CS835 - Data and Document Representation & Processing |
|
Lecture 4 – Hypermedia II – Linking |
History of Linking – Lewis, et.al. - PDF
· Simple, fixed or point to point
links are an enduring feature of hypertext
· Web has made them most
widely used hypermedia link type
· They are embodied in the
definition of HTML
· Essentially static, point
to point connections embedded as pointers in the source document. T
·
Have achieved their huge popularity through their
universality over the Internet.
· Some systems have links
held in link databases, separately from the documents to which they refer (e.g.
first seen in Intermedia)
· Open hypermedia systems
typically store links in a database independently of the documents and can be
static or dynamic.
· XML’s XLink proposal allows
these kinds of links for data on the Web
· Links do not necessarily
exist explicitly and are implicit in the structure in some hypertext design
models.
o
In some cases they may be dynamically created by a process which defines
how elements of the hypertext structure are related when the process is invoked
Navigation or Retrieval
· Retrieval typically answers the
request : "find me documents containing something like this query"
· In terms of links or
associations - retrieval usually relies on being able to make an association
between a query, for example a keyword or phrase, and an information item
(document) containing something similar to the query.
o
Typically, the association is achieved either through pre-indexing or
on-the-fly analysis.
· Navigation involves steering across
links or associations which do not necessarily require similarity between
the source (the query) and the destination.
· The link may represent some meaningful higher level association that is typically, but not necessarily, identified through the mind of the link author.
Content Based Retrieval (CBR)
· Retrieval using the actual
content of the information rather than meta-data, associated keywords or
manually constructed indexes.
· CBR for text is a well
established technique seen in the free text searches and content indexes
generated, for example, by Web search engines.
Content-based navigation (CBN)
·
Embodied in the concept of the generic link
o
The source anchors for such links are specified in terms of
source content rather than source location
o
Storage of source content as part of the link structure is
facilitated by the adoption of external link databases
o
Once authored from some source selection, a generic link may
be followed from any matching instance of the source content: hence
content-based navigation.
· Use of CBN gives
substantial savings in authoring and link maintenance effort but initially CBN
was only possible from text
Content or Concept?
· Problem with using content
for retrieval or for navigation:
o
We are not interested in the content.
o
Words and pictures, videos and speech are representations of objects,
ideas and concepts in the real world.
· It is the difference
between the signifier (media representations) and the signified (real objects,
concepts, ideas).
· We are interested in the
signified.
o
Humans can make the link from signifier to signified almost
automatically, typically drawing on a huge body of prior knowledge
o
In software systems the link (or its absence) is at the root of many of
the problems with content-based retrieval and navigation
· The same concept can have
many different text representations even in the same language (synonyms).
· In images, instances of the
same general concept may be very different (eg arm chairs and office chairs).
· The same object may look
vastly different in images of different views.
o
Possible solutions:
o
Use of digital thesaurus tools or facilities for statistically based
associations have been incorporated into information retrieval systems.
o
Introduce layers of associations, above the media based links, which try
to capture semantic associations relevant to an application and provide
navigation and retrieval based on concepts in addition to content
Nature of Linking –
Randall Trigg http://www.workpractice.com/trigg/thesis-chap4.html
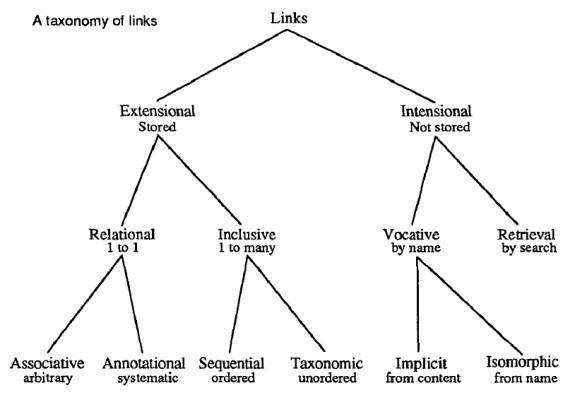
1: Extensional links
·
Extensional links are
idiosyncratic, tying various parts of the docuverse together in unpredictable
ways.
·
They must be stored
individually.
1 A:
Relational links
·
Connect single locations together.
·
Each of the two ends of a relational link is one conceptual unit, not
many.
1 A1 : Associative
links
·
A relational link which is entirely unpredictable is called an
associative link.
o
Such links are the usual stock in trade of hypertext systems.
o
Since they attach arbitrary pieces of documents, they cannot be replaced
by retrieval algorithms, or even by unilateral creation on the part of an
author.
o
Every user must be able to create them on the fly and to organize them
in whatever ways seem appropriate.
o
Because these links serve many purposes, they are usually labeled
according to type.
1 A2:
Annotational links
·
An annotational
link differs
from an associative link in that one of its ends is (in principal) predictable.
o
The existence of a link from each of a class of locations is
predictable, but the targets of those links are not.
o
Annotational links represent connections from portions of a text to information about the text,
such as the
presence of linguistic, thematic, or other phenomena.
o
Tend to originate from very low level elements (e.g., from every word),
although they can originate from larger units as well.
o
Often an annotation is selected from a fixed set of items, such as
(noun, verb, adjective, adverb, particle).
o
Difficulty - they may be attached to every word of a text.
1 B:
Inclusion Links
·
Extensional links which connect one originating location to many target
locations, not just one, are called inclusion links.
·
They function mainly to represent super-ordinate/sub-ordinate
relationships between document elements.
·
Two sub-types: sequential and taxonomic.
1 B1 : Sequential links
o
A sequential
link has
multiple, ordered target locations.
o
Paths are
a simple example: it should be possible to associate a path with a given
location, so the path is accessible from it as a matter of course, and this
feature follows immediately from viewing paths as sequential links.
o
Most important example - sequential link is the structure-representing
(s-r link) - represents those aspects
of document structure commonly encoded via descriptive markup in word
processing.
§
e.g, section links to the sequence of its sub-parts, which may include
subsections, paragraphs, block quotes, emphatic elements....
o
Most sequential links are of this kind, and represent hierarchical
structures of the text
o
Provide a basis for presenting the text in linear form when needed.
o
s-r links deserve special treatment by hypermedia systems for several
reasons :
§
First,
s-r links usually require specialized display
· e.g, being traversed
automatically, in order, as the user scrolls, rather than followed only on
request.
· One should not have to
follow links to see successive paragraphs of a chapter - one should see a smooth
and uninterrupted view of the document.
§
Second, s-r links express many useful and standard hierarchies.
· e.g. outline levels,
chapters/sections/subsections, etc.
· Knowing about formal
structures, a system can :
o
assist in generating useful links between related structural elements
(e.g, collecting all section-title elements into a table of contents linked to
the contents);
o
perform more effective retrieval (e.g, weighing words in titles more
heavily than words in running text)
o
help prevent anomalous documents (for example, those whose paragraphs
contain chapters).
§
Third,
s-r links characteristically point to sequences of other s-r links and not to
arbitrary spans of text.
· e.g, a section may be a
sequence of paragraphs; it is not merely a sequence of ranges of characters.
§
Fourth, unlike associative links, the set of s-r link types is fairly
constrained.
1B2:
Taxonomic links
o
A taxonomic
link leads to
multiple target locations, but does not impose an order on them.
o
Such links generally associate lists of properties with particular
document elements.
o
e.g, one may associate examples of some literary phenomenon with
commentary about it, or attach keywords indicating relevance, importance,
secrecy requirements, etc.
o
An unordered path may be created to connect passages of interest
o
Could connect related groups of data in a lexicon, such as
cross-references between words.
2: Intensional
links
- Intensional link follow strictly from the structure and content of
the documents they link and need not be stored one by one by the hypertext
system.
- The destination of an intensional link is
defined by some function that finds the desired ends, rather than being a list of known ends.
- Intensional links are mostly unidirectional
- In some cases a function may be invertible,
making it possible to reverse some intensional links.
- They may also have multiple ends.
2 A: Vocative links
- Some intensional links are called vocative because
they invoke a particular document element by name.
2 A1: Implicit links
· A vocative link which
exists because its target element’s name appears within the content of the
source document is called an implicit link.
o
e.g. dictionary look-up.
· Implicit links may be used
to access many other kinds of documents and sub- documents in addition to
dictionaries.
· Implicit links may attach
not just to words, but to any elements (e.g. graphics)
· These links have an
advantage over typical associative links, in that they communicate to the user
some indication of their destination
2 A2: Isomorphic links
· A vocative link which
exists because its target element’s name appears as an element name in the
source document (rather than as content) is called an isomorphic link.
· Isomorphic links are most
useful in cases where different documents share much or all of their logical
structure.
· They define the
correspondences among large structures of elements, usually entire documents.
· A distinguishing
characteristic of isomorphic links is that they tie together like-named (not “like-positioned”)
document elements.
· Despite superficial
variations there exists an abstract (meta-) document
o
e.g. the “Bible,” is represented by thousands of concrete manuscripts,
editions, and translations.
o
These documents share a structure of abstract elements.
o
By providing the ability to name document elements similarly despite
their existing in diverse documents, the needed level of abstraction can be
achieved.
· In reading meta-documents,
the most common need involves viewing simultaneously several concrete instances
of a particular text phenomenon.
· Parallel, synchronized
windows or panes are the usual solution.
· For documents with entirely
commensurable element names this solution is relatively easy, but there are
usually deviations from perfect isomorphism.
· e.g, certain elements may
be missing in some versions, or re-ordered; numbered groups of elements may be
divided or counted differently; elements may correspond to higher or lower
level elements in other versions.
· Corresponding elements may
differ drastically in size, in which case it is important for a hypertext
system to align and move text intuitively.
2 B: Retrieval links
· Retrieval links find their
target by its content, or perhaps by both name, structure, and content.
· A retrieval link invokes a
process to search a portion of the docuverse for something
· The process may be of
arbitrary complexity, and may in principle involve name-based, structure-based,
and content-based decisions.
· Whereas implicit links are
defined globally, retrieval links originate only at particular locations.
|
|
Reference: The XML Revolution Technologies for the future Web
http://www.brics.dk/~amoeller/XML/index.html
XInclude - combining XML documents
XInclude is an emerging W3C specification for building large XML documents out of multiple well-formed XML documents, independently of validation.
Each piece can be a complete XML document, a fragmentary XML document, or a non-XML text document like a Java program or an e-mail message.
Syntax
XInclude reference external
documents to be included with include
elements in the http://www.w3.org/2001/XInclude
namespace. The prefix xi is
customary though not required. Each xi:include
element has an href
attribute that contains a URL pointing to the file to include. For example, the
previous book example can be rewritten like this:
|
Of course you can also use absolute URLs where appropriate:
|
XInclude processing is recursive. That is, an included document can itself include another document. For example, a book might be divided into front matter, back matter, and several parts:
|
XML
Base
A URI identifies a resource:
- http://somewhere/somefile.xml is an absolute URI
- somefile.xml is a relative URI
Inspired by the <base href="..."> mechanism in HTML, XML Base provides a uniform way of resolving relative URIs.
In the following example:
|
<... xml:base="http://www.daimi.au.dk/"> |
the value of href attribute can be interpreted as the absolute URI http://www.daimi.au.dk/~mis/mn/index.html.
- the xml namespace prefix is hardwired by the Namespace specification
- xml:base has lexical scope (as namespace declarations)
- the URI used to access the document is used as default URI base
Examples of applications:
- XLink (requires XML Base support)
- XHTML (will use XML Base)
- Namespaces (does not conform to XML Base, but it ought to...)
- your future XML language
Three layers:
- XLink
- a generalization of the HTML link concept
- higher abstraction level (intended for general XML - not just hypertext)
- more expressive power (multiple destinations, special behaviors, linkbases, ...)
- uses XPointer to locate resources
- XPointer
- an extension of XPath suited for linking
- specifies connection between XPath expressions and URIs
- XPath
- a declarative language for locating nodes and fragments in XML trees
- used in both XPointer (for addressing), XSL (for pattern matching), XML Schema (for uniqueness and scope descriptions), and XQuery (for selection and iteration)
These technologies are standardized but not all widely implemented yet.
Problems
with HTML links
The HTML link model:
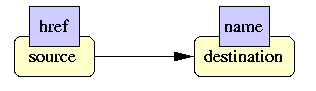
Construction of a hyperlink:
- <a name="here"> is placed at the destination
- <a href="URL#here"> is placed at the source
Problems when using the HTML model for general XML:
- Link recognition:
- in HTML, links are recognized
by element names (a,
img,
..)
- we want a generic XML solution - the
"semantics" of a link is defined in the HTML specification
- we want to identify abstract semantic features, e.g. link actuation - Limitations:
- an anchor must be
placed at every link destination (problem with read-only documents)
- we want to express relative locations (XPointer!) - the link definition
must be at the same location as the link source (outbound)
- we want inbound and third-party links - only individual
nodes can be linked to
- we want links to whole tree fragments - a link always has
one source and one destination
- we want links with multiple sources and destinations
The
usual point: generic solutions allow generic tools!
The
XLink linking model
Basic XLink terminology:
Link:
explicit relationship between two or more resources.
Linking element: an XML element that asserts the existence and describes
the characteristics of a link.
Locator: an identification of a remote resource that is participating in
the link.
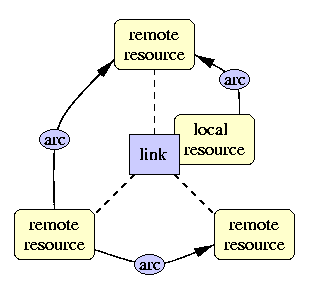
One linking element defines a set of traversable arcs between some resources.
A local resource comes from the linking element's own content.
Outbound:
the source is a local resource
Inbound: the destination is a local resource
Third-party: none of the resources are local
Third-party links can be used to construct shared link bases for browsers.
An
example
A linking element defining a third-party "extended" link involving two remote resources:
<mylink xmlns:xlink="http://www.w3.org/1999/xlink" xlink:type="extended"> <myresource xlink:type="locator" xlink:href="students.xml#Fred" xlink:label="student"/> <myresource xlink:type="locator" xlink:href="teachers.xml#Joe" xlink:label="teacher"/> <myarc xlink:type="arc" xlink:from="student" xlink:to="teacher"/> </mylink> |
- the namespace http://www.w3.org/1999/xlink is used to recognize XLink information in general XML documents
- the namespace often (but not necessarily) uses namespace prefix xlink
- host language: elements and attributes not belonging to this namespace are ignored by XLink processors
- all XLink information is defined in attributes (in host language elements)
- xlink:type="extended" indicates a linking element
- xlink:type="locator" locates a remote resource
- xlink:type="arc" defines traversal rules
A powerful example application of general XLinks:
o Using third-party links and a smart browser, a group of people can annotate Web pages with "post-it notes" for discussion - without having write access to the pages.
o They simply need to agree on a set of URIs to XLink link bases defining the annotations.
o The smart XLink-aware browser lets them select parts of the Web pages (as XPointer ranges), comment the parts by creating XLinks to a small XHTML documents, view each other's comments, place comments on comments, and perhaps also aid in structuring the comments.
Linking
elements
- defining links
All elements with XLink information contain an xlink:type attribute.
- a general linking element is defined using an xlink:type="extended" attribute; this element can contain the following:
- a local resource is defined with xlink:type="resource"
- a remote resource is defined with xlink:type="locator" and with an xlink:href attribute (an XPointer expression locating the resource)
- arcs (traversal rules) are defined with xlink:type="arc":
- both "resource" and "locator" elements can have xlink:label attributes
- an arc element has an xlink:from and an xlink:to attribute
- the "arc" element defines a set of arcs: from each resource having the from label to each resource having the to label
(Note the confusing terminology: a resource is defined either by a "resource" element or by a "locator" element.)
Behavior
- link semantics
Arcs can be annotated with abstract behavior information using the following attributes:
xlink:show - what happens when the link is activated?
Possible values:
|
embed |
insert the presentation of the target resource (the one at the end of the arc) in place of the source resource (the one at the beginning of the arc, where traversal was initiated) (example: as images in HTML) |
|
new |
display the target resource some other place without affecting the presentation of the source resource (example: as target="_blank" in an HTML link) |
|
replace |
replace the presentation of the resource containing the source with a presentation of the destination (example: as normal HTML links) |
|
other |
behavior specified elsewhere |
|
none |
no behavior is specified |
xlink:actuate - when is the link activated?
Possible values:
|
onLoad |
traverse the link immediately when recognized (example: as HTML images) |
|
onRequest |
traverse when explicitly requested (example: as normal HTML links) |
|
other |
behavior specified elsewhere |
|
none |
no behavior is specified |
Note: these notions of link behavior are rather abstract and do not make sense for all applications.
Semantic attributes: describe the meaning of link resources and arcs
xlink:title
provide human readable descriptions (also available as xlink:type="title" to allow markup)
xlink:role and xlink:arcrole
URI references to descriptions
Simple
vs. Extended links
- for compatibility and simplicity
Two kinds of links:
- extended - the general ones we have seen so far
- simple - a restricted version of extended links: only for two-ended outbound links (enough for HTML-style links)
Convenient shorthand notation for simple links:
<mylink xlink:type="simple" xlink:href="..." xlink:show="..." .../> |
is equivalent to:
<mylink xlink:type="extended"> <myresource xlink:type="resource" xlink:role="local"/> <myresource xlink:type="locator" xlink:role="remote" xlink:href="..."/> <myarc xlink:type="arc" xlink:from="local" xlink:to="remote" xlink:show="..." .../> </mylink> |
Many XLink properties (e.g. xlink:type and xlink:show) can conveniently be specified as defaults in the schema definition!
When should I use XLink? Tim Berners-Lee: only for hypertext linking (Not everybody agree...)
Xlink Examples
Example 1
|
<?xml version="1.0"
encoding="UTF-8"?> <?xml-stylesheet
type="text/css" href="xlink1ss.css"?> <insurance> <title> Supporting XLinks </title> Looking for <link xmlns:xlink = "http://www.w3.org/1999/xlink" xlink:type = "simple" xlink:show = "new" xlink:href = "http://www.w3c.org" onClick="location.href='http://www.w3c.org'"> health insurance </link>? </insurance> |
CSS File:
|
link
{color: #0000FF; text-decoration: underline; cursor: hand} title {display:block; font-size: 24pt} |
Example 2
The
Artist/Influence problem
Suppose you want to express in XML the relationship between artists and their environment. This includes making links from an artist to his/her influences, as well as links to descriptions of historical events of their time. The data for each artist might be written in a file like the following:
<?xml version="1.0"?> <artistinfo> <surname>Modigliani</surname> <name>Amadeo</name> <born>July 12, 1884</born><died>January 24, 1920</died> <biography> <p>In 1906, Modigliani settled in Paris, where ...</p> </biography> </artistinfo> |
Also, brief descriptions of time periods are included in separate files such as:
<?xml version="1.0"?> <period> <city>Paris</city> <country>France<country> <timeframe begin="1900" end="1920"/> <title>Paris in the early 20th century (up to the twenties)</title> <end>Amadeo</end> <description> <p>During this period, Russian, Italian, ...</p> </description> </period> |
Fulfilling our requirement (i.e. creating a file that relates artists to their influences and periods) is a task beyond a simple strategy like adding "a" or "img" links to the above documents, for several reasons:
· A single artist has many influences (a link points from one resource to many).
· A single artist has associations with many periods.
· The link itself must be semantically meaningful. (Having an influence is not the same as belonging to a period, and we want to express that in our document!)
The XLink Solution
In XLink we have two type of linking elements: simple (like "a" and "img" in HTML) and extended. Links are represented as elements. However, XLink does not impose any particular "correct" name for your links; instead, it lets you decide which elements of your own are going to serve as links, by means of the XLink attribute type. An example snippet will make this clearer:
<environment xlink:type="extended"> <!-- This is an extended link --> <!-- The resources involved must be included/referenced here --> </environment> |
Now that we have our extended link, we must specify the resources involved. Since the artist and movement information are stored outside our own document (so we have no control over them), we use XLink's locator elements to reference them. Again, the strategy is not to impose a tag name, but to let you mark your elements as locators using XLink attributes:
<environment xmlns:xlink="http://www.w3.org/1999/xlink" xlink:type="extended"> <!-- The resources involved in our link are the artist --> <!-- himself, his influences and the historical references --> <artist xlink:type="locator" xlink:label="artist" xlink:href="modigliani.xml"/> <influence xlink:type="locator" xlink:label="inspiration" xlink:href="cezanne.xml"/> <influence xlink:type="locator" xlink:label="inspiration" xlink:href="lautrec.xml"/> <influence xlink:type="locator" xlink:label="inspiration" xlink:href="rouault.xml"/> <history xlink:type="locator" xlink:label="period" xlink:href="paris.xml"/> <history xlink:type="locator" xlink:label="period" xlink:href="kisling.xml"/> </environment> |
Only one thing is missing: We must specify how the resources relate to each other. We do this by specifying arcs between them:
<environment xmlns:xlink="http://www.w3.org/1999/xlink" xlink:type="extended"> <!-- an artist is bound to his influences and history --> <artist xlink:type="locator" xlink:role="artist" xlink:href="modigliani.xml"/> <influence xlink:type="locator" xlink:label="inspiration" xlink:href="cezanne.xml"/> <influence xlink:type="locator" xlink:label="inspiration" xlink:href="lautrec.xml"/> <influence xlink:type="locator" xlink:label="inspiration" xlink:href="rouault.xml"/> <history xlink:type="locator" xlink:label="period" xlink:href="paris.xml"/> <history xlink:type="locator" xlink:label="period" xlink:href="kisling.xml"/> <bind xlink:type="arc" xlink:from="artist" xlink:to="inspiration"/> <bind xlink:type="arc" xlink:from="artist"xlink:to="period"/> </environment> |
XPointer:
Why, what, and how?
- an extension of XPath which is used by XLink to locate remote link resources
- relative addressing: allows links to places with no anchors
- flexible and robust: XPointer/XPath expressions often survive changes in the target document
- can point to substrings in character data and to whole tree fragments
Example of an XPointer:
URI ----------------------------------------------------------------- / \ http://www.foo.org/bar.xml#xpointer(article/section[position()<=5]) | \ /| | ---------------------------- | \ XPointer expression / \ / ----------------------------------- XPointer fragment identifier |
(points to the first five section elements in the article root element.)
In HTML, fragment identifiers may denote anchor IDs - XPointer generalizes that.
XPointer
vs. XPath
XPointer is based upon XPath:
- an XPointer expression is basically the same as an XPath expression
- XPath says nothing about URIs; XPointer specifies that connection
- an XPath expression is evaluated wrt. a context; XPointer specifies this context
- XPointer adds some features not available in XPath
XPointer
fragment identifiers
An XPointer fragment identifier (the substring to the right of # in the URI) is either
- the value of some ID attribute in the document (ID attributes are specified by the schema),
- a sequence of element numbers denoting the path from the root to an element (e.g. /1/27/3), or
- a sequence of the form
xpointer(...) xpointer(...) ...
containing a list (typically of length 1) of XPointer expressions.
Each expression is evaluated in turn, and the first where evaluation succeeds is used. (This allows alternative pointers to be specified thereby increasing robustness.)
XPointer spec has been split into four (tiny) parts:
XPath:
Location paths
XPath is a declarative language for:
- addressing (used in XLink/XPointer and in XSLT)
- pattern matching (used in XSLT and in XQuery)
The central construct is the location path, which is a sequence of location steps separated by /, e.g.:
child::section[position()<6] / descendant::cite / attribute::href |
selects all href attributes in cite elements in the first 5 sections of an article document.
- a location step is evaluated wrt. some context resulting in a set of nodes
- a location path is evaluated compositionally, left-to-right, starting with some initial context
- location paths resemble operating system directory paths
- each node resulting from evaluation of one step is used as context for evaluation of the next, and the results are unioned together
A context consists of:
- a context node
- a context position and size (two integers)
- variable bindings, a function library, and a set of namespace declarations
Initial
context: defined externally (e.g. by XPointer, XSLT, or XQuery).
Location paths can be prefixed with /
to use the document root as initial context node!
Note: in the XPath data model, the XML document tree has a special root node above the root element.
There is a strong analogy to directory paths (in UNIX). As an example, the directory path /*/d/*.txt selects a set of files, and the location path /*/d/*[@ext="txt"] select a set of XML elements
Location
steps
A single location step has the form
axis :: node-test [ predicate ]
- The axis selects a rough set of candidate nodes (e.g. the child nodes of the context node).
- The node-test performs an initial filtration of the candidates based on their
- types (chardata node, processing instruction, etc.), or
- names (e.g. element name).
- The predicates (zero
or more) cause a further, potentially more complex, filtration.
Only candidates for which the predicates evaluate to true are kept.
The candidates that survive the filtration constitute the result.
This structure of location steps makes implementation rather easy and efficient, since the complex predicates are only evaluated on relatively few nodes.
The example from before:
child::section[position()<6] / descendant::cite / attribute::href |
selects all href attributes in cite elements in the first 5 sections of an article document.
Axes
Available
axes:
|
the children of the context node |
|
|
all descendants (children, childrens children, ...) |
|
|
the parent (empty if at the root) |
|
|
all ancestors from the parent to the root |
|
|
siblings to the right |
|
|
siblings to the left |
|
|
all following nodes in the document, excluding descendants
|
|
|
all preceding nodes in the document, excluding ancestors |
|
|
attribute |
the attributes of the context node |
|
namespace |
namespace declarations in the context node |
|
self |
the context node itself |
|
descendant-or-self |
the union of descendant and self |
|
ancestor-or-self |
the union of ancestor and self |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Note that attributes and namespace declarations are considered a special kind of nodes here.
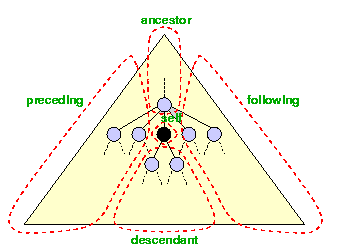
Some of these axes assume a document ordering of the tree nodes. The ordering is the left-to-right preorder traversal of the document tree - which is the same as the order in the textual representation.
The
resulting sets are ordered intuitively, either forward (in
document order) or reverse (reverse document order).
For instance, following is a
forward axis, and ancestor is a
reverse axis.
(Frustratingly, each technology uses a slightly different tree model...)
Node
tests
Testing by node type:
|
text() |
chardata nodes |
|
comment() |
comment nodes |
|
processing-instruction() |
processing instruction nodes |
|
node() |
all nodes (not including attributes and namespace
declarations) |
Testing by node name:
|
name |
|
nodes with that name |
|
* |
|
any node |
Warning: There is a bug in the XPath 1.0 spec! Default namespaces are required to be handled incorrectly, so, if using Namespaces together with XPath (or XSLT), all elements must have an explicit prefix.
Predicates
- expressions coerced to type boolean
A predicate filters a node-set by evaluating the predicate expression on each node in the set with
- that node as the context node,
- the size of the node-set as the context size, and
- the position of the node in the node-set wrt. the axis ordering as the context position.
Example:
child::section[position()<6] / descendant::cite[attribute::href="there"] |
selects all cite elements with href="there" attributes in the first 5 sections of an article document.
The XPath predicate language is very large, but these are the essential ones to know
- [attribute::name="flour"]: test equality of an attribute
- [attribute::name!="flour"]: test inequality of an attribute
- [attribute::amount='0.5' and attribute::unit='cup']: test two things at once (also or)
- [position()=2]: test position among siblings
- [attribute::amount<'0.5']: a syntax error
- [attribute::amount<'0.5']: a useless test of lexicographical order
- [number(attribute::amount)<number('0.5')]: what you meant to write instead!
An entire location path may be used as a predicate
- start at the current node
- the predicate is true if the location path hits some result positions
- it is false otherwise
This is very useful to look ahead:
- [attribute::amount]: the node has an amount attribute
- [descendant::ingredient]: the node has a nested ingredient
Expressions
Available types:
- node-set (set of nodes)
- boolean (true or false)
- number (floating point)
- string (Unicode text)
An expression can be:
- a constant, e.g. "..."
- a variable: $variable
- a function call: function ( arguments )
- a boolean expression: or, and, =, !=, <, >, <=, >= (standard precedence, all left associative)
- a numerical expression: +, -, *, div, mod
- a node-set expression (using location paths!): | (set union)
Coercion may occur at function arguments and when expressions are used as predicates.
Variables and functions are evaluated using the context.
Core
function library
Node-set functions:
|
last() |
returns the context size |
|
position() |
returns the context position |
|
count(node-set) |
number of nodes in node-set |
|
name(node-set) |
string representation of first node in node-set |
|
... |
... |
String functions:
|
string(value) |
type cast to string |
|
concat(string, string, ...) |
string concatenation |
|
... |
... |
Boolean functions:
|
boolean(value) |
type cast to boolean |
|
not(boolean) |
boolean negation |
|
... |
... |
Number functions:
|
number(value) |
type cast to number |
|
sum(node-set) |
sum of number value of each node in node-set |
|
... |
... |
- see the XPath specification
for the complete list.
Abbreviations
Syntactic sugar: convenient notation for common situations
|
Normal syntax |
Abbreviation |
|
child::
|
nothing (so child is the default axis) |
|
attribute::
|
@ |
|
/descendant-or-self::node()/
|
// |
|
self::node()
|
.
(useful because location paths starting with / begin
evaluation at the root) |
|
parent::node()
|
.. |
Example:
.//@href |
selects all href attributes in descendants of the context node.
Furthermore, the coercion rules often allow compact notation, e.g.
foo[3] |
refers to the third foo child element of the context node (because 3 is coerced to position()=3).
XPath
visualization
Using Explorer 6 (or an updated version of Explorer 5) it is easy to experiment with XPath expressions.
The XPath Visualizer provides an interactive XPath evaluator that additionally visualizes the resulting node set (online installation).
This tool is implemented as an ordinary HTML page that makes heavy use of XSLT and JavaScript.
XPath
examples
The following XPath expressions point to sets of nodes in the recipe collection:
"The amounts of flour being used":
|
//ingredient[@name="flour"]/@amount |
40.530.25 |
"The ingredients of which half a cup are used":
|
//ingredient[@amount='0.5' and @unit='cup']/@name |
grated Parmesan cheeseshredded mozzarella cheeseshorteningflourorange juice |
"The second step in preparing stock for Cailles en Sarcophages":
|
//ingredient[@name="stock"]/preparation/step[position()=2]/text() |
When the liquid is relatively clear, add the carrots, celery, whole onion, bay leaf, parsley, peppercorns and salt. Reduce the heat, cover and let simmer at least 2 hours to make a hearty stock. |
XPath
2.0
- currently a Working Draft, developed to capture the common subset of XSLT 2.0 and XQuery 1.0
Major changes from 1.0:
- now using XML Schema primitive types instead of the four in 1.0
- new type operators: cast, treat, assert, instance of
- now using sequences instead of node-sets
- also allow non-node types
- new operators: for, if, some, every, intersect, except
- many(!) new functions
- regular expression match/replace/tokenize
- date formats
- ...
XPointer, Part II - how XPointer uses XPath
XPointer:
Context initialization
An XPointer is basically an XPath expression occurring in a URI.
When evaluated, the initial context is defined as follows:
- the context node is the root node of the document
- the context position and size are both 1 (because the root has no siblings)
- the variable bindings are empty (variables are not used by XPointer)
- the function library consists of the core XPath functions + a few extra functions
- the namespace declarations are set as follows:
xmlns(myprefix=http://mynamespace.org) xpointer(...)
Warning: several levels of character escaping occur when using XPointer
in XML documents
- in XPointer, unbalanced parentheses must be escaped, e.g. ^)
- in URIs, many characters must be escaped, e.g. %20
- in XML attribute values, quotes, ampersand, etc. must be escaped, e.g. <
Extra
XPointer features
XPointer provides a more fine-grained addressing than XPath.
- Instead of just nodes, XPointers address locations, which can be nodes, points, or ranges.
- A point can
represent the location preceding or following any individual character
in e.g. chardata nodes.
The special node test
point()
selects the set of points of a node. - A range consists of two points in the same document, and is specified using a special range-to location step construct.
- XPointer provides some extra functions:
|
here() |
get location of element containing current XPointer |
|
origin() |
get location where user initiated link traversal |
|
start-point(location-set) |
get start point of location set |
|
string-range(...) |
find matching substrings |
|
... |
|
Example:
/descendant::text()/point()[position()=0] |
selects the locations right before the first character of all character data nodes in the document.
Example:
/section[1] / range-to(/section[3]) |
selects everything from the beginning of the first section to the end of the third.
Selected
links: