| CS615 Software
Engineering I |
| Lecture
7 |
Chapter 17 - Software Testing Techniques
Software Testing Objectives
-
Testing is the process of executing a program with the intent of finding
errors.
-
A good test case is one with a high probability of finding an as-yet undiscovered
error.
-
A successful test is one that discovers an as-yet-undiscovered error.
Software Testing Principles
-
All tests should be traceable to customer requirements.
-
Tests should be planned long before testing begins.
-
The Pareto principle (80% of all errors will likely be found in 20% of
the code) applies to software testing.
-
Testing should begin in the small and progress to the large.
-
Exhaustive testing is not possible.
-
To be most effective, testing should be conducted by an independent third
party.
Software Testability Checklist
-
Operability (the better it works the more efficiently it can be
tested)
-
Observabilty (what you see is what you test)
-
Distinct output is generated for each input.
-
System states and variables are visible or queriable during execution.
-
Past system states and variables are visible or queriable (e.g., transaction
logs).
-
All factors affecting the output are visible.
-
Incorrect output is easily identified.
-
Internal errors are automatically detected through self-testing mechanisms.
-
Internal errors are automatically reported.
-
Source code is accessible.
-
Controllability (the better software can be controlled the more
testing can be automated and optimized)
-
All possible outputs can be generated through some combination of input.
-
All code is executable through some combination of input.
-
Software and hardware states and variables can be controlled directly by
the test engineer.
-
Input and output formats are consistent and structured.
-
Tests can be conveniently specified, automated, and reproduced
-
Decomposability (by controlling the scope of testing, the more quickly
problems can be isolated and retested intelligently)
-
The software system is built from independent modules.
-
Software modules can be tested independently
-
Simplicity (the less there is to test, the more quickly we can test)
-
Functional simplicity (e.g., the feature set is the minimum necessary to
meet requirements).
-
Structural simplicity (e.g., architecture is modularized to limit the propagation
of faults).
-
Code simplicity (e.g., a coding standard is adopted for ease of inspection
and maintenance).
-
Stability (the fewer the changes, the fewer the disruptions to testing)
-
Changes to the software are infrequent.
-
Changes to the software are controlled.
-
Changes to the software do not invalidate existing tests.
-
The software recovers well from failures.
-
Understandability (the more information known, the smarter the testing)
-
The design is well understood.
-
Dependencies between internal, external, and shared components are well
understood.
-
Changes to the design are communicated.
-
Technical documentation is instantly accessible.
-
Technical documentation is well organized.
-
Technical documentation is specific and detailed.
-
Technical documentation is accurate.
Good Test Attributes
-
A good test has a high probability of finding an error.
-
A good test is not redundant.
-
A good test should be best of breed.
-
A good test should not be too simple or too complex.
Test Case Design Strategies
-
Black-box or behavioral testing (knowing the specified function
a product is to perform and demonstrating correct operation based solely
on its specification without regard for its internal logic)
-
White-box or glass-box testing (knowing the internal workings of
a product, tests are performed to check the workings of all independent
logic paths)
Basis Path Testing
-
White-box technique usually based on the program flow graph
-
The cyclomatic complexity of the program computed from its flow
graph using the formula V(G) = E - N + 2 or by counting the conditional
statements in the PDL representation and adding 1
-
Determine the basis set of linearly independent paths (the cardinality
of this set id the program cyclomatic complexity)
-
Prepare test cases that will force the execution of each path in the basis
set.
Flow graph - depicts
logical control flow
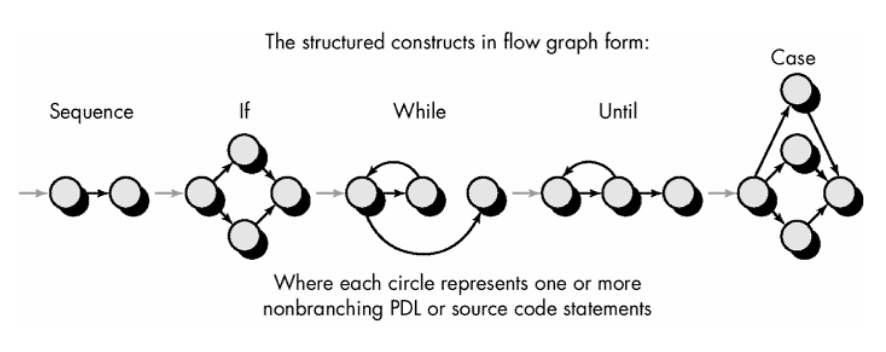
Example - Mapping flowchart into a corresponding flow graph
Flow Graph Composition
-
Circle - flow graph node - represents one or more procedural
statements
-
Arrow - edges or links - represent flow of control and are analogous
to flowchart arrows
-
An edge must terminate at a node
-
Regions - Areas bounded by edges and nodes
-
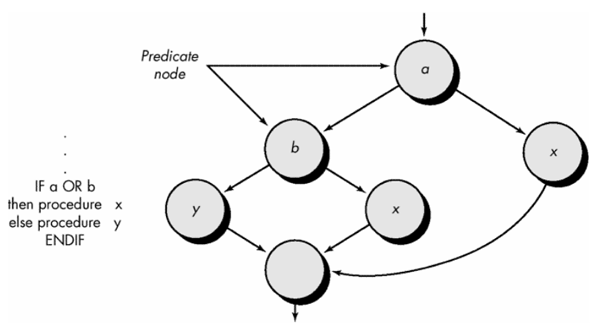
Compound conditions
-
A separate node is created for each of the conditions a and b in the statement
IF a OR b
-
Each node that contains a condition is called a predicate node and is characterized
by two or more edges emanating from it.
Cyclomatic Complexity
-
Software metric that provides a quantitative measure
of the logical complexity of a program
-
Defines the number of independent paths in the basis
set of a program
-
Provides an upper bound for the number of tests
that must be conducted to ensure that all statements have been executed
at least once
-
Independent path is any path through the program
that introduces at least one new set of processing statements or a new
condition
-
In a flow graph, an independent path must
move along at least one edge that has not been traversed before the path
is defined
-
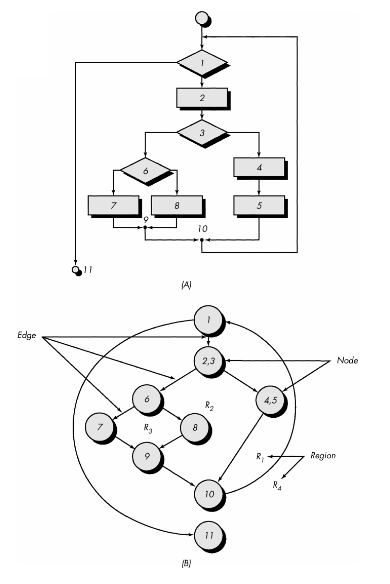
Example (1st flow graph above)
-
path 1: 1-11
-
path 2: 1-2-3-4-5-10-1-11
-
path 3: 1-2-3-6-8-9-10-1-11
-
path 4: 1-2-3-6-7-9-10-1-11
-
Basis set - a set of flow graphs that specify
every path in the program
-
If tests can be designed to force execution of a
basis set:
-
Every statement in the program will have been guaranteed
to be executed at least once
-
Every condition will have been executed on its true
and false sides
-
Complexity is computed in one of three ways:
-
The number of regions of the flow graph correspond
to the cyclomatic complexity.
-
Cyclomatic complexity, V(G), for a flow graph, G,
is defined as
V(G) = E - N + 2
where E is the number of flow graph edges, N
is the number of flow graph nodes.
-
Cyclomatic complexity, V(G), for a flow graph, G,
is also defined as
V(G) = P + 1
where P is the number of predicate nodes contained
in the flow graph G.
-
Example (1st flow graph above)
-
The flow graph has four regions.
-
V(G) = 11 edges - 9 nodes + 2 = 4.
-
V(G) = 3 predicate nodes + 1 = 4
Preparing Test Cases
-
Applied to a procedural design or to source code
-
Procedure:
-
Using the design or code as a foundation, draw a
corresponding flow graph
-
Determine the cyclomatic complexity of the resultant
flow graph.
-
Determine a basis set of linearly independent paths
-
Prepare test cases that will force execution of each
path in the basis set
-
Each test case is executed and compared to expected
results
Control Structure Testing
White-box techniques
-
Focus on control structures present in the software
-
Condition testing (e.g. branch testing)
-
Focuses on testing each decision statement in a software module
-
Must ensure coverage of all logical combinations of data that may be processed
by the module (a truth table may be helpful)
-
Data flow testing selects test paths according to the locations
of variable definitions and uses in the program
-
Loop testing focuses on the validity of the program loop constructs
(i.e. simple loops, concatenated loops, nested loops, unstructured loops),
involves checking to ensure loops start and stop when they are supposed
to (unstructured loops should be redesigned whenever possible)
Graph-based Testing Methods
Black-box methods
-
Based on the nature of the relationships (links) among the program objects
(nodes),
-
Test cases are designed to traverse the entire graph
-
Attempts to find errors in the following categories:
-
incorrect or missing functions
-
interface errors
-
errors in data structures or external data base access
-
behavior or performance errors
-
initialization and termination errors
-
Tends to be applied during later stages of testing
-
Purposely disregards control structure, attention is focused on the information
domain
-
Tests are designed to answer the following questions:
-
How is functional validity tested?
-
How is system behavior and performance tested?
-
What classes of input will make good test cases?
-
Is the system particularly sensitive to certain input values?
-
How are the boundaries of a data class isolated?
-
What data rates and data volume can the system tolerate?
-
What effect will specific combinations of data have on system operation?
-
Testing Methods:
-
Transaction flow testing (nodes represent steps in some transaction
and links represent logical connections between steps that need to be validated)
-
Finite state modeling (nodes represent user observable states of
the software and links represent transitions between states)
-
Data flow modeling (nodes are data objects and links are transformations
from one data object to another)
-
Timing modeling (nodes are program objects and links are sequential
connections between these objects, link weights are required execution
times)
Equivalence Partitioning
-
Black-box technique that divides the input domain into classes of data
from which test cases can be derived
-
An ideal test case uncovers a class of errors that might require many arbitrary
test cases to be executed before a general error is observed
-
Equivalence class represents a set of valid or invalid states for
input conditions.
-
Equivalence class guidelines:
-
If input condition specifies a range, one valid and two invalid equivalence
classes are defined
-
If an input condition requires a specific value, one valid and two invalid
equivalence classes are defined
-
If an input condition specifies a member of a set, one valid and one invalid
equivalence class is defined
-
If an input condition is Boolean, one valid and one invalid equivalence
class is defined
Boundary Value Analysis
-
Black-box technique that focuses on the boundaries of the input domain
rather than its center
-
BVA guidelines:
-
If input condition specifies a range bounded by values a and b, test cases
should include a and b, values just above and just below a and b
-
If an input condition specifies and number of values, test cases should
be exercise the minimum and maximum numbers, as well as values just above
and just below the minimum and maximum values
-
Apply guidelines 1 and 2 to output conditions, test cases should be designed
to produce the minimum and maxim output reports
-
If internal program data structures have boundaries (e.g. size limitations),
be certain to test the boundaries
Comparison Testing
-
Black-box testing for safety critical systems in which independently
developed implementations of redundant systems are tested for conformance
to specifications
-
Often equivalence class partitioning is used to develop a common set of
test cases for each implementation
Orthogonal Array Testing
-
Black-box technique that enables the design of a reasonably small set
of test cases that provide maximum test coverage
-
Applied to problems in which the input domain is relatively small but too
large to accommodate exhaustive testing.
-
Focus is on categories of faulty logic likely to be present in the software
component (without examining the code)
-
Priorities for assessing tests using an orthogonal array
-
Detect and isolate all single mode faults
-
Detect all double mode faults
-
Multimode faults
Specialized Testing
-
Graphical user interfaces (see Chapter 31 and the SEPA web checklist)
-
Client/server architectures (see Chapter 28)
-
Documentation and help facilities (see Chapter 8 and Chapter 15)
-
Real-time systems
-
Task testing (test each time dependent task independently)
-
Behavioral testing (simulate system response to external events)
-
Intertask testing (check communications errors among tasks)
-
System testing (check interaction of integrated system software and hardware)