Chapter 1. Introduction
Computer systems are
undergoing a revolution. From 1945, when the modern computer era began, until
about 1985, computers were large and expensive. Even minicomputers cost at
least tens of thousands of dollars each. As a result, most organizations had
only a handful of computers, and for lack of a way to connect them, these
operated independently from one another.
Starting around the the
mid-1980s, however, two advances in technology began to change that situation.
The first was the development of powerful microprocessors. Initially, these
were 8-bit machines, but soon 16-, 32-, and 64-bit CPUs became common. Many of
these had the computing power of a mainframe (i.e., large) computer, but for a
fraction of the price.
The amount of improvement
that has occurred in computer technology in the past half century is truly
staggering and totally unprecedented in other industries. From a machine that
cost 10 million dollars and executed 1instruction per second, we have come to
machines that cost 1000 dollars and are able to execute 1 billion instructions
per second, a price/performance gain of 1013. If cars had improved at this rate
in the same time period, a Rolls Royce would now cost 1 dollar and get a
billion miles per gallon. (Unfortunately, it would probably also have a
200-page manual telling how to open the door.)
The second development was
the invention of high-speed computer networks. Local-area networks or LANs
allow hundreds of machines within a building to be connected in such a way that
small amounts of information can be transferred between machines in a few
microseconds or so. Larger amounts of data can be moved between machines at
rates of 100 million to 10 billion bits/sec. Wide-area networks or WANs allow
millions of machines all over the earth to be connected at speeds varying from
64 Kbps (kilobits per second) to gigabits per second.
[Page 2]
The result of these
technologies is that it is now not only feasible, but easy, to put together
computing systems composed of large numbers of computers connected by a
high-speed network. They are usually called computer networks or distributed
systems, in contrast to the previous centralized systems (or single-processor
systems) consisting of a single computer, its peripherals, and perhaps some
remote terminals.
1.1. Definition of a Distributed System
Various definitions of
distributed systems have been given in the literature, none of them
satisfactory, and none of them in agreement with any of the others. For our purposes
it is sufficient to give a loose characterization:
A distributed system is a
collection of independent computers that appears to its users as a single
coherent system.
This definition has several
important aspects. The first one is that a distributed system consists of
components (i.e., computers) that are autonomous. A second aspect is that users
(be they people or programs) think they are dealing with a single system. This
means that one way or the other the autonomous components need to collaborate.
How to establish this collaboration lies at the heart of developing distributed
systems. Note that no assumptions are made concerning the type of computers. In
principle, even within a single system, they could range from high-performance
mainframe computers to small nodes in sensor networks. Likewise, no assumptions
are made on the way that computers are interconnected. We will return to these
aspects later in this chapter.
Instead of going further
with definitions, it is perhaps more useful to concentrate on important
characteristics of distributed systems. One important characteristic is that
differences between the various computers and the ways in which they
communicate are mostly hidden from users. The same holds for the internal
organization of the distributed system. Another important characteristic is
that users and applications can interact with a distributed system in a
consistent and uniform way, regardless of where and when interaction takes
place.
In principle, distributed
systems should also be relatively easy to expand or scale. This characteristic
is a direct consequence of having independent computers, but at the same time,
hiding how these computers actually take part in the system as a whole. A
distributed system will normally be continuously available, although perhaps
some parts may be temporarily out of order. Users and applications should not
notice that parts are being replaced or fixed, or that new parts are added to
serve more users or applications.
[Page 3]
In order to support
heterogeneous computers and networks while offering a single-system view,
distributed systems are often organized by means of a layer of software–that
is, logically placed between a higher-level layer consisting of users and
applications, and a layer underneath consisting of operating systems and basic
communication facilities, as shown in Fig. 1-1 Accordingly, such a distributed
system is sometimes called middleware.
Figure 1-1. A distributed
system organized as middleware. The middleware layer extends over multiple
machines, and offers each application the same interface.
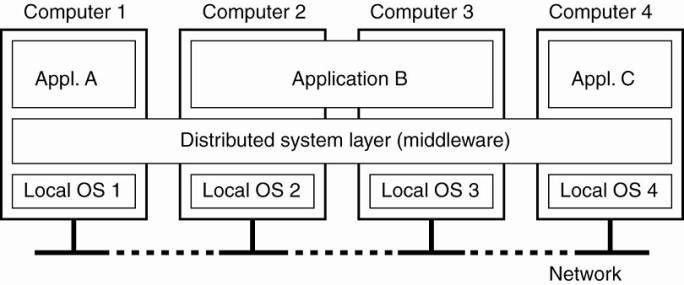
Fig. 1-1 shows four
networked computers and three applications, of which application B is
distributed across computers 2 and 3. Each application is offered the same interface.
The distributed system provides the means for components of a single
distributed application to communicate with each other, but also to let
different applications communicate. At the same time, it hides, as best and
reasonable as possible, the differences in hardware and operating systems from
each application.
1.2. Goals
Just because it is possible
to build distributed systems does not necessarily mean that it is a good idea.
After all, with current technology it is also possible to put four floppy disk
drives on a personal computer. It is just that doing so would be pointless. In
this section we discuss four important goals that should be met to make
building a distributed system worth the effort. A distributed system should
make resources easily accessible; it should reasonably hide the fact that
resources are distributed across a network; it should be open; and it should be
scalable.
1.2.1. Making Resources Accessible
The main goal of a
distributed system is to make it easy for the users (and applications) to
access remote resources, and to share them in a controlled and efficient way.
Resources can be just about anything, but typical examples include things like
printers, computers, storage facilities, data, files, Web pages, and networks, to
name just a few. There are many reasons for wanting to share resources. One
obvious reason is that of economics. For example, it is cheaper to let a
printer be shared by several users in a small office than having to buy and
maintain a separate printer for each user. Likewise, it makes economic sense to
share costly resources such as supercomputers, high-performance storage
systems, imagesetters, and other expensive peripherals.
[Page 4]
Connecting users and
resources also makes it easier to collaborate and exchange information, as is
clearly illustrated by the success of the Internet with its simple protocols
for exchanging files, mail, documents, audio, and video. The connectivity of
the Internet is now leading to numerous virtual organizations in which
geographically widely-dispersed groups of people work together by means of
groupware, that is, software for collaborative editing, teleconferencing, and
so on. Likewise, the Internet connectivity has enabled electronic commerce
allowing us to buy and sell all kinds of goods without actually having to go to
a store or even leave home.
However, as connectivity and
sharing increase, security is becoming increasingly important. In current practice,
systems provide little protection against eavesdropping or intrusion on
communication. Passwords and other sensitive information are often sent as
cleartext (i.e., unencrypted) through the network, or stored at servers that we
can only hope are trustworthy. In this sense, there is much room for
improvement. For example, it is currently possible to order goods by merely
supplying a credit card number. Rarely is proof required that the customer owns
the card. In the future, placing orders this way may be possible only if you
can actually prove that you physically possess the card by inserting it into a
card reader.
Another security problem is
that of tracking communication to build up a preference profile of a specific
user (Wang et al., 1998). Such tracking explicitly violates privacy, especially
if it is done without notifying the user. A related problem is that increased
connectivity can also lead to unwanted communication, such as electronic junk
mail, often called spam. In such cases, what we may need is to protect
ourselves using special information filters that select incoming messages based
on their content.
1.2.2. Distribution Transparency
An important goal of a
distributed system is to hide the fact that its processes and resources are physically
distributed across multiple computers. A distributed system that is able to
present itself to users and applications as if it were only a single computer
system is said to be transparent. Let us first take a look at what kinds of
transparency exist in distributed systems. After that we will address the more
general question whether transparency is always required.
[Page 5]
Types of Transparency
The concept of transparency
can be applied to several aspects of a distributed system, the most important
ones shown in Fig. 1-2.
Figure 1-2. Different forms
of transparency in a distributed system (ISO, 1995).
|
Transparency |
Description |
|
Access |
Hide differences in data
representation and how a resource is accessed |
|
Location |
Hide where a resource is
located |
|
Migration |
Hide that a resource may
move to another location |
|
Relocation |
Hide that a resource may
be moved to another location while in use |
|
Replication |
Hide that a resource is
replicated |
|
Concurrency |
Hide that a resource may
be shared by several competitive users |
|
Failure |
Hide the failure and
recovery of a resource |
Access transparency deals
with hiding differences in data representation and the way that resources can be
accessed by users. At a basic level, we wish to hide differences in machine
architectures, but more important is that we reach agreement on how data is to
be represented by different machines and operating systems. For example, a
distributed system may have computer systems that run different operating
systems, each having their own file-naming conventions. Differences in naming
conventions, as well as how files can be manipulated, should all be hidden from
users and applications.
An important group of transparency
types has to do with the location of a resource. Location transparency refers
to the fact that users cannot tell where a resource is physically located in
the system. Naming plays an important role in achieving location transparency.
In particular, location transparency can be achieved by assigning only logical
names to resources, that is, names in which the location of a resource is not
secretly encoded. An example of a such a name is the URL
http://www.prenhall.com/index.html, which gives no clue about the location of
Prentice Hall's main Web server. The URL also gives no clue as to whether
index.html has always been at its current location or was recently moved there.
Distributed systems in which resources can be moved without affecting how those
resources can be accessed are said to provide migration transparency. Even
stronger is the situation in which resources can be relocated while they are
being accessed without the user or application noticing anything. In such
cases, the system is said to support relocation transparency. An example of
relocation transparency is when mobile users can continue to use their wireless
laptops while moving from place to place without ever being (temporarily)
disconnected.
As we shall see, replication
plays a very important role in distributed systems. For example, resources may
be replicated to increase availability or to improve performance by placing a
copy close to the place where it is accessed. Replication transparency deals
with hiding the fact that several copies of a resource exist. To hide
replication from users, it is necessary that all replicas have the same name.
Consequently, a system that supports replication transparency should generally
support location transparency as well, because it would otherwise be impossible
to refer to replicas at different locations.
[Page 6]
We already mentioned that an
important goal of distributed systems is to allow sharing of resources. In many
cases, sharing resources is done in a cooperative way, as in the case of
communication. However, there are also many examples of competitive sharing of
resources. For example, two independent users may each have stored their files
on the same file server or may be accessing the same tables in a shared
database. In such cases, it is important that each user does not notice that
the other is making use of the same resource. This phenomenon is called
concurrency transparency. An important issue is that concurrent access to a
shared resource leaves that resource in a consistent state. Consistency can be
achieved through locking mechanisms, by which users are, in turn, given
exclusive access to the desired resource. A more refined mechanism is to make
use of transactions, but as we shall see in later chapters, transactions are
quite difficult to implement in distributed systems.
A popular alternative
definition of a distributed system, due to Leslie Lam-port, is "You know
you have one when the crash of a computer you've never heard of stops you from
getting any work done." This description puts the finger on another
important issue of distributed systems design: dealing with failures. Making a
distributed system failure transparent means that a user does not notice that a
resource (he has possibly never heard of) fails to work properly, and that the
system subsequently recovers from that failure. Masking failures is one of the
hardest issues in distributed systems and is even impossible when certain
apparently realistic assumptions are made, as we will discuss in Chap. 8. The
main difficulty in masking failures lies in the inability to distinguish
between a dead resource and a painfully slow resource. For example, when
contacting a busy Web server, a browser will eventually time out and report
that the Web page is unavailable. At that point, the user cannot conclude that
the server is really down.
Degree of Transparency
Although distribution
transparency is generally considered preferable for any distributed system,
there are situations in which attempting to completely hide all distribution
aspects from users is not a good idea. An example is requesting your electronic
newspaper to appear in your mailbox before 7 A.M. local time, as usual, while
you are currently at the other end of the world living in a different time
zone. Your morning paper will not be the morning paper you are used to.
Likewise, a wide-area
distributed system that connects a process in San Francisco to a process in
Amsterdam cannot be expected to hide the fact that Mother Nature will not allow
it to send a message from one process to the other in less than about 35
milliseconds. In practice it takes several hundreds of milliseconds using a
computer network. Signal transmission is not only limited by the speed of
light, but also by limited processing capacities of the intermediate switches.
[Page 7]
There is also a trade-off
between a high degree of transparency and the performance of a system. For
example, many Internet applications repeatedly try to contact a server before
finally giving up. Consequently, attempting to mask a transient server failure
before trying another one may slow down the system as a whole. In such a case,
it may have been better to give up earlier, or at least let the user cancel the
attempts to make contact.
Another example is where we
need to guarantee that several replicas, located on different continents, need
to be consistent all the time. In other words, if one copy is changed, that
change should be propagated to all copies before allowing any other operation.
It is clear that a single update operation may now even take seconds to
complete, something that cannot be hidden from users.
Finally, there are
situations in which it is not at all obvious that hiding distribution is a good
idea. As distributed systems are expanding to devices that people carry around,
and where the very notion of location and context awareness is becoming
increasingly important, it may be best to actually expose distribution rather
than trying to hide it. This distribution exposure will become more evident
when we discuss embedded and ubiquitous distributed systems later in this
chapter. As a simple example, consider an office worker who wants to print a
file from her notebook computer. It is better to send the print job to a busy
nearby printer, rather than to an idle one at corporate headquarters in a
different country.
There are also other
arguments against distribution transparency. Recognizing that full distribution
transparency is simply impossible, we should ask ourselves whether it is even
wise to pretend that we can achieve it. It may be much better to make
distribution explicit so that the user and application developer are never
tricked into believing that there is such a thing as transparency. The result
will be that users will much better understand the (sometimes unexpected)
behavior of a distributed system, and are thus much better prepared to deal
with this behavior.
The conclusion is that
aiming for distribution transparency may be a nice goal when designing and
implementing distributed systems, but that it should be considered together
with other issues such as performance and comprehensibility. The price for not
being able to achieve full transparency may be surprisingly high.
1.2.3. Openness
Another important goal of
distributed systems is openness. An open distributed system is a system that
offers services according to standard rules that describe the syntax and
semantics of those services. For example, in computer networks, standard rules
govern the format, contents, and meaning of messages sent and received. Such
rules are formalized in protocols. In distributed systems, services are
generally specified through interfaces, which are often described in an
Interface Definition Language (IDL). Interface definitions written in an IDL
nearly always capture only the syntax of services. In other words, they specify
precisely the names of the functions that are available together with types of
the parameters, return values, possible exceptions that can be raised, and so
on. The hard part is specifying precisely what those services do, that is, the
semantics of interfaces. In practice, such specifications are always given in
an informal way by means of natural language.
[Page 8]
If properly specified, an
interface definition allows an arbitrary process that needs a certain interface
to talk to another process that provides that interface. It also allows two
independent parties to build completely different implementations of those interfaces,
leading to two separate distributed systems that operate in exactly the same
way. Proper specifications are complete and neutral. Complete means that
everything that is necessary to make an implementation has indeed been
specified. However, many interface definitions are not at all complete, so that
it is necessary for a developer to add implementation-specific details. Just as
important is the fact that specifications do not prescribe what an
implementation should look like; they should be neutral. Completeness and
neutrality are important for interoperability and portability (Blair and
Stefani, 1998). Interoperability characterizes the extent by which two
implementations of systems or components from different manufacturers can
co-exist and work together by merely relying on each other's services as
specified by a common standard. Portability characterizes to what extent an
application developed for a distributed system A can be executed, without
modification, on a different distributed system B that implements the same
interfaces as A.
Another important goal for
an open distributed system is that it should be easy to configure the system
out of different components (possibly from different developers). Also, it
should be easy to add new components or replace existing ones without affecting
those components that stay in place. In other words, an open distributed system
should also be extensible. For example, in an extensible system, it should be
relatively easy to add parts that run on a different operating system, or even
to replace an entire file system. As many of us know from daily practice,
attaining such flexibility is easier said than done.
Separating Policy from
Mechanism
To achieve flexibility in open
distributed systems, it is crucial that the system is organized as a collection
of relatively small and easily replaceable or adaptable components. This
implies that we should provide definitions not only for the highest-level
interfaces, that is, those seen by users and applications, but also definitions
for interfaces to internal parts of the system and describe how those parts
interact. This approach is relatively new. Many older and even contemporary
systems are constructed using a monolithic approach in which components are
only logically separated but implemented as one, huge program. This approach
makes it hard to replace or adapt a component without affecting the entire
system. Monolithic systems thus tend to be closed instead of open.
[Page 9]
The need for changing a
distributed system is often caused by a component that does not provide the
optimal policy for a specific user or application. As an example, consider
caching in the World Wide Web. Browsers generally allow users to adapt their caching
policy by specifying the size of the cache, and whether a cached document
should always be checked for consistency, or perhaps only once per session.
However, the user cannot influence other caching parameters, such as how long a
document may remain in the cache, or which document should be removed when the
cache fills up. Also, it is impossible to make caching decisions based on the
content of a document. For instance, a user may want to cache railroad
timetables, knowing that these hardly change, but never information on current
traffic conditions on the highways.
What we need is a separation
between policy and mechanism. In the case of Web caching, for example, a
browser should ideally provide facilities for only storing documents, and at
the same time allow users to decide which documents are stored and for how
long. In practice, this can be implemented by offering a rich set of parameters
that the user can set (dynamically). Even better is that a user can implement
his own policy in the form of a component that can be plugged into the browser.
Of course, that component must have an interface that the browser can
understand so that it can call procedures of that interface.
1.2.4. Scalability
Worldwide connectivity
through the Internet is rapidly becoming as common as being able to send a
postcard to anyone anywhere around the world. With this in mind, scalability is
one of the most important design goals for developers of distributed systems.
Scalability of a system can
be measured along at least three different dimensions (Neuman, 1994). First, a
system can be scalable with respect to its size, meaning that we can easily add
more users and resources to the system. Second, a geographically scalable
system is one in which the users and resources may lie far apart. Third, a
system can be administratively scalable, meaning that it can still be easy to
manage even if it spans many independent administrative organizations.
Unfortunately, a system that is scalable in one or more of these dimensions
often exhibits some loss of performance as the system scales up.
Scalability Problems
When a system needs to
scale, very different types of problems need to be solved. Let us first
consider scaling with respect to size. If more users or resources need to be
supported, we are often confronted with the limitations of centralized
services, data, and algorithms (see Fig. 1-3). For example, many services are
centralized in the sense that they are implemented by means of only a single
server running on a specific machine in the distributed system. The problem
with this scheme is obvious: the server can become a bottleneck as the number
of users and applications grows. Even if we have virtually unlimited processing
and storage capacity, communication with that server will eventually prohibit
further growth.
[Page 10]
Figure 1-3. Examples of
scalability limitations.
|
Concept |
Example |
|
Centralized services |
A single server for all
users |
|
Centralized data |
A single on-line telephone
book |
|
Centralized algorithms |
Doing routing based on
complete information |
Unfortunately, using only a
single server is sometimes unavoidable. Imagine that we have a service for
managing highly confidential information such as medical records, bank accounts,
and so on. In such cases, it may be best to implement that service by means of
a single server in a highly secured separate room, and protected from other
parts of the distributed system through special network components. Copying the
server to several locations to enhance performance may be out of the question
as it would make the service less secure.
Just as bad as centralized
services are centralized data. How should we keep track of the telephone
numbers and addresses of 50 million people? Suppose that each data record could
be fit into 50 characters. A single 2.5-gigabyte disk partition would provide
enough storage. But here again, having a single database would undoubtedly
saturate all the communication lines into and out of it. Likewise, imagine how
the Internet would work if its Domain Name System (DNS) was still implemented
as a single table. DNS maintains information on millions of computers worldwide
and forms an essential service for locating Web servers. If each request to
resolve a URL had to be forwarded to that one and only DNS server, it is clear
that no one would be using the Web (which, by the way, would solve the
problem).
Finally, centralized
algorithms are also a bad idea. In a large distributed system, an enormous
number of messages have to be routed over many lines. From a theoretical point
of view, the optimal way to do this is collect complete information about the
load on all machines and lines, and then run an algorithm to compute all the
optimal routes. This information can then be spread around the system to
improve the routing.
The trouble is that
collecting and transporting all the input and output information would again be
a bad idea because these messages would overload part of the network. In fact,
any algorithm that operates by collecting information from all the sites, sends
it to a single machine for processing, and then distributes the results should
generally be avoided. Only decentralized algorithms should be used. These
algorithms generally have the following characteristics, which distinguish them
from centralized algorithms:
[Page 11]
- No machine has complete information about the
system state.
- Machines make decisions based only on local
information.
- Failure of one machine does not ruin the
algorithm.
- There is no implicit assumption that a global
clock exists.
The first three follow from
what we have said so far. The last is perhaps less obvious but also important.
Any algorithm that starts out with: "At precisely 12:00:00 all machines
shall note the size of their output queue" will fail because it is
impossible to get all the clocks exactly synchronized. Algorithms should take
into account the lack of exact clock synchronization. The larger the system,
the larger the uncertainty. On a single LAN, with considerable effort it may be
possible to get all clocks synchronized down to a few microseconds, but doing
this nationally or internationally is tricky.
Geographical scalability has
its own problems. One of the main reasons why it is currently hard to scale
existing distributed systems that were designed for local-area networks is that
they are based on synchronous communication. In this form of communication, a
party requesting service, generally referred to as a client, blocks until a
reply is sent back. This approach generally works fine in LANs where
communication between two machines is generally at worst a few hundred
microseconds. However, in a wide-area system, we need to take into account that
interprocess communication may be hundreds of milliseconds, three orders of
magnitude slower. Building interactive applications using synchronous
communication in wide-area systems requires a great deal of care (and not a
little patience).
Another problem that hinders
geographical scalability is that communication in wide-area networks is
inherently unreliable, and virtually always point-to-point. In contrast,
local-area networks generally provide highly reliable communication facilities
based on broadcasting, making it much easier to develop distributed systems.
For example, consider the problem of locating a service. In a local-area
system, a process can simply broadcast a message to every machine, asking if it
is running the service it needs. Only those machines that have that service
respond, each providing its network address in the reply message. Such a
location scheme is unthinkable in a wide-area system: just imagine what would
happen if we tried to locate a service this way in the Internet. Instead,
special location services need to be designed, which may need to scale
worldwide and be capable of servicing a billion users. We return to such
services in Chap. 5.
Geographical scalability is
strongly related to the problems of centralized solutions that hinder size
scalability. If we have a system with many centralized components, it is clear
that geographical scalability will be limited due to the performance and
reliability problems resulting from wide-area communication. In addition,
centralized components now lead to a waste of network resources. Imagine that a
single mail server is used for an entire country. This would mean that sending
an e-mail to your neighbor would first have to go to the central mail server,
which may be hundreds of miles away. Clearly, this is not the way to go.
[Page 12]
Finally, a difficult, and in
many cases open question is how to scale a distributed system across multiple,
independent administrative domains. A major problem that needs to be solved is
that of conflicting policies with respect to resource usage (and payment),
management, and security.
For example, many components
of a distributed system that reside within a single domain can often be trusted
by users that operate within that same domain. In such cases, system
administration may have tested and certified applications, and may have taken
special measures to ensure that such components cannot be tampered with. In
essence, the users trust their system administrators. However, this trust does
not expand naturally across domain boundaries.
If a distributed system expands
into another domain, two types of security measures need to be taken. First of
all, the distributed system has to protect itself against malicious attacks
from the new domain. For example, users from the new domain may have only read
access to the file system in its original domain. Likewise, facilities such as
expensive image setters or high-performance computers may not be made available
to foreign users. Second, the new domain has to protect itself against
malicious attacks from the distributed system. A typical example is that of
downloading programs such as applets in Web browsers. Basically, the new domain
does not know behavior what to expect from such foreign code, and may therefore
decide to severely limit the access rights for such code. The problem, as we
shall see in Chap. 9, is how to enforce those limitations.
Scaling Techniques
Having discussed some of the
scalability problems brings us to the question of how those problems can
generally be solved. In most cases, scalability problems in distributed systems
appear as performance problems caused by limited capacity of servers and
network. There are now basically only three techniques for scaling: hiding
communication latencies, distribution, and replication [see also Neuman
(1994)].
Hiding communication
latencies is important to achieve geographical scalability. The basic idea is
simple: try to avoid waiting for responses to remote (and potentially distant)
service requests as much as possible. For example, when a service has been
requested at a remote machine, an alternative to waiting for a reply from the
server is to do other useful work at the requester's side. Essentially, what
this means is constructing the requesting application in such a way that it
uses only asynchronous communication. When a reply comes in, the application is
interrupted and a special handler is called to complete the previously-issued
request. Asynchronous communication can often be used in batch-processing
systems and parallel applications, in which more or less independent tasks can
be scheduled for execution while another task is waiting for communication to
complete. Alternatively, a new thread of control can be started to perform the
request. Although it blocks waiting for the reply, other threads in the process
can continue.
[Page 13]
However, there are many
applications that cannot make effective use of asynchronous communication. For
example, in interactive applications when a user sends a request he will generally
have nothing better to do than to wait for the answer. In such cases, a much
better solution is to reduce the overall communication, for example, by moving
part of the computation that is normally done at the server to the client
process requesting the service. A typical case where this approach works is
accessing databases using forms. Filling in forms can be done by sending a
separate message for each field, and waiting for an acknowledgment from the
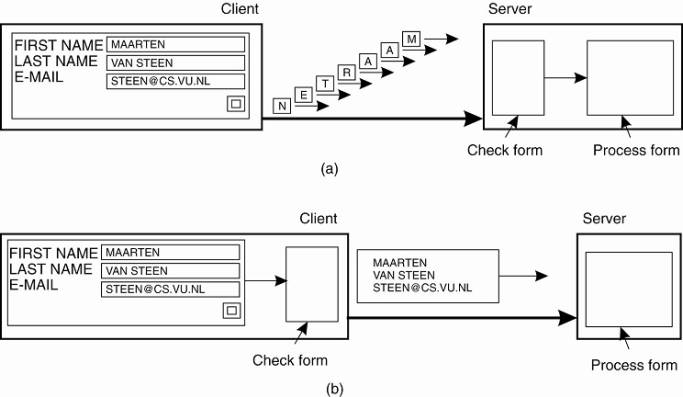
server, as shown in Fig. 1-4(a). For example, the server may check for
syntactic errors before accepting an entry. A much better solution is to ship
the code for filling in the form, and possibly checking the entries, to the
client, and have the client return a completed form, as shown in Fig. 1-4(b).
This approach of shipping code is now widely supported by the Web in the form
of Java applets and Javascript.
Figure 1-4. The difference
between letting (a) a server or (b) a client check forms as they are being
filled.
Another important scaling
technique is distribution. Distribution involves taking a component, splitting
it into smaller parts, and subsequently spreading those parts across the
system. An excellent example of distribution is the Internet Domain Name System
(DNS). The DNS name space is hierarchically organized into a tree of domains,
which are divided into nonoverlapping zones, as shown in Fig. 1-5. The names in
each zone are handled by a single name server. Without going into too many
details, one can think of each path name being the name of a host in the
Internet, and thus associated with a network address of that host. Basically,
resolving a name means returning the network address of the associated host.
Consider, for example, the name nl.vu.cs.flits. To resolve this name, it is
first passed to the server of zone Z1 (see Fig. 1-5) which returns the address
of the server for zone Z2, to which the rest of name, vu.cs.flits, can be
handed. The server for Z2 will return the address of the server for zone Z3, which
is capable of handling the last part of the name and will return the address of
the associated host.
[Page 14]
Figure 1-5. An example of
dividing the DNS name space into zones.
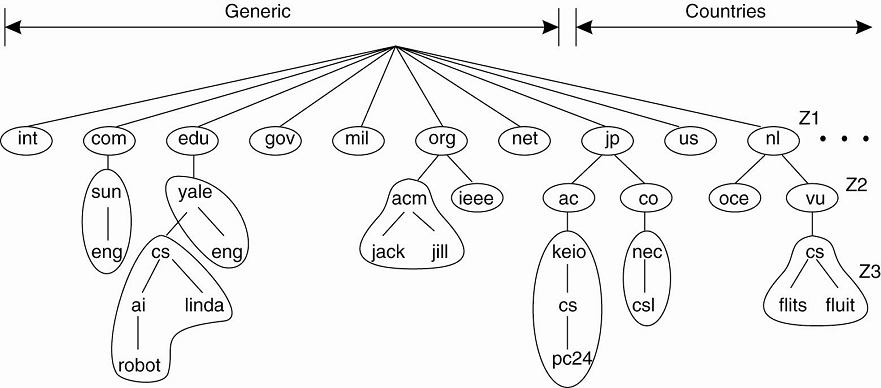
This example illustrates how
the naming service, as provided by DNS, is distributed across several machines,
thus avoiding that a single server has to deal with all requests for name
resolution.
As another example, consider
the World Wide Web. To most users, the Web appears to be an enormous document-based
information system in which each document has its own unique name in the form
of a URL. Conceptually, it may even appear as if there is only a single server.
However, the Web is physically distributed across a large number of servers,
each handling a number of Web documents. The name of the server handling a
document is encoded into that document's URL. It is only because of this
distribution of documents that the Web has been capable of scaling to its
current size.
Considering that scalability
problems often appear in the form of performance degradation, it is generally a
good idea to actually replicate components across a distributed system.
Replication not only increases availability, but also helps to balance the load
between components leading to better performance. Also, in geographically
widely-dispersed systems, having a copy nearby can hide much of the
communication latency problems mentioned before.
[Page 15]
Caching is a special form of
replication, although the distinction between the two is often hard to make or
even artificial. As in the case of replication, caching results in making a
copy of a resource, generally in the proximity of the client accessing that
resource. However, in contrast to replication, caching is a decision made by
the client of a resource, and not by the owner of a resource. Also, caching
happens on demand whereas replication is often planned in advance.
There is one serious
drawback to caching and replication that may adversely affect scalability. Because
we now have multiple copies of a resource, modifying one copy makes that copy
different from the others. Consequently, caching and replication leads to
consistency problems.
To what extent
inconsistencies can be tolerated depends highly on the usage of a resource. For
example, many Web users find it acceptable that their browser returns a cached
document of which the validity has not been checked for the last few minutes.
However, there are also many cases in which strong consistency guarantees need
to be met, such as in the case of electronic stock exchanges and auctions. The
problem with strong consistency is that an update must be immediately
propagated to all other copies. Moreover, if two updates happen concurrently,
it is often also required that each copy is updated in the same order.
Situations such as these generally require some global synchronization
mechanism. Unfortunately, such mechanisms are extremely hard or even impossible
to implement in a scalable way, as she insists that photons and electrical
signals obey a speed limit of 187 miles/msec (the speed of light).
Consequently, scaling by replication may introduce other, inherently
nonscalable solutions. We return to replication and consistency in Chap. 7.
When considering these
scaling techniques, one could argue that size scalability is the least
problematic from a technical point of view. In many cases, simply increasing
the capacity of a machine will the save the day (at least temporarily and
perhaps at significant costs). Geographical scalability is a much tougher
problem as Mother Nature is getting in our way. Nevertheless, practice shows
that combining distribution, replication, and caching techniques with different
forms of consistency will often prove sufficient in many cases. Finally,
administrative scalability seems to be the most difficult one, partly also
because we need to solve nontechnical problems (e.g., politics of organizations
and human collaboration). Nevertheless, progress has been made in this area, by
simply ignoring administrative domains. The introduction and now widespread use
of peer-to-peer technology demonstrates what can be achieved if end users
simply take over control (Aberer and Hauswirth, 2005; Lua et al., 2005; and
Oram, 2001). However, let it be clear that peer-to-peer technology can at best
be only a partial solution to solving administrative scalability. Eventually,
it will have to be dealt with.
[Page 16]
1.2.5. Pitfalls
It should be clear by now
that developing distributed systems can be a formidable task. As we will see
many times throughout this book, there are so many issues to consider at the
same time that it seems that only complexity can be the result. Nevertheless,
by following a number of design principles, distributed systems can be developed
that strongly adhere to the goals we set out in this chapter. Many principles
follow the basic rules of decent software engineering and will not be repeated
here.
However, distributed systems
differ from traditional software because components are dispersed across a
network. Not taking this dispersion into account during design time is what
makes so many systems needlessly complex and results in mistakes that need to
be patched later on. Peter Deutsch, then at Sun Microsystems, formulated these
mistakes as the following false assumptions that everyone makes when developing
a distributed application for the first time:
- The network is reliable.
- The network is secure.
- The network is homogeneous.
- The topology does not change.
- Latency is zero.
- Bandwidth is infinite.
- Transport cost is zero.
- There is one administrator.
Note how these assumptions
relate to properties that are unique to distributed systems: reliability,
security, heterogeneity, and topology of the network; latency and bandwidth; transport
costs; and finally administrative domains. When developing nondistributed
applications, many of these issues will most likely not show up.
Most of the principles we
discuss in this book relate immediately to these assumptions. In all cases, we
will be discussing solutions to problems that are caused by the fact that one
or more assumptions are false. For example, reliable networks simply do not
exist, leading to the impossibility of achieving failure transparency. We
devote an entire chapter to deal with the fact that networked communication is
inherently insecure. We have already argued that distributed systems need to
take heterogeneity into account. In a similar vein, when discussing replication
for solving scalability problems, we are essentially tackling latency and
bandwidth problems. We will also touch upon management issues at various points
throughout this book, dealing with the false assumptions of zero-cost
transportation and a single administrative domain.
1.3. Types of Distributed Systems
Before starting to discuss
the principles of distributed systems, let us first take a closer look at the
various types of distributed systems. In the following we make a distinction
between distributed computing systems, distributed information systems, and
distributed embedded systems.
1.3.1. Distributed Computing Systems
An important class of
distributed systems is the one used for high-performance computing tasks.
Roughly speaking, one can make a distinction between two subgroups. In cluster
computing the underlying hardware consists of a collection of similar
workstations or PCs, closely connected by means of a high-speed local-area
network. In addition, each node runs the same operating system.
The situation becomes quite
different in the case of grid computing. This subgroup consists of distributed
systems that are often constructed as a federation of computer systems, where
each system may fall under a different administrative domain, and may be very
different when it comes to hardware, software, and deployed network technology.
Cluster Computing Systems
Cluster computing systems
became popular when the price/performance ratio of personal computers and
workstations improved. At a certain point, it became financially and
technically attractive to build a supercomputer using off-the-shelf technology
by simply hooking up a collection of relatively simple computers in a
high-speed network. In virtually all cases, cluster computing is used for
parallel programming in which a single (compute intensive) program is run in
parallel on multiple machines.
[Page 18]
One well-known example of a
cluster computer is formed by Linux-based Beowulf clusters, of which the
general configuration is shown in Fig. 1-6. Each cluster consists of a
collection of compute nodes that are controlled and accessed by means of a
single master node. The master typically handles the allocation of nodes to a
particular parallel program, maintains a batch queue of submitted jobs, and
provides an interface for the users of the system. As such, the master actually
runs the middleware needed for the execution of programs and management of the
cluster, while the compute nodes often need nothing else but a standard
operating system.
Figure 1-6. An example of a
cluster computing system.
(This item is displayed on
page 17 in the print version)

An important part of this
middleware is formed by the libraries for executing parallel programs. As we will
discuss in Chap. 4, many of these libraries effectively provide only advanced
message-based communication facilities, but are not capable of handling faulty
processes, security, etc.
As an alternative to this
hierarchical organization, a symmetric approach is followed in the MOSIX system
(Amar et al., 2004). MOSIX attempts to provide a single-system image of a
cluster, meaning that to a process a cluster computer offers the ultimate
distribution transparency by appearing to be a single computer. As we
mentioned, providing such an image under all circumstances is impossible. In
the case of MOSIX, the high degree of transparency is provided by allowing
processes to dynamically and preemptively migrate between the nodes that make
up the cluster. Process migration allows a user to start an application on any
node (referred to as the home node), after which it can transparently move to
other nodes, for example, to make efficient use of resources. We will return to
process migration in Chap. 3.
Grid Computing Systems
A characteristic feature of
cluster computing is its homogeneity. In most cases, the computers in a cluster
are largely the same, they all have the same operating system, and are all
connected through the same network. In contrast, grid computing systems have a
high degree of heterogeneity: no assumptions are made concerning hardware,
operating systems, networks, administrative domains, security policies, etc.
A key issue in a grid
computing system is that resources from different organizations are brought
together to allow the collaboration of a group of people or institutions. Such
a collaboration is realized in the form of a virtual organization. The people
belonging to the same virtual organization have access rights to the resources
that are provided to that organization. Typically, resources consist of compute
servers (including supercomputers, possibly implemented as cluster computers),
storage facilities, and databases. In addition, special networked devices such
as telescopes, sensors, etc., can be provided as well.
Given its nature, much of
the software for realizing grid computing evolves around providing access to
resources from different administrative domains, and to only those users and
applications that belong to a specific virtual organization. For this reason,
focus is often on architectural issues. An architecture proposed by Foster et
al. (2001). is shown in Fig. 1-7
[Page 19]
Figure 1-7. A layered
architecture for grid computing systems.
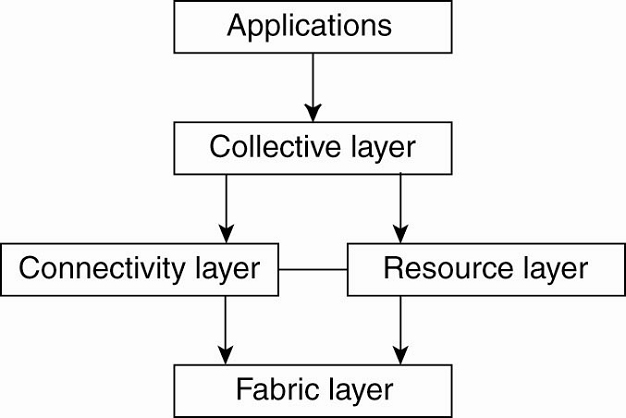
The architecture consists of
four layers. The lowest fabric layer provides interfaces to local resources at
a specific site. Note that these interfaces are tailored to allow sharing of
resources within a virtual organization. Typically, they will provide functions
for querying the state and capabilities of a resource, along with functions for
actual resource management (e.g., locking resources).
The connectivity layer
consists of communication protocols for supporting grid transactions that span
the usage of multiple resources. For example, protocols are needed to transfer
data between resources, or to simply access a resource from a remote location.
In addition, the connectivity layer will contain security protocols to
authenticate users and resources. Note that in many cases human users are not
authenticated; instead, programs acting on behalf of the users are
authenticated. In this sense, delegating rights from a user to programs is an
important function that needs to be supported in the connectivity layer. We
return extensively to delegation when discussing security in distributed
systems.
The resource layer is
responsible for managing a single resource. It uses the functions provided by
the connectivity layer and calls directly the interfaces made available by the
fabric layer. For example, this layer will offer functions for obtaining
configuration information on a specific resource, or, in general, to perform
specific operations such as creating a process or reading data. The resource
layer is thus seen to be responsible for access control, and hence will rely on
the authentication performed as part of the connectivity layer.
The next layer in the
hierarchy is the collective layer. It deals with handling access to multiple
resources and typically consists of services for resource discovery, allocation
and scheduling of tasks onto multiple resources, data replication, and so on.
Unlike the connectivity and resource layer, which consist of a relatively
small, standard collection of protocols, the collective layer may consist of
many different protocols for many different purposes, reflecting the broad
spectrum of services it may offer to a virtual organization.
[Page 20]
Finally, the application
layer consists of the applications that operate within a virtual organization
and which make use of the grid computing environment.
Typically the collective,
connectivity, and resource layer form the heart of what could be called a grid
middleware layer. These layers jointly provide access to and management of
resources that are potentially dispersed across multiple sites. An important
observation from a middleware perspective is that with grid computing the
notion of a site (or administrative unit) is common. This prevalence is
emphasized by the gradual shift toward a service-oriented architecture in which
sites offer access to the various layers through a collection of Web services
(Joseph et al., 2004). This, by now, has led to the definition of an
alternative architecture known as the Open Grid Services Architecture (OGSA).
This architecture consists of various layers and many components, making it
rather complex. Complexity seems to be the fate of any standardization process.
Details on OGSA can be found in Foster et al. (2005).
1.3.2. Distributed Information Systems
Another important class of
distributed systems is found in organizations that were confronted with a
wealth of networked applications, but for which interoperability turned out to
be a painful experience. Many of the existing middleware solutions are the result
of working with an infrastructure in which it was easier to integrate
applications into an enterprise-wide information system (Bernstein, 1996; and
Alonso et al., 2004).
We can distinguish several
levels at which integration took place. In many cases, a networked application
simply consisted of a server running that application (often including a
database) and making it available to remote programs, called clients. Such
clients could send a request to the server for executing a specific operation,
after which a response would be sent back. Integration at the lowest level
would allow clients to wrap a number of requests, possibly for different
servers, into a single larger request and have it executed as a distributed
transaction. The key idea was that all, or none of the requests would be
executed.
As applications became more
sophisticated and were gradually separated into independent components (notably
distinguishing database components from processing components), it became clear
that integration should also take place by letting applications communicate
directly with each other. This has now led to a huge industry that concentrates
on enterprise application integration (EAI). In the following, we concentrate
on these two forms of distributed systems.
Transaction Processing
Systems
To clarify our discussion,
let us concentrate on database applications. In practice, operations on a
database are usually carried out in the form of transactions. Programming using
transactions requires special primitives that must either be supplied by the
underlying distributed system or by the language runtime system. Typical
examples of transaction primitives are shown in Fig. 1-8. The exact list of
primitives depends on what kinds of objects are being used in the transaction
(Gray and Reuter, 1993). In a mail system, there might be primitives to send,
receive, and forward mail. In an accounting system, they might be quite
different. READ and WRITE are typical examples, however. Ordinary statements,
procedure calls, and so on, are also allowed inside a transaction. In
particular, we mention that remote procedure calls (RPCs), that is, procedure
calls to remote servers, are often also encapsulated in a transaction, leading
to what is known as a transactional RPC. We discuss RPCs extensively in Chap.
4.
[Page 21]
Figure 1-8. Example
primitives for transactions.
|
Primitive |
Description |
|
BEGIN_TRANSACTION |
Mark the start of a
transaction |
|
END_TRANSACTION |
Terminate the transaction
and try to commit |
|
ABORT_TRANSACTION |
Kill the transaction and
restore the old values |
|
READ |
Read data from a file, a
table, or otherwise |
|
WRITE |
Write data to a file, a
table, or otherwise |
BEGIN_TRANSACTION and END_TRANSACTION
are used to delimit the scope of a transaction. The operations between them
form the body of the transaction. The characteristic feature of a transaction
is either all of these operations are executed or none are executed. These may
be system calls, library procedures, or bracketing statements in a language,
depending on the implementation.
This all-or-nothing property
of transactions is one of the four characteristic properties that transactions
have. More specifically, transactions are:
- Atomic: To the outside world, the transaction
happens indivisibly.
- Consistent: The transaction does not violate
system invariants.
- Isolated: Concurrent transactions do not
interfere with each other.
- Durable: Once a transaction commits, the changes
are permanent.
These properties are often
referred to by their initial letters: ACID.
The first key property
exhibited by all transactions is that they are atomic. This property ensures
that each transaction either happens completely, or not at all, and if it
happens, it happens in a single indivisible, instantaneous action. While a
transaction is in progress, other processes (whether or not they are themselves
involved in transactions) cannot see any of the intermediate states.
The second property says
that they are consistent. What this means is that if the system has certain
invariants that must always hold, if they held before the transaction, they
will hold afterward too. For example, in a banking system, a key invariant is
the law of conservation of money. After every internal transfer, the amount of
money in the bank must be the same as it was before the transfer, but for a
brief moment during the transaction, this invariant may be violated. The
violation is not visible outside the transaction, however.
[Page 22]
The third property says that
transactions are isolated or serializable. What it means is that if two or more
transactions are running at the same time, to each of them and to other
processes, the final result looks as though all transactions ran sequentially
in some (system dependent) order.
The fourth property says
that transactions are durable. It refers to the fact that once a transaction
commits, no matter what happens, the transaction goes forward and the results
become permanent. No failure after the commit can undo the results or cause
them to be lost. (Durability is discussed extensively in Chap. 8.)
So far, transactions have
been defined on a single database. A nested transaction is constructed from a
number of subtransactions, as shown in Fig. 1-9. The top-level transaction may
fork off children that run in parallel with one another, on different machines,
to gain performance or simplify programming. Each of these children may also
execute one or more subtransactions, or fork off its own children.
Figure 1-9. A nested
transaction.
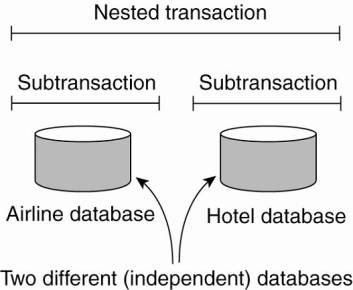
Subtransactions give rise to
a subtle, but important, problem. Imagine that a transaction starts several
subtransactions in parallel, and one of these commits, making its results
visible to the parent transaction. After further computation, the parent
aborts, restoring the entire system to the state it had before the top-level
transaction started. Consequently, the results of the subtransaction that
committed must nevertheless be undone. Thus the permanence referred to above
applies only to top-level transactions.
Since transactions can be
nested arbitrarily deeply, considerable administration is needed to get
everything right. The semantics are clear, however. When any transaction or
subtransaction starts, it is conceptually given a private copy of all data in
the entire system for it to manipulate as it wishes. If it aborts, its private
universe just vanishes, as if it had never existed. If it commits, its private
universe replaces the parent's universe. Thus if a subtransaction commits and
then later a new subtransaction is started, the second one sees the results
produced by the first one. Likewise, if an enclosing (higher-level) transaction
aborts, all its underlying subtransactions have to be aborted as well.
[Page 23]
Nested transactions are
important in distributed systems, for they provide a natural way of
distributing a transaction across multiple machines. They follow a logical
division of the work of the original transaction. For example, a transaction
for planning a trip by which three different flights need to be reserved can be
logically split up into three subtransactions. Each of these subtransactions
can be managed separately and independent of the other two.
In the early days of
enterprise middleware systems, the component that handled distributed (or
nested) transactions formed the core for integrating applications at the server
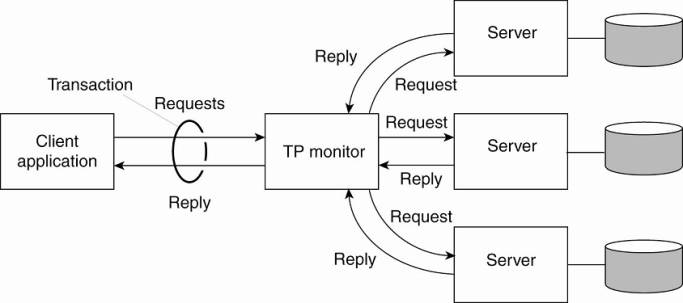
or database level. This component was called a transaction processing monitor
or TP monitor for short. Its main task was to allow an application to access
multiple server/databases by offering it a transactional programming model, as
shown in Fig. 1-10.
Figure 1-10. The role of a
TP monitor in distributed systems.
Enterprise Application Integration
As mentioned, the more
applications became decoupled from the databases they were built upon, the more
evident it became that facilities were needed to integrate applications
independent from their databases. In particular, application components should be
able to communicate directly with each other and not merely by means of the
request/reply behavior that was supported by transaction processing systems.
This need for
interapplication communication led to many different communication models,
which we will discuss in detail in this book (and for which reason we shall
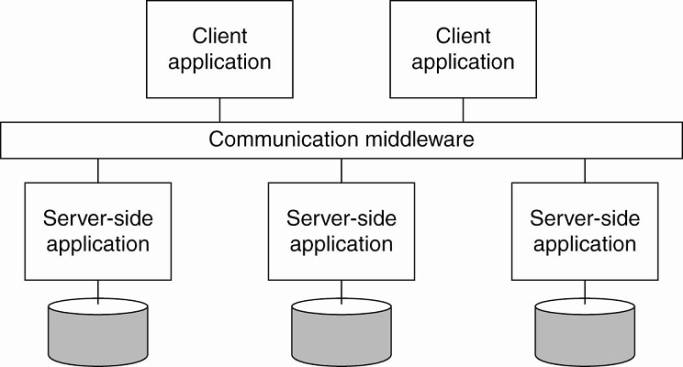
keep it brief for now). The main idea was that existing applications could
directly exchange information, as shown in Fig. 1-11.
[Page 24]
Figure 1-11. Middleware as a
communication facilitator in enterprise application integration.
Several types of
communication middleware exist. With remote procedure calls (RPC), an
application component can effectively send a request to another application
component by doing a local procedure call, which results in the request being
packaged as a message and sent to the callee. Likewise, the result will be sent
back and returned to the application as the result of the procedure call.
As the popularity of object
technology increased, techniques were developed to allow calls to remote
objects, leading to what is known as remote method invocations (RMI). An RMI is
essentially the same as an RPC, except that it operates on objects instead of
applications.
RPC and RMI have the
disadvantage that the caller and callee both need to be up and running at the
time of communication. In addition, they need to know exactly how to refer to
each other. This tight coupling is often experienced as a serious drawback, and
has led to what is known as message-oriented middleware, or simply MOM. In this
case, applications simply send messages to logical contact points, often
described by means of a subject. Likewise, applications can indicate their
interest for a specific type of message, after which the communication middleware
will take care that those messages are delivered to those applications. These
so-called publish/subscribe systems form an important and expanding class of
distributed systems. We will discuss them at length in Chap. 13.
1.3.3. Distributed Pervasive
Systems
The distributed systems we
have been discussing so far are largely characterized by their stability: nodes
are fixed and have a more or less permanent and high-quality connection to a
network. To a certain extent, this stability has been realized through the
various techniques that are discussed in this book and which aim at achieving
distribution transparency. For example, the wealth of techniques for masking
failures and recovery will give the impression that only occasionally things
may go wrong. Likewise, we have been able to hide aspects related to the actual
network location of a node, effectively allowing users and applications to
believe that nodes stay put.
[Page 25]
However, matters have become
very different with the introduction of mobile and embedded computing devices.
We are now confronted with distributed systems in which instability is the
default behavior. The devices in these, what we refer to as distributed
pervasive systems, are often characterized by being small, battery-powered,
mobile, and having only a wireless connection, although not all these
characteristics apply to all devices. Moreover, these characteristics need not
necessarily be interpreted as restrictive, as is illustrated by the
possibilities of modern smart phones (Roussos et al., 2005).
As its name suggests, a
distributed pervasive system is part of our surroundings (and as such, is
generally inherently distributed). An important feature is the general lack of
human administrative control. At best, devices can be configured by their
owners, but otherwise they need to automatically discover their environment and
"nestle in" as best as possible. This nestling in has been made more
precise by Grimm et al. (2004) by formulating the following three requirements
for pervasive applications:
- Embrace contextual changes.
- Encourage ad hoc composition.
- Recognize sharing as the default.
Embracing contextual changes
means that a device must be continuously be aware of the fact that its
environment may change all the time. One of the simplest changes is discovering
that a network is no longer available, for example, because a user is moving
between base stations. In such a case, the application should react, possibly
by automatically connecting to another network, or taking other appropriate
actions.
Encouraging ad hoc
composition refers to the fact that many devices in pervasive systems will be
used in very different ways by different users. As a result, it should be easy
to configure the suite of applications running on a device, either by the user
or through automated (but controlled) interposition.
One very important aspect of
pervasive systems is that devices generally join the system in order to access
(and possibly provide) information. This calls for means to easily read, store,
manage, and share information. In light of the intermittent and changing
connectivity of devices, the space where accessible information resides will
most likely change all the time.
Mascolo et al. (2004) as
well as Niemela and Latvakoski (2004) came to similar conclusions: in the
presence of mobility, devices should support easy and application-dependent
adaptation to their local environment. They should be able to efficiently
discover services and react accordingly. It should be clear from these
requirements that distribution transparency is not really in place in pervasive
systems. In fact, distribution of data, processes, and control is inherent to
these systems, for which reason it may be better just to simply expose it
rather than trying to hide it. Let us now take a look at some concrete examples
of pervasive systems.
[Page 26]
Home Systems
An increasingly popular type
of pervasive system, but which may perhaps be the least constrained, are systems
built around home networks. These systems generally consist of one or more
personal computers, but more importantly integrate typical consumer electronics
such as TVs, audio and video equipment, gaming devices, (smart) phones, PDAs,
and other personal wearables into a single system. In addition, we can expect
that all kinds of devices such as kitchen appliances, surveillance cameras,
clocks, controllers for lighting, and so on, will all be hooked up into a
single distributed system.
From a system's perspective
there are several challenges that need to be addressed before pervasive home
systems become reality. An important one is that such a system should be
completely self-configuring and self-managing. It cannot be expected that end
users are willing and able to keep a distributed home system up and running if
its components are prone to errors (as is the case with many of today's
devices.) Much has already been accomplished through the Universal Plug and
Play (UPnP) standards by which devices automatically obtain IP addresses, can
discover each other, etc. (UPnP Forum, 2003). However, more is needed. For
example, it is unclear how software and firmware in devices can be easily
updated without manual intervention, or when updates do take place, that compatibility
with other devices is not violated.
Another pressing issue is
managing what is known as a "personal space." Recognizing that a home
system consists of many shared as well as personal devices, and that the data
in a home system is also subject to sharing restrictions, much attention is
paid to realizing such personal spaces. For example, part of Alice's personal
space may consist of her agenda, family photo's, a diary, music and videos that
she bought, etc. These personal assets should be stored in such a way that
Alice has access to them whenever appropriate. Moreover, parts of this personal
space should be (temporarily) accessible to others, for example, when she needs
to make a business appointment.
Fortunately, things may
become simpler. It has long been thought that the personal spaces related to
home systems were inherently distributed across the various devices. Obviously,
such a dispersion can easily lead to significant synchronization problems.
However, problems may be alleviated due to the rapid increase in the capacity
of hard disks, along with a decrease in their size. Configuring a
multi-terabyte storage unit for a personal computer is not really a problem. At
the same time, portable hard disks having a capacity of hundreds of gigabytes
are being placed inside relatively small portable media players. With these
continuously increasing capacities, we may see pervasive home systems adopt an
architecture in which a single machine acts as a master (and is hidden away
somewhere in the basement next to the central heating), and all other fixed
devices simply provide a convenient interface for humans. Personal devices will
then be crammed with daily needed information, but will never run out of
storage.
[Page 27]
However, having enough
storage does not solve the problem of managing personal spaces. Being able to
store huge amounts of data shifts the problem to storing relevant data and
being able to find it later. Increasingly we will see pervasive systems, like
home networks, equipped with what are called recommenders, programs that
consult what other users have stored in order to identify similar taste, and
from that subsequently derive which content to place in one's personal space.
An interesting observation is that the amount of information that recommender
programs need to do their work is often small enough to allow them to be run on
PDAs (Miller et al., 2004).
Electronic Health Care
Systems
Another important and upcoming
class of pervasive systems are those related to (personal) electronic health
care. With the increasing cost of medical treatment, new devices are being
developed to monitor the well-being of individuals and to automatically contact
physicians when needed. In many of these systems, a major goal is to prevent
people from being hospitalized.
Personal health care systems
are often equipped with various sensors organized in a (preferably wireless)
body-area network (BAN). An important issue is that such a network should at
worst only minimally hinder a person. To this end, the network should be able
to operate while a person is moving, with no strings (i.e., wires) attached to
immobile devices.
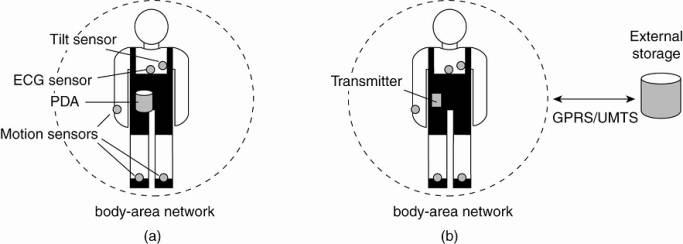
This requirement leads to
two obvious organizations, as shown in Fig. 1-12. In the first one, a central
hub is part of the BAN and collects data as needed. From time to time, this
data is then offloaded to a larger storage device. The advantage of this scheme
is that the hub can also manage the BAN. In the second scenario, the BAN is
continuously hooked up to an external network, again through a wireless
connection, to which it sends monitored data. Separate techniques will need to
be deployed for managing the BAN. Of course, further connections to a physician
or other people may exist as well.
Figure 1-12. Monitoring a
person in a pervasive electronic health care system, using (a) a local hub or
(b) a continuous wireless connection.
(This item is displayed on
page 28 in the print version)
From a distributed system's
perspective we are immediately confronted with questions such as:
1. Where and how should monitored data be stored?
2. How can we prevent loss of crucial data?
3. What infrastructure is needed to generate and propagate alerts?
[Page 28]
4. How can physicians provide online feedback?
5. How can extreme robustness of the monitoring system be
realized?
6. What are the security issues and how can the proper policies
be enforced?
Unlike home systems, we
cannot expect the architecture of pervasive health care systems to move toward
single-server systems and have the monitoring devices operate with minimal
functionality. On the contrary: for reasons of efficiency, devices and
body-area networks will be required to support in-network data processing,
meaning that monitoring data will, for example, have to be aggregated before
permanently storing it or sending it to a physician. Unlike the case for
distributed information systems, there is yet no clear answer to these questions.
Sensor Networks
Our last example of
pervasive systems is sensor networks. These networks in many cases form part of
the enabling technology for pervasiveness and we see that many solutions for
sensor networks return in pervasive applications. What makes sensor networks
interesting from a distributed system's perspective is that in virtually all
cases they are used for processing information. In this sense, they do more
than just provide communication services, which is what traditional computer
networks are all about. Akyildiz et al. (2002) provide an overview from a
networking perspective. A more systems-oriented introduction to sensor networks
is given by Zhao and Guibas (2004). Strongly related are mesh networks which
essentially form a collection of (fixed) nodes that communicate through
wireless links. These networks may form the basis for many medium-scale
distributed systems. An overview is provided in Akyildiz et al. (2005).
[Page 29]
A sensor network typically
consists of tens to hundreds or thousands of relatively small nodes, each
equipped with a sensing device. Most sensor networks use wireless
communication, and the nodes are often battery powered. Their limited
resources, restricted communication capabilities, and constrained power
consumption demand that efficiency be high on the list of design criteria.
The relation with
distributed systems can be made clear by considering sensor networks as
distributed databases. This view is quite common and easy to understand when
realizing that many sensor networks are deployed for measurement and
surveillance applications (Bonnet et al., 2002). In these cases, an operator
would like to extract information from (a part of) the network by simply issuing
queries such as "What is the northbound traffic load on Highway 1?"
Such queries resemble those of traditional databases. In this case, the answer
will probably need to be provided through collaboration of many sensors located
around Highway 1, while leaving other sensors untouched.
To organize a sensor network
as a distributed database, there are essentially two extremes, as shown in Fig.
1-13. First, sensors do not cooperate but simply send their data to a
centralized database located at the operator's site. The other extreme is to
forward queries to relevant sensors and to let each compute an answer,
requiring the operator to sensibly aggregate the returned answers.
Figure 1-13. Organizing a
sensor network database, while storing and processing data (a) only at the
operator's site or (b) only at the sensors.
(This item is displayed on
page 30 in the print version)
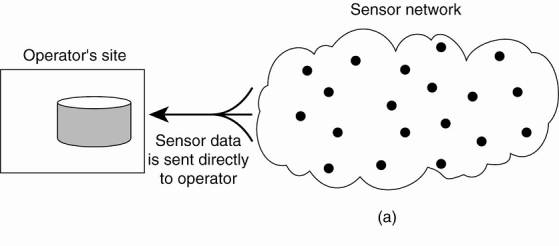
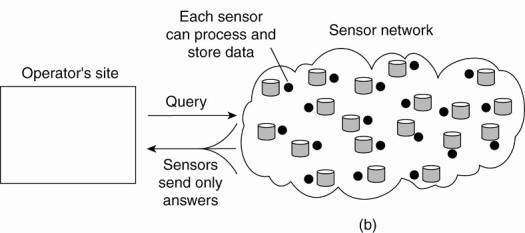
Neither of these solutions
is very attractive. The first one requires that sensors send all their measured
data through the network, which may waste network resources and energy. The
second solution may also be wasteful as it discards the aggregation
capabilities of sensors which would allow much less data to be returned to the
operator. What is needed are facilities for in-network data processing, as we
also encountered in pervasive health care systems.
In-network processing can be
done in numerous ways. One obvious one is to forward a query to all sensor
nodes along a tree encompassing all nodes and to subsequently aggregate the
results as they are propagated back to the root, where the initiator is
located. Aggregation will take place where two or more branches of the tree
come to together. As simple as this scheme may sound, it introduces difficult
questions:
1. How do we (dynamically) set up an efficient tree in a sensor
network?
2. How does aggregation of results take place? Can it be
controlled?
3. What happens when network links fail?
These questions have been
partly addressed in TinyDB, which implements a declarative (database) interface
to wireless sensor networks. In essence, TinyDB can use any tree-based routing
algorithm. An intermediate node will collect and aggregate the results from its
children, along with its own findings, and send that toward the root. To make
matters efficient, queries span a period of time allowing for careful
scheduling of operations so that network resources and energy are optimally
consumed. Details can be found in Madden et al. (2005).
[Page 30]
However, when queries can be
initiated from different points in the network, using single-rooted trees such
as in TinyDB may not be efficient enough. As an alternative, sensor networks
may be equipped with special nodes where results are forwarded to, as well as
the queries related to those results. To give a simple example, queries and
results related temperature readings are collected at a different location than
those related to humidity measurements. This approach corresponds directly to
the notion of publish/subscribe systems, which we will discuss extensively in
Chap. 13.