|
SE735
- Data and Document Representation & Processing |
|
Lecture 10 -
Analyzing Documents and Document
Components |
Analyzing Documents
Classifying Requirements in
Document-Intensive Contexts
·
SOLUTION requirements – the
functional, performance, quality attributes
·
INFORMATION or DATA requirements – what
information is needed, what are its datatypes,
possible values
·
DOCUMENT or STRUCTURE requirements
– how is the information organized / assembled / packaged into sets of related
information
·
PRESENTATION or SYNTACTIC
requirements – how is the information presented or formatted or rendered – the
physical or output model
·
PROCESSING and USAGE requirements –
what relationships between documents have a business purpose
From Chapter 8 of Document
Engineering
Rules that Apply to Conceptual
Models
· Semantic
· Structural
· Usage
Rules that (Can Also) Apply to
Physical Models
· Syntactic
· Processing
· Presentational
Rules that Apply to Instances or
Implementations
·
Content
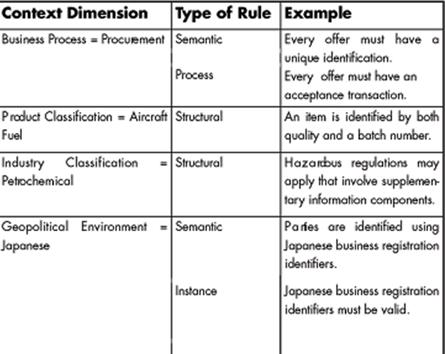
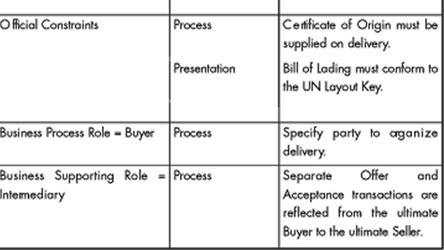
Requirements in the Model Matrix
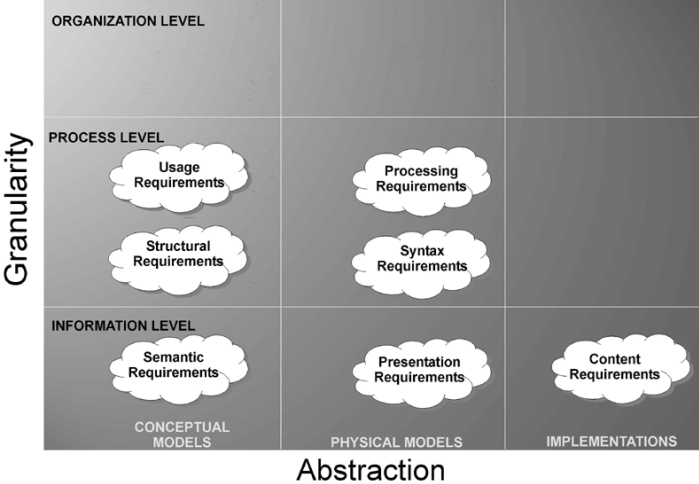
Context Dimensions x Rule Types
Rigorous Requirements Processes are
Document-Intensive
·
Occasionally requirements are
developed in an extremely rigorous way
·
Large companies or organizations
(example: government, military, General Motors) may conduct a "contract
definition phase" or issue a "Request for Information" (RFI)
document in which they engage multiple companies or consultants to define a
problem and come up with some preliminary solution or design concepts
·
These requirements may be heavily
constrained by legacy technology or processes unique to the customer
·
The best ideas then get turned into
a "contract specification" or a "Request for Quote" (RFQ)
document.
A More Typical Requirements Process
·
Most companies carry out IT
planning activities (in software companies these are called "product
management" or "product marketing" activities) to define
requirements for systems or applications
·
The results of this activity are
recorded in a "Product Requirements Document" or PRD
·
These requirements are then
negotiated with the organization that will design and develop them (engineering
or other R&D organization) the requirements specifications can provide a
roadmap for future versions or products
When There Isn't A
Requirements Process There Are No Documents
·
Some companies – especially new or
undisciplined ones – don't bother with requirements
·
Many people want to "get on
with it" and are biased toward working on the "end product"
(doing the programming or implementation activity) rather than working on less
tangible intermediate artifacts (like those produced by requirements, analysis,
and design activities)
·
So they don't specify requirements
in any rigorous way and no models of information or process are created
· Not saying
that "prototyping is bad" or "agile methods don't work" but
"model-guided prototyping" is a lot better -- it is essential to
systematically explore some design alternatives
Who Performs Document Analysis?
·
Standard approach is facilitation
by document analysis experts in face-to-face "workshops" with broad
participation
·
Document creators/users reach
consensus with expert help, and then experts systematize it into models and
schemas
·
Document analysis is often carried
out as a consulting engagement – with all the complications of defining the
project, managing expectations and relationships, and packaging the results for
effective use
Creators/Users in Document Analysis
·
What will they know?
·
What won't they know?
· What factors will constrain their interactions with you?
Experts / Consultants in Document
Analysis
·
This is YOUR role
·
What will you know?
·
What won't you know?
·
What factors will constrain your
interactions with others?
Generic Requirements in
Document-Intensive Environments
· Automated information capture --
Eliminate manual entry (or reentry) of information when documents are created
· Straight-through processing --
Minimize the need for any human intervention as a document flows through some
specified processes.
· Timeliness -- Make
information available to those who need it when it is needed and when promised,
and update it promptly when it changes.
· Accuracy -- Ensure that every piece of
information in a document is correct.
· Completeness -- Ensure
that a document contains all the information it should or that its recipient
(person or application) expects.
· Automated validation -- Provide
a schema or specification that enables information to be validated.
·
Interoperability -- Enable
information to be used "as is" or via automated transformation by
other systems or applications
·
Standards compliance -- Conform
to regulations or standards for information structure, accessibility,
availability, security, and privacy.
·
Customizability --
Facilitate the internationalization, localization, and subsetting
of information.
·
Usability -- Present information in a format
or medium that is easy to use and understand by its intended users.
·
Identifiability -- Ensure that the design or appearance of a document signals
that it comes from our organization or company ("branding")
What a "Document" Is
·
Every major advance in transportation,
communications, manufacturing, financial technology or "governance"
has required new types of documents
·
But the basic idea of a document
has been surprisingly stable for a couple of millennia
o
A document is a self-contained
package of related information
o Documents organize business interactions around the information
needed to carry out transactions
o Documents are the inputs and outputs of business processes
·
In most Document Engineering
efforts a critical step is creating a document inventory and classifying the
"documents" you locate
·
You need to take a very broad view
about what's a document because much of what's important to analyze isn't a
traditional document
·
Much of what we analyze comes from
people or systems or machines, and the lines between "requirements
analysis," "document analysis," and "user-centered
design" aren't always sharp
·
You can think of what you learn
from people as instances of "interview" or "observation"
document types
Recognizing Documents
·
Documents are packages used for exchanging
information.
·
Packages may be:
o Paper form (printed/written, formal/informal)
o Digital form (computer files, structured/unstructured, databases)
·
Exchanges may be:
o Messages (emails, EDI)
o Online or Web
o Postal, Fax
·
Sets of data in databases, spreadsheets,
accounting systems
·
Completed Printed forms
·
Job aids, "cheat sheets,"
sticky notes and other informal or unofficial documents
·
Lots of undocumented information in
people's heads that you write down after talking to them
Document Types (vs
Instances)
·
Blank Printed forms
·
Web forms
·
Database schemas
·
Documents that describe APIs or
maybe even the code that implements them
·
Style sheets or templates in office
applications
Finding the Right Documents for the
Inventory
·
Not all types of documents are equally
important; is a document intrinsic to a business process or a
derivative/aggregate of it?
·
If there are many instances of a
particular type, we might have to be concerned about representiveness
and selection biases
·
Don't assume that job titles and formal
organizational structure reflect what people actually do
·
Don't assume that the names given
to documents fit the people, tasks, and organizations in which we locate them
·
Regardless of its title, make sure
a document is being used before you conclude it is important
Names for Document Types and
Instances
·
Sometimes there are rules for names
of document types
·
Sometimes there are rules for names
of document instances
·
Sometimes the names of document
types or instances aren't informative
· Names are just one kind of metadata attached to document
instances; there is lots more
Iteration in Document Inventory
· Identifying
all the potentially relevant documents or information sources is inherently an
iterative task
o
Documents may refer or link to other documents
o
Documents may refer to people, who can refer to other documents or
people
· Developing
a causal model of the domain can help identify the intrinsic documents
o
Where are the "headwaters" for the information -- what
events or processes cause it to be created?
o
A causal analysis can suggest other correlated information
"streams" that merge with the primary source you've identified
Using Process Patterns to Find
Documents: The Document Checklist
Analyzing the Document Inventory
·
You need to arrange the results of
your inventory so you can think about it as a whole and in parts
·
What aspects of documents vary
systematically across the categories in the inventory?
·
What other aspects of documents
vary, but not systematically across the categories?
·
We need some concepts and
vocabulary for answering these questions
Categories of Document Types
· There are a
few hundred common types of documents used in business transactions
· But
transactions are just one category of document types
· Other categories
with many distinct types include:
o
Software and system documentation
o
Procedures, policies, laws, and regulations
o
Reference books, encyclopedias, dictionaries
o
Catalogs
· Organizations
often use or produce multiple document types within the same category
Document "Collections" or
"Chains" or "Clusters" or "Complements"
· Some sets
of document types in an inventory are related to each other
· Some
document types are themselves sets of documents of another type
· Other
document types fit together in a kind of sequential or process relationship
where information flows from one to another in the normal way in which they are
used or created
· Transactional
documents often come in pairs that must be correlated
· Documents can
have complementary (they are useful together) or uncomplementary
(they are not useful together) relationships, and the relationships aren't
necessarily symmetric
The Document Type Spectrum

Systematic Variation in Document
Types Across the Spectrum
·
Instances more heterogeneous on
narrative end
·
Types are "broader" and
more descriptive, less prescriptive on narrative end
·
The set of content types within a
document type is much greater on the transactional end because the leaves
aren't "just text"
·
More need for "metadata"
augmentation of documents on narrative end, because on transactional end what
would be metadata is more likely to be explicitly contained in the content
already
·
Presentational information more
likely to be correlated with content and structure on narrative end
Organizing the Inventory
For every document or information
source you should collect:
· Name
· Source
(where/who found)
· Definition
· ?
· ?
· Any
metadata that helps you decide whether to analyze it
Sampling the Inventory
·
Sample from all parts of the
document type spectrum
·
Sample more from heterogeneous
categories
·
Sample documents based on priority
of requirements
·
Sample based on importance or
authoritativeness
Generic Inventory Questions
For documents received by an organization, we can ask the following
questions:
·
What is
the official name of the document? Does it also have other informal or
unofficial names?
·
From whom
(or in what process) do you receive the document?
·
Why do
you receive it?
·
What are
you expected to do with it?
·
How often
do you receive it?
·
What
events trigger the sender’s actions?
·
Does the
document contain all the information you need for the process for which the
document is received?
·
Does the
document contain information that is unnecessary for the process?
·
What do
you do with the document after your process has been carried out?
·
To whom
(or to which organization) do you send it?
For documents sent by the organization, we ask:
o
What is
the official name of the document? Does it also have other informal or
unofficial names?
o
To whom
(or what process) do you send the document?
o
Why do
you send it?
o
What do
you expect the recipient to do with it?
o
How often
do you send it?
o
What
events trigger your actions?
o
Does the document
need to conform to any standards for content, structure, or presentation?
o
What does
the recipient do with the document after their process has been carried out?
Organizational Issues in Document
Analysis
·
Org charts can suggest business
processes (and their associated documents), people who can tell us about them,
and the context boundaries we can enforce
·
The level at which you interact
with an organization - the kinds of people you interact with - strongly shapes
what you learn about it
· The concreteness of document analysis makes it more "bottom
up" than business process analysis
Strategic Document Analysis
·
Document Analysis IN a
Strategic Effort:
o Microsoft merges with Yahoo! and assesses how each side does
business to decide what practices/ orgs/people should be retained
o One of the last phases of efforts like these is Document Analysis
to ensure that the "keeper" processes of the merging firms are
effectively combined
·
Document Analysis AS a
Strategic Effort:
o Analyze the information creation, management, processing, and
distribution activities of an enterprise or organization to support the
development of a data and process dictionary, an information architecture, or
an enterprise data model
o Often the foundation activity for introducing a "content management"
or "knowledge management" system
Information as a Strategic Asset
· Identify
"overlaps, gaps, and opportunities" in alignment of information
assets with goals of the enterprise
· Eliminate redundancy,
identify what information must be collected that isn't, and that which might be
· Increase
reuse
· Increase
consistency
· Enable
flexible creation of customized/personalized information products
· There will
be lots of documents and data sets to analyze, but this kind of effort will be
much less focused on these existing information artifacts than a tactical
document analysis project is
Tactical Document Analysis
·
Analyze the existing information
used by some constrained set of processes in an enterprise so that the
processes can be improved, automated, re-engineered, re-purposed
·
Two most common tactical efforts:
o
Document automation
o
Online publishing
Document Automation
· Transforming
printed transactional documents or forms into electronic versions
· The
business driver is often a "request" by a dominant business to its
partner to automate the exchange of transactional information in conformance
with its proprietary document specifications
· This means
that the real goal can be to take an existing process (often, someone else's)
and encode it in electronic documents
Document Components
Document Analysis: From Physical to
Conceptual Models
· When we analyze
information sources: interviews, documents, sets of data whatever - our goal is
to identify and describe the "significant things" or the
"information components" and their characteristics or attributes
· But when
you analyze documents the information components aren't as immediately apparent
because they are contained in structures and rendered in some presentation
· So we have
to remove the presentational information and dis-assemble the structural
information to find the content information that is our highest priority
· As we take
away presentation and structure, we are abstracting away or generalizing from a
physical implementation and creating our first conceptual or logical model of
the information components
Three Types of
Information In Documents
We need a vocabulary to
classify different kinds of information that we find in documents and sets of
data
· Content
–
"what does it mean" information
· Structure
–
"where is it" or "how it is organized or assembled"
information
· Presentation
–
"how does it look" or "how is it displayed" information
Components
·
Components – the units of content
o
Any piece of information that has a unique label or
identifier is a candidate component
o
Any piece of information that is self-contained and
comprehensible on its own is a candidate component
o
A component is a logical unit, with no presentation
implied; it may be organized structurally
· These
definitions are very helpful for finding components in some types of documents
but less so in others
· It
depends on the presence of, and relationships with, the structural and
presentational information*
Content Components
We can identify components as the
separate units of content to be organized -- "pure content" with no
structure or presentation assigned or implied
Document Engineering: Optimizing
"Content + Structure + Presentation"
The "Document Engineering
Methodology" can be thought of as:
1. Distinguishing
the three kinds of information in instances or artifacts
2. Carefully
describing their current and desired relationships
3. Creating
conceptual models that describe the content information as it is and as it
could be
4. Using
principles of "good design" and patterns to refine the conceptual
model
5. Reassembling
or recombining the three kinds of information to achieve the desired
relationships in the "instances" or "artifacts," beginning
with the conceptual model and then adding structure (creating document schemas)
and then adding presentation (with transforms or stylesheets)
Document Engineering and
Information Architecture
This formulation of the Document
Engineering approach is essentially equivalent to how Information Architecture
is defined:
Information
Architecture = (((content + information structure) + navigation structure) +
presentation structure) + presentation design
The Most Important Principle for
Information Architecture
· We say
"the document is about … the photograph is about… the movie is about"
· We're
expressing a distinction between information as conceptual or as content: and
the physical container or medium, format, or technology in which the
information is conveyed
· It is very
useful to think abstractly about "information content" without making
any assumptions or statements about the "presentation" or
"rendition" or "implementation"
· Separating
content from its structure and presentation is the most important principle of
Information Architecture
Presentation Information
· Human-oriented
attributes for visual (or other sensory) differentiation (type font, type size,
color, background, indentation, pitch, ...)
· In general,
presentation information is the least important stuff you find in documents but
o
Good information architecture and user interface design correlates
this with structural or content information
o
You might have a requirement to preserve it or make it more
consistent
Presentation Fidelity and Integrity
·
Presentation Fidelity is a requirement to preserve the original presentation, often
exactly
o For example, with International Letters of Credit and Bills of
Lading you can readily imagine a bank or customs inspector carefully comparing
computer-generated and original printed documents.
o More common is the requirement to replace ad hoc, inconsistent or
incomplete presentation components with rule-governed presentation
·
Presentation Integrity is a requirement to assemble the document model in "document
order" – that is, to organize the elements so that their valid order
matches the order in which they would want them to appear in a document
instance
Extracting Presentation
Rules
· Presentation
affects structure and content by applying transformation rules to them
· To
understand the structure and content we must identify and record what the rules
of the transformation were
· Explicit
transform rules can be encoded in templates, stylesheets
or source code?
But Sometimes Rules Can't be Extracted
·
No access to source formats or
source code
·
Rules may be inaccessible in source
formats ("override" formatting in word processors instead of style
tags)
·
Rules don't exist or are
inconsistently followed (author has "fontitis"
with "ransom note" presentation style)
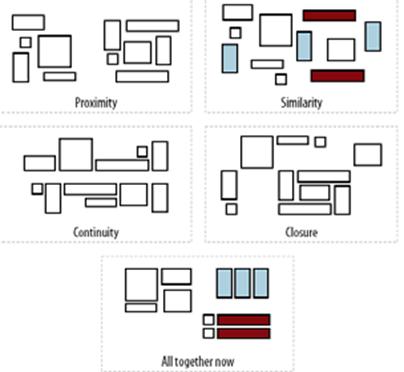
Correlations or Conventions with
Presentation Information
·
Color, pitch, other perceptual
dimensions can be correlated with semantic distinctions
·
Type size is usually correlated
with the structural hierarchy
·
Content types can have
characteristic layouts or text attributes
·
Adjacency can suggest a semantic
relationship, like that between figure and caption
·
Presentation order is sometimes
semantically significant
Binding Structure to Presentation –
Alternatives
Gestalt Principles -- Reinforcing
Structure with Presentation
Structural Information
· Physical
piece of a document or user interface (e.g. table, section, header, footer,
panel, window)
· Embodies
the rules on how content components fit together, often hierarchical
· Often
driven by context of document use
· Most
applications and web sites are organized with a small set of structures:
o
Lists/hierarchies
o
Networks/links
Structural Integrity
A requirement to preserve some
aspects of structure, but not necessarily any presentation:
· Identical
page boundaries for the electronic and printed versions of documents,
especially when document revisions are highly localized (as in "looseleaf" publications with their placeholder pages
that say "this page intentionally left blank"
· Chronological
order for a narrative biography or history
· "Putting
it together" instructions (don't want to say "assembly" here)
for a bicycle or piece of furniture need to follow the order in which they are
most easily or safely put together.
Analyzing Structural Components
·
The structural components can
provide the hierarchical "skeleton" or "scaffold" into
which the content components are arranged
·
Presentational Structures provide a
framework for presentation -- table, section, title, header, footer
·
Semantic Structures are logical
groups of conceptually-related components - parts of an Address, Phone number
·
Structural components are often
identified by the names attached to pieces of information – think of the
outline or table of contents or lists of various kinds
·
Metadata to capture
o
Depth of hierarchy
o
Sub-structures included within a structural container
o
Rules for applying numbers or names to content in the hierarchy
Content Components
· Content
components are the "nouns" in our documents or sets of data – things
like "topic," "summary," "name,"
"address," "price"
· In
publications a lot of the content isn't easily identified by "component
type" – it may be "just text" that could be playing any of a
very large number of roles in the document
· And
sometimes you get no help from the set of style or formatting tags in word
processors or in HTML, which are very format or structure oriented and not
content oriented at all
· We need XML
so we can invent the vocabulary of tags needed to describe component content in
a specific document type
Identifying Content Components
· Easier in
Transactional-type documents:
o
Documents designed to convey explicit content
o
Strong data typing with metadata for field length, range and
value, other restrictions.
· Few and
somewhat arbitrary presentational characteristics
· Information
about content components in:
o
Physical implementation models (schemas)
o
Source code of any relevant applications that process documents
Relationships Among
Content Components
Content components can be related
to one another
· Derivational
relationships
· Referential
relationships
Links
· Links are
relationships between components that can express content as well as structural
information
· A link is
represented in a logical model by its:
o
Anchors -- the point, region, or span within the components to
which it refers
o
Type -- the semantics that the link relationship represents; not
always explicit
o
Directionality -- is the link one or two-way? Is the relationship
meaningful in both directions? Does the reverse direction link mean the
inverse?
o
Cardinality -- 1 to 1 to many?
"Mixed Content"
· Narrative
documents can hide or obscure candidate components in paragraphs or other
blocks of text
· Document
analysts refer to these as "Mixed Content" components because they
are mixed into surrounding text that may be more generic or untyped
· A common
form of mixed content is an otherwise unstructured text paragraph that contains
emphasized words, glossary terms, references to tables or figures, citations to
supporting documents, or links to footnotes or endnotes
Analyzing Content Components
What attributes about each type of
content should we record in our analysis?
· Names/synonyms/homonyms
(what it is called)
· Definition
(what it "means")
· Cardinality/Optionality
(occurrence rules)
· Restricted
values, code sets, defaults
· Data Type
(text, numbers, date, video)
· Relationships/Associations
· Origin (Is
this new information, or from some other source? Who maintains it?)
Systematic
Variation in Document Types Across the Spectrum
· Instances
more heterogeneous on narrative end
· Types are
"broader" and more descriptive, less prescriptive on narrative end
· The set of content
types within a document type is much greater on the transactional end because
the leaves aren't "just text"
· More need
for "metadata" augmentation of documents on narrative end, because on
transactional end what would be metadata is more likely to be explicitly
contained in the content already
· Presentational
information more likely to be correlated with content and structure on
narrative end
Relationships
Between Text and Non-text
Another useful dimension for
thinking about content considers the relationship in documents between the text
and non-text information that they contain
· Text-dominated – most of
the content is conveyed by text components, with non-text components
unnecessary or in an incidental role (examples: legal documents, accounting information,
invoice)
· Text-framework – the
document reflects the organization defined by the text components, but non-text
components provide content enhancements (examples: encyclopedia, maintenance
manual, product catalog, purchase order)
· (multimedia) Non-text dominated or
text-enhanced – most of the content conveyed by non-text components; which
provide the framework for the text; text components carry metadata, annotate or
explain intrinsically non-textual content (examples: photos, video, engineering
drawing, atlas, art book)
The
relationship between text and non-text information can vary at all points on
the document type spectrum
·
Narrative document type can
be philosophy (all text) or anatomy (lots of non-text)
·
Transactional document type can be
invoice (all text) or RFQ (lots of non-text)
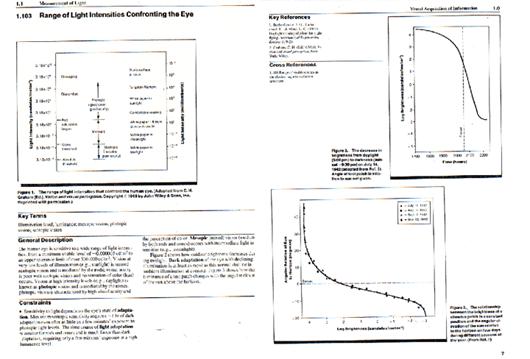
Dictionaries, Encyclopedias, and
Reference Books
· Usually
very carefully designed, with regular structure that is exploited in
information access and navigation features to enhance usability
· Often have
rich repertoire of content component types (pictures, maps, charts, formulas,
tables)
· Mixed
content in paragraphs or other text blocks will contain numerous content
types
Engineering Compendium – Typical
Entry
Encyclopedia Entry

Oxford English Dictionary – Typical
Entry

Procedures, Policies, Laws, and
Regulations
· Usually
mostly text, created and used by people Information that is often extremely
important to companies and highly-paid professionals because the cost of
finding (or not finding) information can be high
· Often has
high "intrinsic hypertext" character with many explicit and implicit
links between content components
· Often
follow structural conventions and standards with regular numbering and naming
schemes
· Versioning
and configuration requirements can pose problems
· Making this
type of content computable or executable is a huge R&D area (XML standards
like XACML, policy engines and wizards, expert systems)
Catalogs
· Many
different types
· Some are
extracted from ERP system or product database
· Often
contain a mixture of structured and unstructured content
· Often a
challenge to match the user's vocabulary and ontology for a product domain
Industrial Parts

Software "Man Page"

Home Blueprint
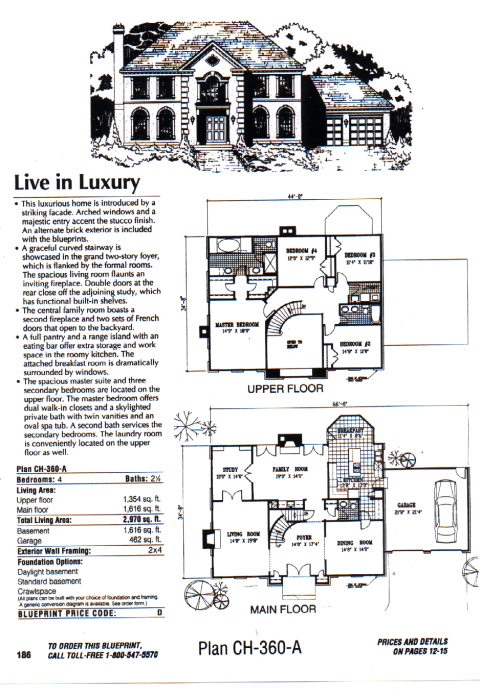
Recipe

Transaction
Documents
· Printed or
electronic forms
· Data-intensive,
designed to capture and present small information components
· Inputs and
outputs of business processes and often created and consumed by computers
· Few and
somewhat arbitrary presentational characteristics
· Strongly datatyped with field length, range and value, other
restrictions
Tax Form

Harvesting
and Consolidation
Harvesting – Create a
set of candidate content components by extracting them from the information sources
while removing presentation and structure
· As we
identify candidate content components, we need to record its properties (or
attributes or behaviors) that let us understand it and distinguish it from
other ones
· A practical
way to do this for each document or information source being analyzed, create a
table or spreadsheet containing the candidate component and the useful metadata
Consolidation– Identify
synonyms and homonyms among the candidate content components, assigning a
unique name to each unique meaning as part of a controlled vocabulary
· How
rigorously we must assign "good names" and "good
definitions" depends on the size of the document inventory and the scope
of the project
· Names might
follow precise rules to ensure that they can be reliably stored and located in
a data dictionary a la ISO 11179
Seek Semantic Clarity
and Precision
"What's in a
Name?"
(http://www.vertaasis.com/articles/whats_in_a_name.htm
recommends three "levels" of models (or names)
· Business names
–
a format that lets the semantics be easily readable and verifiable by a
business person (not a modeling or XML expert). This should use familiar words
and be completely technology-independent
· Logical names
–
a format optimized for the expression of the design or model; essential that
they are expressive enough to reflect the relationships between model
components.
· Physical names
–
the format required by the implementation technology for the model
Defining
What Something Means
·
Definitions
·
Definitions in a controlled
vocabulary
·
Data types
·
Metadata
·
Metamodels
·
Formal assertions
·
Ontologies and thesauri
The Simplest Information Component
Model
· The simplest
or minimal information component model is a glossary – a list of the words used
to describe or name the "things of significance" and what they mean
· This simple
data model is augmented as attributes or characteristics of the significant
things are identified and recorded
· The model
is further developed as relationships or associations or links between the
"significant things" are identified and recorded
What Metadata to Record About Candidate Components
What attributes about each type of
content might we record in our analysis?
· Names/synonyms/homonyms
(what it is called)
· Definition
(what it "means")
· Identifiers
· Cardinality/Optionality
(occurrence rules)
· Restricted
values, code sets, defaults
· Data Type
(text, numbers, date, video)
· Relationships/Associations
(participation in structures)
· Origin (Is
this new information, or from some other source? Who maintains it?)
· Access (who
is allowed to view/change/copy/etc. it)
· Permanence
(is it static or dynamic? how often does it change?)
· Business
processes in which it participates
Analyzing Tables
· A table is
a systematic pattern of relationships among content, structure, and
presentation information, typically represented in a set of embedded
rectangular grids
· A table presents
information by organizing some set of meaningful elements to emphasize the
relationships between the elements and the manner in which combinations of
elements interact
· Most tables
(90% of them?) follow regular matrix or structural patterns in which the
organization of information (and the presentation applied to it) is consistent
with (or reinforces) the relationships between the content that is contained in
the cells or regions defined by the matrix
· The nature
of these relationships is often explicitly represented in the headings for
rows, columns, or other structural elements
· When the
relationships are not explicit, they can often be determined by analyzing the datatypes and content of the cells or the manner in which
the content varies from cell to cell
· The mere
existence or non-existence of values within the cells can have semantic
significance
Document Types as Tables, Tables as
Document Types
· A
transactional document type is often little more than a table (of items
ordered, purchased, shipped, etc.) with some additional information about the
parties to the transaction
· A table
embedded in another document might be best understood as a "mini-document
type" of its own, especially when the "containing" document type
is more narrative than transactional
The Trouble with Tables
·
The obvious and optimal analysis of
the information in a table is in terms of these content relationships:

· Unfortunately,
the predictable geometry for organizing their content has led to tables being
analyzed and implemented in terms of the structure of their presentation rather
than a set of content relationships

· And in addition
to the problem that most tables aren't represented in ways that capture their
"tablehood" essence, it has been estimated
that 95% of the information marked up as <TABLE> on the web is not really
a table
· And some small
percentage of things that are tables according to our definition defy content
encoding because they combine content, structure, and presentation in ways that
are often impossible to untangle or that are highly idiosyncratic but
conventional
Transforming Presentation to
Content
·
Deconstructing tables into their
content types is an instance of the more general goal of transforming
presentation to content
·
Other presentation components and
conventions that carry semantic information should be made explicit as content
components
o
The mere existence or non-existence of values within the cells of
a table can have semantic significance.
o
Color coding: Red text or box around text -> warning
o
Adjacency: figure and caption -> illustration aggregate
Analyzing "Possible
Values"
· It is
critical to capture any rules governing the possible values for a component
· Sometimes
possible values are conventional, fixed, and span the entire semantic range for
some domain (days of week, AM/PM)
· Determine
who can control the value sets (internal [Manufacturer part #s] vs external [Bar codes])
· Patterns
like regular expressions are often useful but not sufficient for validation
· And if the
set of possible values is just historical and not well motivated, fix it in
your component design
Code Sets
· Codes are
constrained sets of values
· Codes
establish their meaning by reference to those values, often by abbreviations
· Using codes
in vocabularies and metadata promotes consistency and makes meaning unambiguous
· You especially
want to avoid doing a partial enumeration in a domain where a standard set of
enumerated values already exists
· Most
organizations have internal code sets or business rules that implicitly define
them
External and Internal
Codes
· External
codes are those maintained by some entity or organization outside of your
control (ISO, ANSI, etc.)
· The
ISO
code sets for countries (3166), currencies (4217), quantities
and units of measure (31) are the bedrock ones that you should generally defer
to without question
o
ISO 639 - language codes
o
ISO 3166 - country codes
o
ISO 4217 - currency codes
o
IATA port codes (e.g. airport)
· Internal
codes are code sets that you can define and control
How This All Relates to Content
Models in Vocabularies
· EXAMPLE:
"country code" or "currency code" are "Fregan" and can be reduced to context-free
enumerations, but "country" or "money" can't began they're
"Wittgensteinian"
· Put very
simply: The meaning of a tag can rarely be defined in terms of its legal values
· This
doesn't mean that we can't use money as a component in an information model,
but it warns us that we can be more precise if we pretend that money can be
understood as "currency code" and an "amount"
· And
whenever a "code set" exists in the world, make sure you capture it
in your semantic description
Consolidating The
Harvest
· We can
begin our consolidation with the candidate components from any of the
information sources, but we recommend using the one you believe is the most
authoritative or that yielded the most components
· The goal is
to combine components that are synonyms (different names for the same [or
highly similar] meaning) and to distinguish any homonyms (same names for
different meanings)
Guidelines for Minimizing Synonymy
· Components
that are similar but not identical in semantics often pose the most problems
because they encourage multiple inconsistent ways to tag the same content
o This is not
only not a good thing, it is a very bad thing
· Synonymous components
often arise in harvests from information sources from different authors,
organizations, and perspectives on the domain
o
Are the differences between the proposed components substantive
(that you can explain using the metadata in your harvest table) or stylistic
(based on writing or encoding style)?
o
Are the differences "real" but "unimportant"
to users or applications? (spurious precision)
Example:
Structured
Product Labeling in Pharmaceutical Industry (Thomas,
XML 2004)
· Rationale
and description of SPL
· Insights
about document architectures and standards activities Impact of SPL on the
"label life cycle"
o
Internal format, or interchange format?
o
Process conversion or content conversion?
Structured Product Labeling
· "Labels"
are complex document types to model. Why?
· Drugs have
been regulated a long time, and the standards for labels have also evolved.
How?
SPL Resources
· Executive Summary
An Introduction to Structured Product Labeling
· SPL
Schemas and Documentation
· Labeling
Regulations in 21 CFR 201
· National
Drug Code Directory
21 CFR 201

Label Content Mandated in 21 CFR
201.56
· Quality
o
Chemical composition
o
Strength and physical form
o
Rules for storage and handling
· Efficacy
o
Medical conditions for which it is indicated
o
Therapeutic conditions of use
o
Proper dosage for accepted indications
· Safety
o
Potential side effects
o
Contraindications of use
o
Rules for monitoring patients
Drug Label Distribution
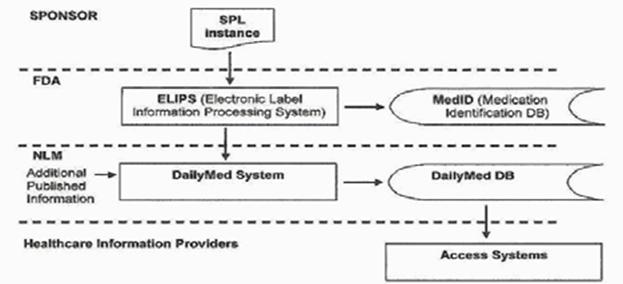
Evolving Healthcare
Standards and Document Architectures
· It
has been recognized for a long time that standards in healthcare and pharma were important; first standards were for paper documents
· SPL's
development was begun by the Pharmaceutical Research and
Manufacturing Association but moved into HL7,
an ANSI-accredited standards organization focusing on clinical and
administrative information for healthcare
· The
HL7 Version 2.x series contains 100s of separate messages and is the most
common standard used for patient medical records, with legal status in the US
and several other countries
· Until
recently HL7 committees developed document type standards in a "bottom
up" way, roughly one at a time, with whatever tags a specific document
type needed
SPL in the HL7 RIM
· The
RIM uses very abstract structures to specify the information hierarchy in a
document type: structured body -> component -> section
· All
components derived from six base ones in an O-O type hierarchy, ACTS, ENTITIES,
ROLES, PARTICIPATION, ACTRELATIONSHIP, ROLELINK
· Using
the RIM establishes ontological relationships among all the elements used in
any HL7 v 3.0 document type
· This
goes way beyond even the approach in UBL and makes reuse robust for automated
processes
· But
this means that an SPL instance doesn't have the tag names
you'd expect
Drug Label Life Cycle
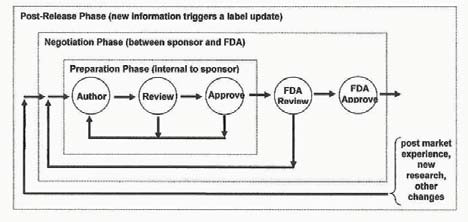
SPL and the Labeling Process
·
SPL could be used as an internal
format in the authoring, revision, publishing processes or simply used as the
submission format to the FDA
·
Arguments in favor of internal SPL
include...
· Arguments
in favor of interchange SPL include...
Drug Label Life Cycle - Where's
SPL?
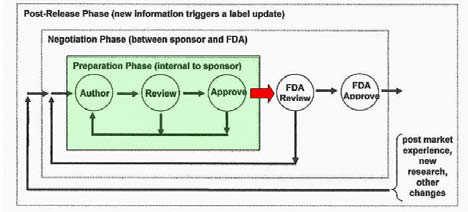
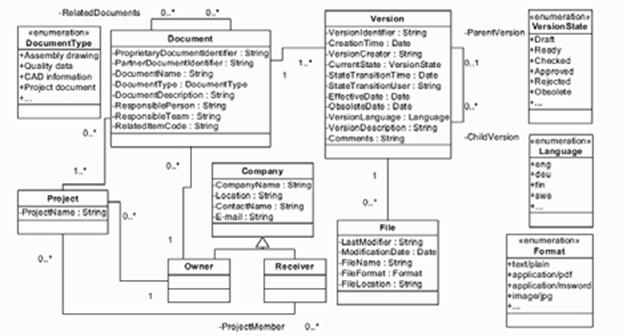
Common Data
Model for Design Document Exchange (HICSS 2005)
NOTE: The
design documents themselves are exchanged as files; all of this work is to
harmonize the "wrapper" metadata to enable synchronized document
management, version control, etc.
·
How does document exchange in
outsourced product development differ from in-house product management?
·
What are the advantages of a common
data model compared with pairwise document transformation?
·
What are the disadvantages of a
common data model?
· The priorities for the common data model were PDM integration,
simplicity of implementation, and reuse of the model. How did this influence
the model?
The Scale of the Challenge
· The
existing document models of just 6 different firms have:
o
from 21 to 111 information components
o
250 different components overall
o
only 25 (after semantic consolidation) that are used by three or
more firms
· One company
had 127 different types of design documents – pretty clear why we can't come up
with a single model for them
The Consolidated Harvest Table
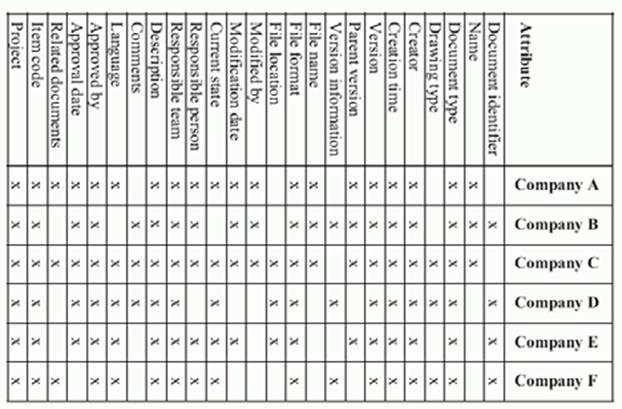
The Common Data Model - Table
Format

The Common Data Model - Table
Format