representation Interface
are made of a set of C++ classes, together called Hypermedia Object-oriented
Toolkit (HOT)
o
HOT provides the abstractions required for hypermedia
applications while encapsulating the details of the storage and representation
systems
o
HOT consists of Data classes that include: HGraph,
HContext, HNode, and HLink.
o
Consists of View classes for each of the Data classes:
HGraphView, HContextView, HNodeView, HLinkView and HFrame.
 Hypermedia Toolkit
Architecture
Hypermedia Toolkit
Architecture
HDM - Hypermedia Design Model
http://www.inf.udec.cl/~yfarran/HDM.htm
Basic features of
HDM include:
o
Representation of hypertext applications through
primitives: types entities composed of hierarchies of components
o
Different perspectives (different representations of
the same component, e.g. text & sound) for each component
o
Units corresponding to component-perspective pairs
o
Bodies representing the actual contents of units
o
Structural links relating components belonging to the
same entity
o
Application links relating components belonging to
different entities
o
Browsing semantics determining the visualization and
dynamic properties of the application
o
Primitives are similar to objects defined in HAM.
o
HDM is concerned with authoring-in-the-large -
definition of the topology of the hypertext network.
o
Does not deal with authoring-in-the-small - filling in
the contents of nodes and their presentation.
o
Systematic and rational structural decisions about the
hypertext should be made before the actual hypertext is written so that a
coherent and expressive application can be developed from the very beginning
instead of being added later
o
HDM design specifications can be translated
automatically into a lower-level node and link specification resulting in the
actual implementation of the topology.
Dexter Hypertext Reference Model
·
Result of a series of
workshops between October 1988 and July 1990
·
Tries to
integrate and formalize aspects found in different hypertext systems : Intermedia,
KMS, NoteCards, Augment
·
All major
developments, at least from research within the
·
Goal of the
model is to provide researchers with a standard for comparing systems and
developing interchange formats.
o
The Dexter model divides a hypertext system into three
layers:
a. Runtime Layer
o
Presentation of hypertext and the dynamics of user
interaction.
o
Dexter model does not go into the details of the
presentation mechanism - too broad and diverse to be developed into a generic
model
o
Presentation mechanisms can be specified containing
information about how a component/network is to be presented to the user.
o
Presentation specifications provide an interface
between the runtime layer and the storage layer.
b. Storage Layer
o
Main focus of the Dexter model
o
Models a database that is composed of a hierarchy of
data-containing components which are interconnected by relational links
o
The notion of
component replaces the weakly defined concept of nodes
o
Components have unique identifiers and links can be
identified by a set of two or more component identifiers
o
Components correspond to the general notion of nodes
and can contain text, graphics, images, audio, video etc.
o
Components are treated as generic containers of data
and the model does not specify any structure within the containers
o
Storage layer focuses on the mechanism by which
components and links are tied together to form hypertext networks.
o
Link component -
special type of component
o
Supports
computed as well as static links.
o
Can be single or
bi-directional as well as multiheaded.
o
Links can be
endpoints of links
o
Typing is supported
through attributes that are added to the link component.
o
To address
specific locations within a component the link component relies on the
anchoring interface between storage layer and the within-component layer.
c. Within
Component Layer
o
Concerned with the contents and structure within
components of the hypertext network.
o
Since the range of possible content/structure that can
be included in a component is open-ended, the Dexter model treats this layer as
being outside its scope.
o
The assumption is that document structure models such
as ODA, SGML, IGES etc., will be used in conjunction with this model to capture
content/structure.
o
A critical interface between the storage layer and the
within-component layer called anchoring discusses the mechanism of addressing
locations or items within the content of an individual component.
o
Anchoring
provides a mechanism for addressing specific locations (span-to-span links)
within all component types known to the system.
o
Anchors consist
of two parts:
o
an anchor
identifier, which is unique across the universe of discourse (not just within
the scope of one hypertext),
o
an anchor value,
which defines the actual region of the anchor within the component.
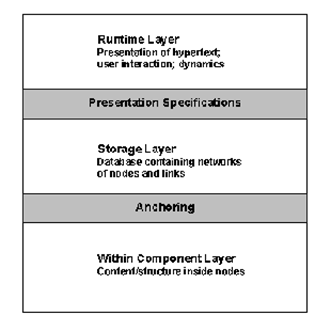 Dexter Hypertext
Reference Model
Dexter Hypertext
Reference Model
Early Interchange Standards
o
Hypertext documents are unstructured and can be
dynamic.
o
Early structured document standards were sufficient to
represent hypertext networks.
o
A tree based hierarchy is relevant but NOT sufficient
for hypertext.
o
There should be a hierarchical framework with a system
of typed links to cover the cross-references of structured documents and the
links of hypertext.
o
ODA (Open Document Architecture) and SGML were not
sufficient enough for the representation and exchange) of hypertext.
o
Extensions needed to provide a proper typed-link
mechanism.
o
SGML does not specify layout or presentation
information (which is important for hypertext) or how to handle images and
graphics.
o
ODA addresses these issues but it is not sufficient.
Limitations of SGML
1.
SGML allows cross-referencing within the same
document.
o
Uniqueness of an identifier is applicable only within
the current local document.
o
Only elements within the same document (and only those
having unique identifiers) can be linked.
o
This mechanism can only be used in a hypertext
document to refer to elements within the same document and not other documents.
2.
SGML cannot support time dependent data such as audio
and video and also graphics and images.
o
Rendering of events is not possible in SGML, that is,
displaying a map of NY and a link that zooms into
Limitations of ODA and possible
modifications
o
ODA, a standard for the storage and interchange of
multimedia documents, deals with both logical structure and layout structure or
presentation (unlike SGML).
o
ODA includes graphics and images and extensions are
being considered to handle audio, video, and hypertext
a. Separation of
logical structure and layout structure
o
Logical structure and layout structure are not
completely separated
o
The logical structure must be edited in order to
change the style of a document because the layout process uses the logical
structure, the generic structures and the content architectures to create the
specific layout.
b. Comprehensive
attribute inheritance
o
The ODA mechanism for inheriting layout attributes
(such as placement of blocks of contents within pages and rectangular areas
called frames) and presentation attributes (such as character sets and the
placement of items within blocks) is not sufficient.
o
If an attribute value is not specified for the object
or its class, then the value can only be inherited according to the object's
position in the tree and not according to its class (chapter, list etc.).
o
Attribute inheritance can be achieved by adding a
facility called "style tables" which will enable the style inherited
by an object (and hence its format) to depend both on its class and is position
in the document.
c. Links
o
ODA does not have the ability to specify the purpose
of a link and also how the layout process can express that purpose.
o
This can be accomplished by having classes for links
(just as there are classes for logical objects).
o
Class of the link will determine how and where in the
document the link can be used.
o
Representation of the link will depend on both the
class and its position in the document.
d. Selective and
multiple presentation
o
ODA does not have the ability to suppress the
appearance of a logical object (or contents) during the layout process nor the
ability to present the object many times.
e. Complete
interactivity
o
The ODA layout process is sequential and page based
and hence does not provide complete interactivity.
o
Does not support online editing capabilities such as:
o
ability to scroll through a document
o
ability to display selected items ( outlining
facility)
o
ability to popup additional information on demand
(such as footnotes, glossaries etc.)
o
ability to "fold" documents revealing hidden
sections only on request
o
ability to follow links automatically.
HyTime - Hypermedia/Time-based
Structuring Language
o
International Standard for representing hypertext
links and synchronization of static and time-based information contained in
multiple conventional and multimedia documents and information objects
o
HyTime is an SGML application conforming to ISO 8879
o
Addresses limitations of SGML
o
supports cross-referencing facilities to uniquely
identified elements in external documents
o
Extends SGML's reference capability to accommodate
elements with no unique identifiers in the same document
o
Provides pointers or location addressing schemes that
contain the necessary information in order to locate cross-referenced data
o
Independent of data content notations, link types,
processing, presentation, and semantics.
o
Supports addressing by name, by position in the document,
and by semantic construct.
o
Links can be established to documents that conform to
HyTime as well as those that do not.
o
Allows all kinds of multimedia and hypertext
technologies (whether proprietary or not) to be combined in any information
product.
o
Addresses only the issue of interchange of hypermedia
information NOT standardization of presentation (same as SGML), user
interfaces, query languages etc.
o
Objects in a HyTime hypertext document can include
formatted and unformatted documents, audio and video segments, still images,
animations, and graphics.
o
Provides the notion of "Architectural Form"
to SGML.
o
An architectural form is a syntax template around
which a document author can build semantic constructs for linking and
coordinate space addressing.
o
It is highly flexible and extensible.
o
The interchange format can be defined in Abstract
Syntax Notation 1 (ISO 8824) and can be encoded according to the basic encoding
rules of ISO 8825 for interchange using protocols conforming to the OSI model.
o
The full set of HyTime functionality supports
"integrated open hypermedia", the "bibliographic model" of
hyperlinking that allows links to anything, anywhere, anytime.
o
HyTime is intended for use as the infrastructure of
platform-independent information exchange for hypermedia and synchronized and
non-synchronized multimedia applications.
MHEG (Multimedia and
Hypermedia Experts Group)
http://www.prz.tu-berlin.de/~joe/mheg/mheg_intro.html
o
CCITT (Comité
Consultatif International Téléphonique et Télégraphique,
an organization that sets international communication standards) proposed the future
international standard for multimedia and hypermedia information objects, known
as the MHEG Standard.
o
MHEG standard - define the representation and encoding
of multimedia and hypermedia information objects that will be interchanged as a
whole within or across applications or services, by any means of interchange
including storage devices, telecommunications or broadcast networks
Objectives of the
MHEG standard include meeting the following requirements:
- Provide a simple but useful, easy to implement
framework for multimedia applications using the minimum system resources.
- Define a digital final form for presentations,
which may be used for exchange of the presentations between different
machines no matter what make or platform.
- Provide extensibility i.e. the system should be
expandable and customisable with additional application specific code,
though this may make the presentation platform dependent.
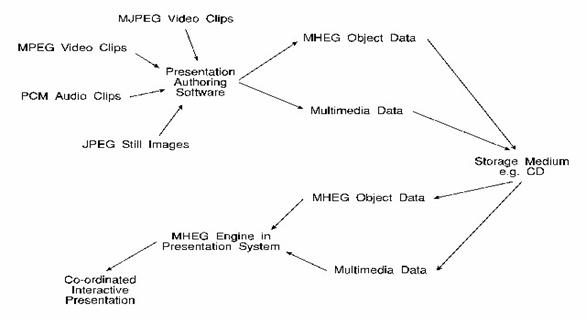

Amsterdam
·
The Amsterdam
Hypermedia Model (AHM) tries to tackle the complex timing and presentation
relationships found in multimedia presentations.
·
AHM extends the
Dexter model by adding high-level presentation attributes and link context.
·
Allows authors
to specify how individual pieces of information relate to each other over a
period of time.
·
Non trivial
problem - dynamic and static objects fetched from distributed sources have to
be synchronized.
·
Model must be
able to define requirements for links, time, and global representation
semantics in a hypermedia system.
Three approaches to
synchronization within hypermedia:
·
Hidden
structure approach
o Places all information about the context and time-based relationships within the content portion of a component
o Collections of different media are synchronized by internal
techniques of a component
o This approach does not change the hypermedia model
but also does not scale very well when media from different servers are
combined.
·
Separate
structure approach
o Opposite of the hidden structure approach
o Each piece of multimedia information is an individual
component
o Collections of media are realized by multiheaded
links.
o It is the responsibility to start all objects
simultaneously, or according to their timing-information
o This can become a significant problem.
·
Composite
structure approach
o Groups a limited number of media objects together
o Combines the advantages of the previous approaches
o While complicated synchronization is avoided outside
of components, collections are less complex than in the hidden structure
approach.
·
AHM extends the
definition of the Dexter component to capture these new requirements of
time-based synchronization
o Atomic component is expanded in thepresentation
information section.
§
Some information
used to model time-related aspects whereas others are used as high-level
presentation attributes.
o Presentation structure is encoded in composite
components.
o Timing offsets among the children of a component as
well as composite type (either parallel or choice, meaning either all children
or only one child gets displayed) are added to the composite specification.
o Synchronization arcs are used to define the
fine-grained temporal relations within components.
·
AHM defines the
notion of link context.
o Dexter does not define the behavior of components
when a link is followed out of that component or affected by a linking
operation.
§
Source
context - that portion of components
that are affected by initiating a link
§
Destination context is that part of the hypermedia presentation
that is activated on arriving at the destination.
§
Context
mechanism is used to allow the run-time environment determine appropriate
display operations, i.e., whether to reload resources or not.
·
AHM defines
channels as an abstraction of presentation attributes
o Channels are abstract output devices, which are used
to define global characteristics for a certain media type such as volume for an
audio channel.
o During run-time these abstract channels are mapped
onto physical output devices.
·
Timing
constructs added by AHM to the original Dexter model allow the specification of
time-based behavior of a document
·
Formal
description of this behavior can be transformed and represented in any form
such as HyTime
·
This allows the
interchange of documents between different applications.
DeVise Hypermedia Architecture (DHM)
·
Extension to the
Dexter Hypertext Reference Model from
·
Computer-supported
cooperative work (CSCW) raises several new requirements for hypermedia applications:
1. explicit communication and coordination between team
workers
2. implicit coordination through shared materials
·
New notions had
to be introduced to the model:
·
shared databases
·
event
notification
·
open access from
different platforms and from different
·
already
developed applications.
·
1. Mode of separate responsibilities – the material is divided into disjoint parts -
material can only be inspected by other users, but not altered
2. Turn taking mode – allows different users to work on the same material while no more
than one user is working at a time - requires support for cooperation to
coordinate work over time
3. Dynamic exchange mode – users work at the same time on different objects,
but are able to transfer locks on these objects from one user to the other.
4. Mode of alternative versions – allows each user to develop her own version of a
part -different versions of parts have to be merged later
5. Mutual sessions mode – allows two or more users to work on the same
material synchronously, using direct communication channels
6. Fully synchronous sessions mode - all users share exactly the same view of the
shared material.
·
First three
modes directly supported by the hypermedia model.
·
The asynchronous
cooperation can be provided by means of annotation or other methods of creating
awareness among users about the use of the shared material.
·
Mode four needs
the support of the storage layer to enable versioning of objects.
·
This is an
ongoing research topic in database research and will be solvable on the
database level.
·
The fully
synchronous modes need some additional means of communication beyond the point
that is currently available in the Dexter model.
·
Mode five and
six differ mainly in whether a shared view of objects is provided or not.
Whereas without shared view the synchronous cooperation is restricted to shared
commitment of changes on objects, the shared view option would allow all users
to see exactly the same state of an object. Changes on that object would
immediately propagate to all users of that session.
·
DeVise
Hypermedia Architecture (DHM) – proof-of-concept
·
Based on a
distributed object system, DHM introduces several client and server processes
compliant to the Dexter model.
·
Processes may
run on different platforms and communicate over a network with each other.
·
The editor
process is end-user oriented and integrates hypermedia facilities into conventional
editors like text editors, video or audio editors, or hypermedia browsers.
·
Each editor is
associated to a specific data object, i.e., to a specific type of component.
·
An editor's
functionality belongs to the Dexter within-component layer.
·
Editors
communicate to run-time processes to exchange anchor values with the storage
layer.
·
The run-time
process is a server for the editor process and is itself served by the OODB
server process, which provides the physical storage facilities.
·
The run-time process
instantiates the data objects of the physical storage layer at run-time and
provides the basic link service independent of the editor type.