|
SE735
- Data and Document Representation & Processing |
|
Lecture 11 - Assembling Document Components
and Document Models |
After
Consolidation, Then What?
§ We have now reached the point where we have captured the
business rules and content components of the domain / document inventory in
which we're working
§
We have separated the Presentational,
Structural and Content Components
§ We have developed a conceptual model of our consolidated
and essential "atomic" content components -- semantic equivalence
classes
§ We will have some sense of the distribution of the
content components and can distinguish those that are "core" -- that
appear in all or almost all contexts in the domain -- from those that are more
context-dependent
§ Now we have to ensure that we can reuse these components
when we assemble document models from them
Why Analysis Models
Aren't Good Enough
§ Document
artifacts differ a great deal in how they combine content, structure, and
presentation components
§ Some
combinations are idiosyncratic and ad hoc or represent compromises between
incompatible requirements that make structures less than optimal
§ If
we are completely constrained by the artifacts as they exist in our component
model, we will preserve both their good and bad aspects
§ So
our analysis models of components and aggregates may need to be revised to
allow alternative ways of satisfying our requirements
Design and
Re-design with Conceptual Models
§ The component model may present many attractive options
for re-design and reuse of our content components
§ Design means changing our model, not simply improving the
way we view it. This is when we actually get to apply our insights about reuse
and patterns
§ During design we can devise more consistent component
names, remove repeating or reoccurring content and structure, increase reuse of
standard patterns or components, replace implicit components with explicit
ones, and otherwise create a more abstract, concise, and context-free
representation of the essential characteristics
Analogy: The
Build-to-Order Computer Factory
§
Designing a factory that makes
"build-to-order" computers:
§ You might start with some collection of computers and
take them apart to see what pieces are needed to assemble them (ANALYSIS)
§ Because you want to be able to make these items with
reasonable quality but at less cost and at greater efficiency, you redesign the
computers to use standard components (DESIGN FOR REUSE)
§ You organize the components and the assembly lines to
make it easy to locate components when you get an order (ORGANIZE FOR REUSE)
Analogy: Designing
a Flexible Domain Model
§ Analyze
a set of hand-crafted applications with printed or online data entry forms to
identity pieces of information each contains (ANALYSIS)
§ You
want the complete "enterprise model" for the domain to be able to
represent any application or form with less cost and at greater efficiency, you
redesign the pieces of information from analysis to be more standard and
context-free (DESIGN FOR REUSE)
§ Organize
the components to make it easy to locate the components for the specific
contextualized model for an application or form (ORGANIZE FOR REUSE)
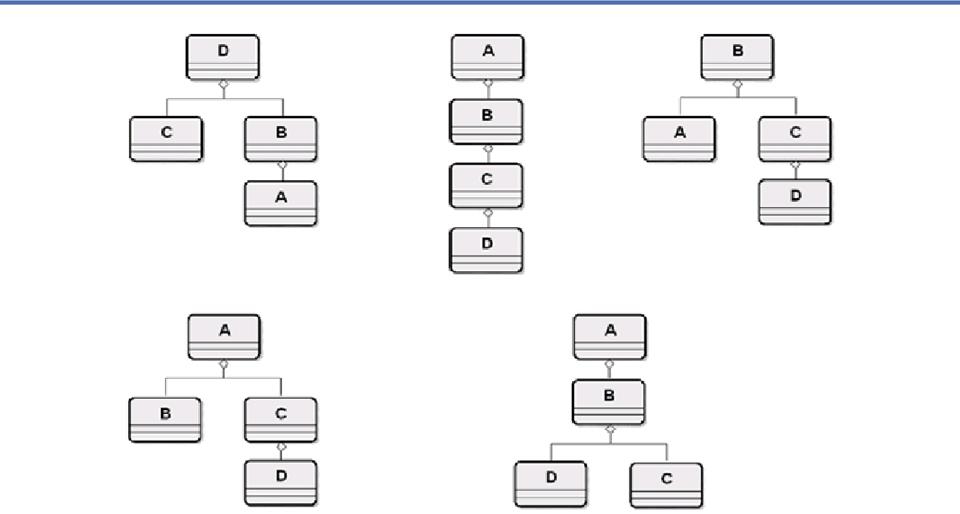
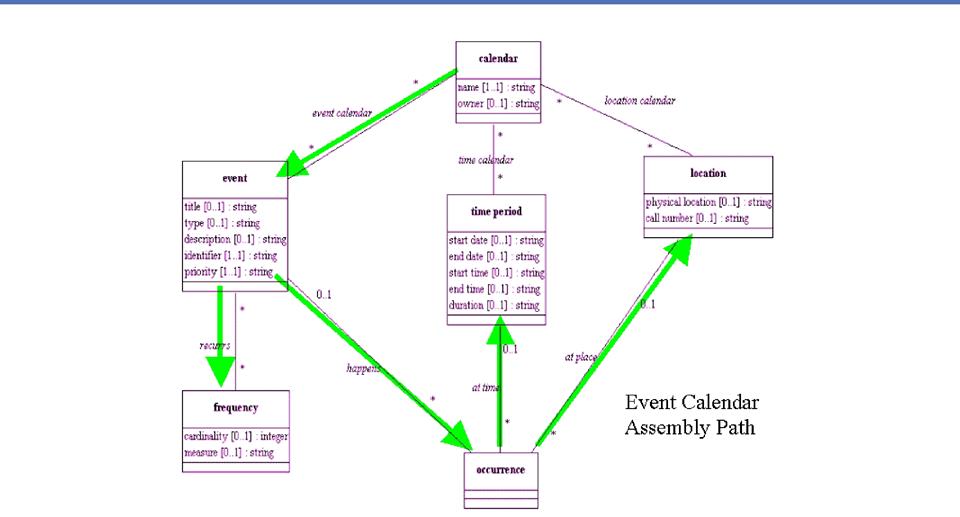
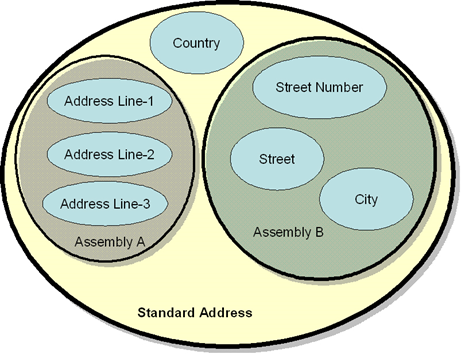
Generalizing and
Specializing Components
- You can add a
context qualifier to specialize a component rather than defining a
completely new one (this reuses the "base" component type and
gives semantically similar components similar names)
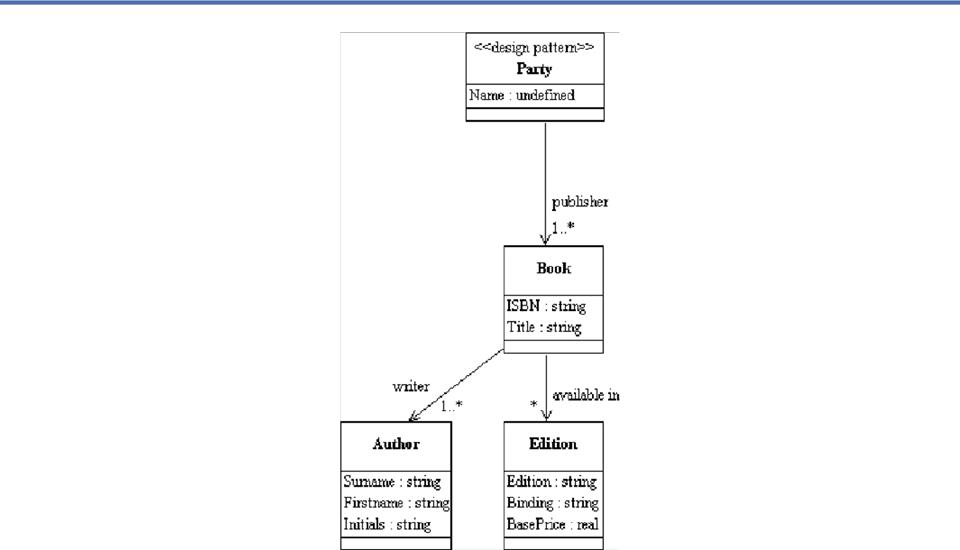
- In
the Engineering Compendium both Figures and Tables have Captions, and
the

- Caption is similar enough in both to
allow it to be re-used by both.
- This suggests components for FigureCaption, TableCaption
![]()
- You
can also "factor out" context to define a more general or
abstract component that can be used more broadly
§
"Delivery
Date" and "Ship Date" suggest a "Date" component
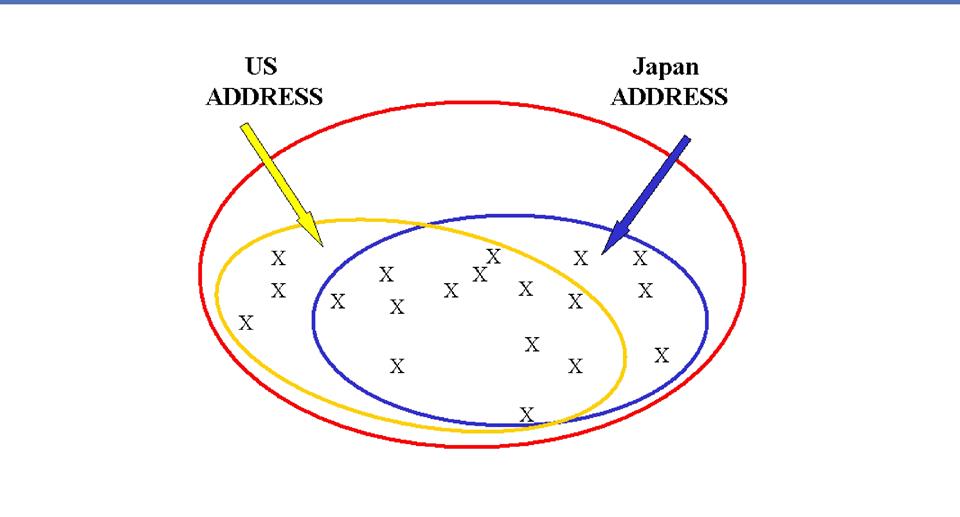
The
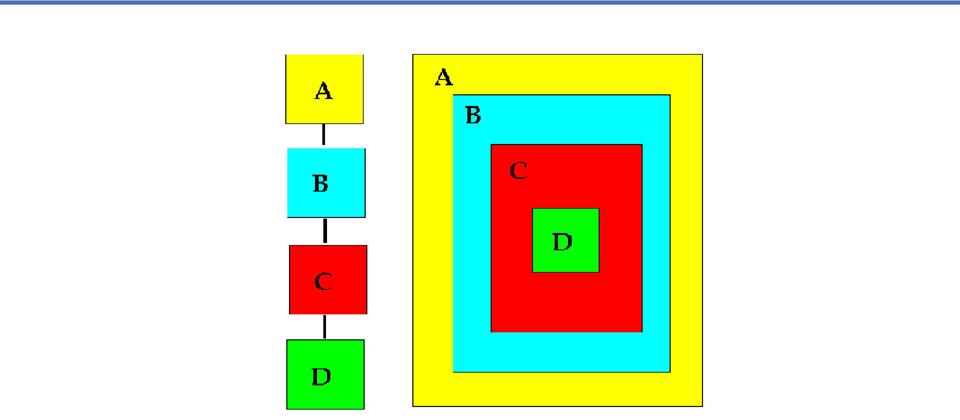
Contextualization Continuum
o
Your set of components has to find a balance
between precision and generality (or flexibility)
o
You want a set of components that can be
reused across related document types in some context (or group of related
contexts)
o
Contexts
fit into a continuum
- At
one end is an extremely specific context in which component definitions
are suitable for a very narrow class of documents
- At
the other end is an extremely loose or general context, suitable for a
very broad class of documents
![]()
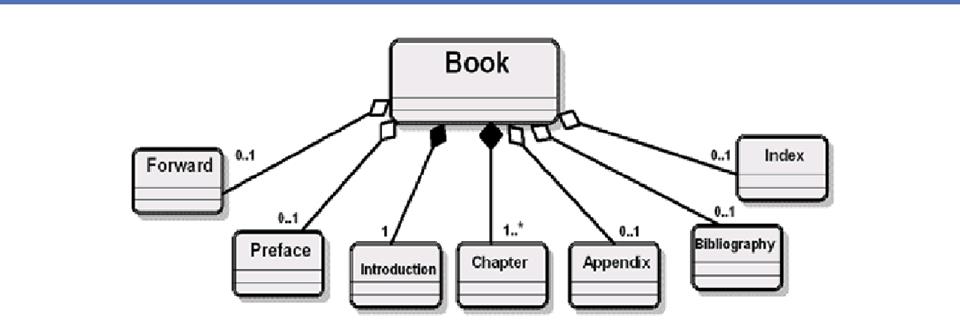
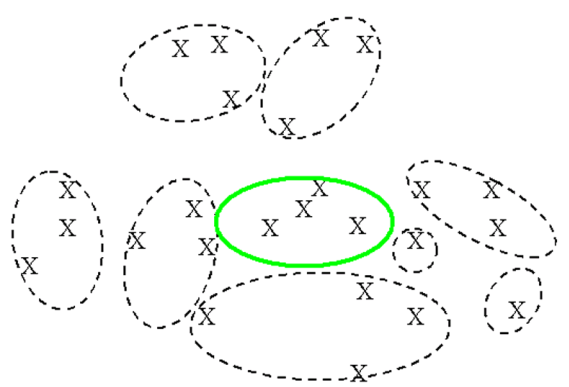
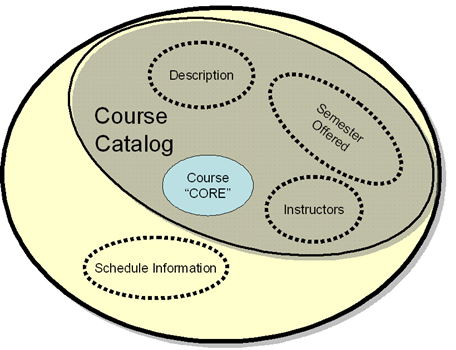
Components: A
Reminder
o
Components
– the units of content
o
Any
piece of information that has a unique label or identifier is a candidate
component
![]()
o
Any piece of information that is
self-contained and comprehensible on its own is a candidate component
o
A component is a logical unit, with no
presentation implied; it may be organized structurally
![]()
o
These definitions are very helpful for
finding (aggregate) components in some types of documents but less so in others
o
It depends on the presence of, and
relationships with, the structural and presentational information
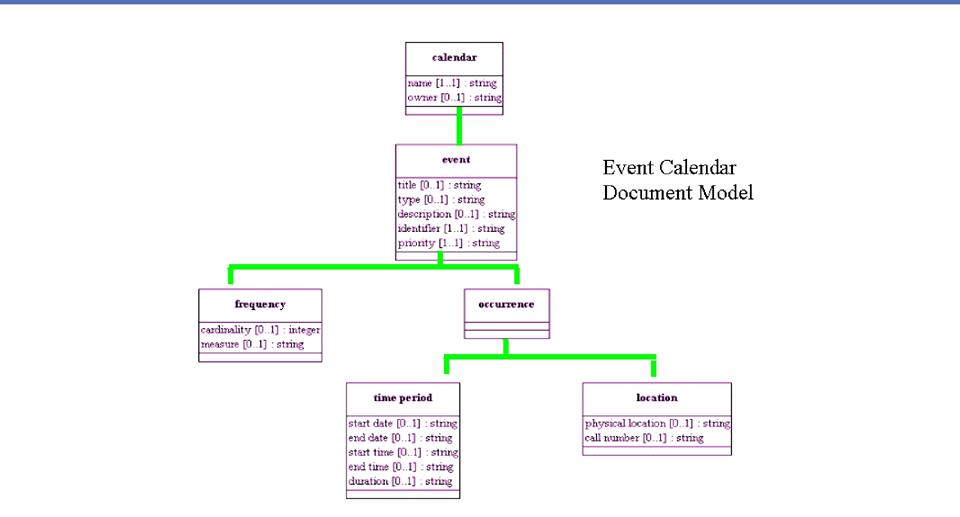
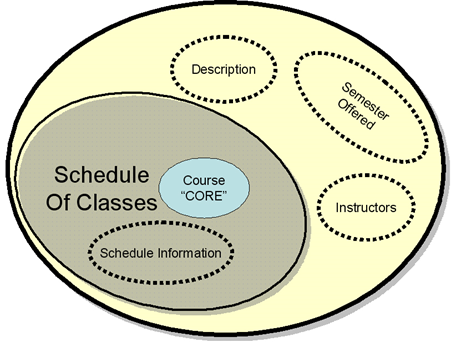
Motivating
Aggregate Components
o
ATOMIC
components that hold individual pieces of information
§ Especially in transactional documents,where
atomic components have a natural representation as primitive data types or as datatypes that are derived from these by restriction
o
DOCUMENT components that assemble smaller
components into the set of information needed to carry out a self-contained
purposeful activity
§ Especially in transactional contexts, where documents
have a natural correspondence to some unit of work that initiates, records, or
responds to a clearly-defined event
![]()
o
It is much more difficult to define the
components of "in between" sizes, especially as you move away from
the transactional end of the document type spectrum
o
AGGREGATE components are composed of atomic
ones and are reused in the assembly of document components
o
They are easier to identify in transactional
contexts because they are often the key information that flows from one
document to another
o
"Address" or "Person" are
obvious examples of aggregates composed of smaller ones
o
Two
key questions:
§ How do we select and group atomic components into
aggregates?
§ How many aggregates should we create?
Identifying Two
Kinds of Component Aggregates
o Structural
Aggregates -- sets of components defined by parent-child or containment
relationships
o One way to do this is by putting all the unique
components on index cards and then sort them into
clumps or clusters.
o First sort all the components that go together because of
containment or structural rules (X contains Y and Z).
o Conceptual
Aggregates -- sets of components that "go together" because of
logical dependency
o After you've identified all the structural aggregates,
you can start to further cluster those intermediate clusters on the basis of
dependency rules - what things "go together" logically
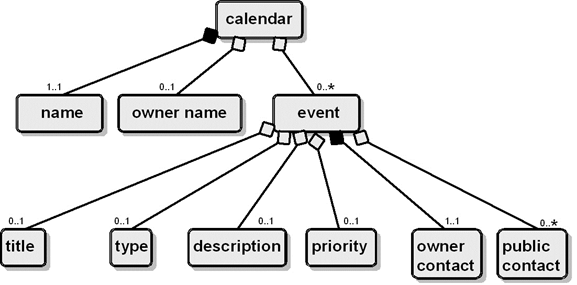
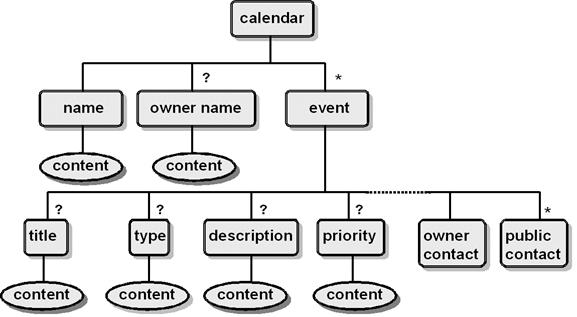
Identifying
Aggregate Components in Non-Transactional Documents [1]
o
Aggregates are more elusive on the narrative
end of the DTS because there are limits to the rigor with which components can
be grouped
o
"Mixed content" models arise when
there are few or weak constraints on where atomic components can appear
o
Presentation
often masks the atomic components in potential aggregates
o
Structures are often based on conventions for
organization and presentation than on semantic relationships
o
But there will still generally be components
that "go together" to form reusable structures
Identifying
Aggregate Components in Non-Transactional Documents [2]
o
Aggregates can be created in two
"bottom-up" ways that focus on the atomic components:
o
The first is by rebuilding or making explicit
the structures that we took apart in document analysis
o
The second is by creating structure in
"blobs" of poorly structured information written in an overly
narrative style
o
A more modular style for the information will
increase its regularity and reusability; it will eliminate content that has
little value to users and reinforce its use as "boilerplate" or via
links
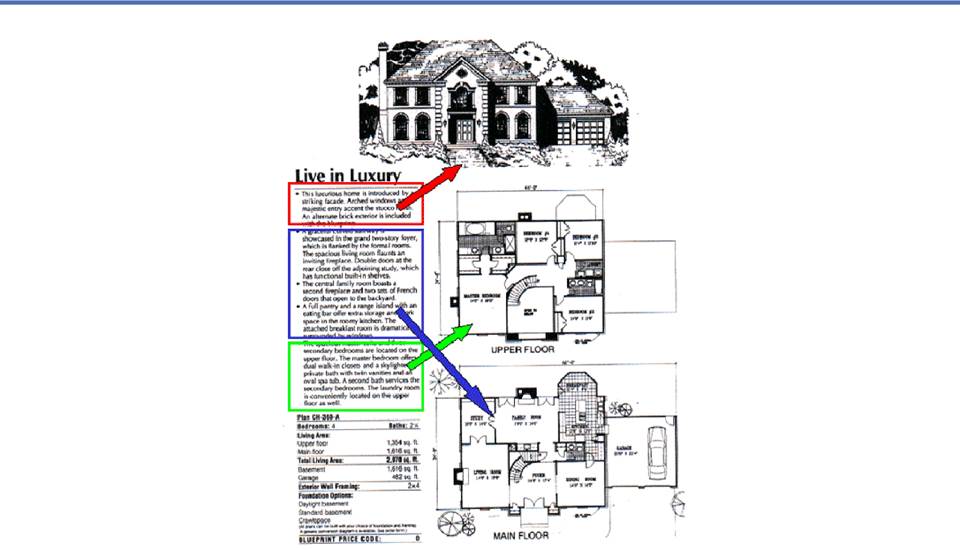
Home Blueprint:
Analysis Model
o
The layout doesn't reinforce the idea
of reusable components and aggregates...
o
Every house has an exterior view, and
an interior view for each floor
o
Each of these views has a
caption/annotation
o
houseplan(theme,views,specs), view, (illustration+), illustration(figure,description+)
House Plan Redesign
- Logical Aggregates
House Plan Redesign
- Revised Presentation

Extracting
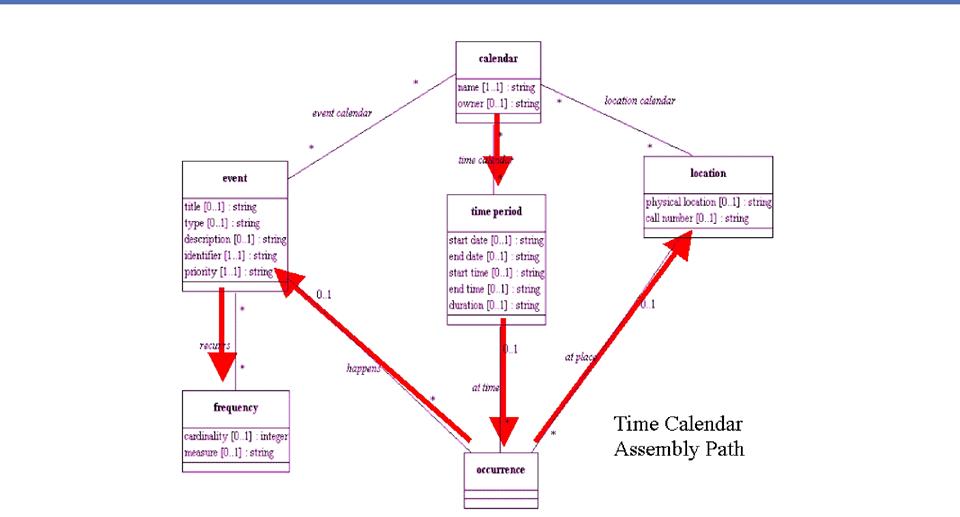
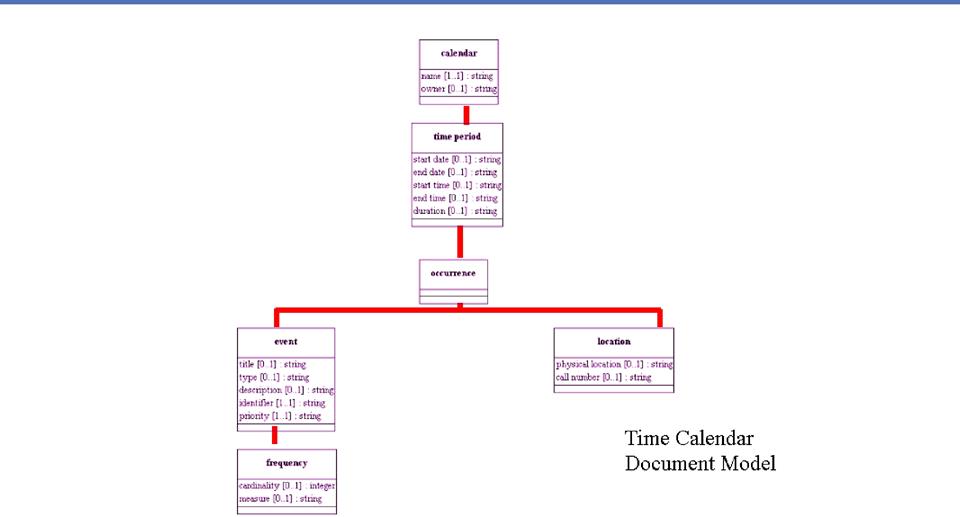
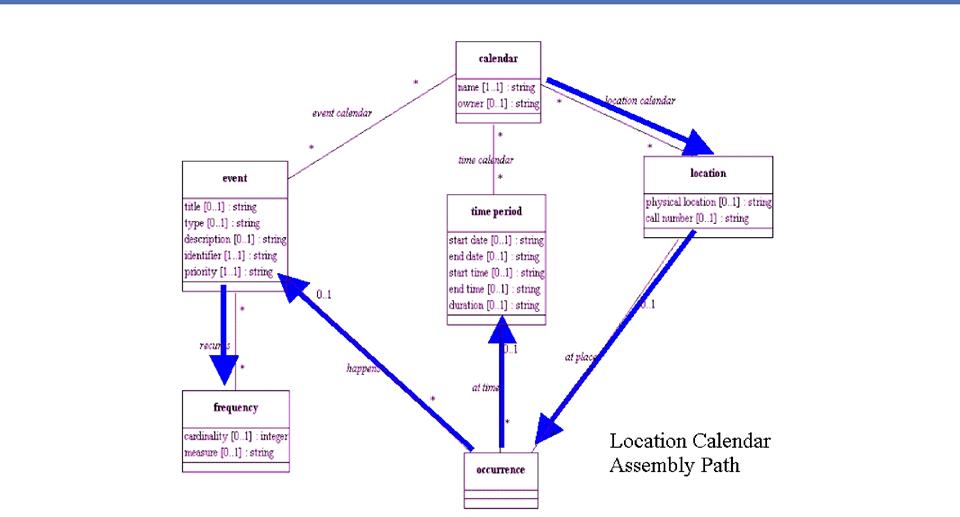
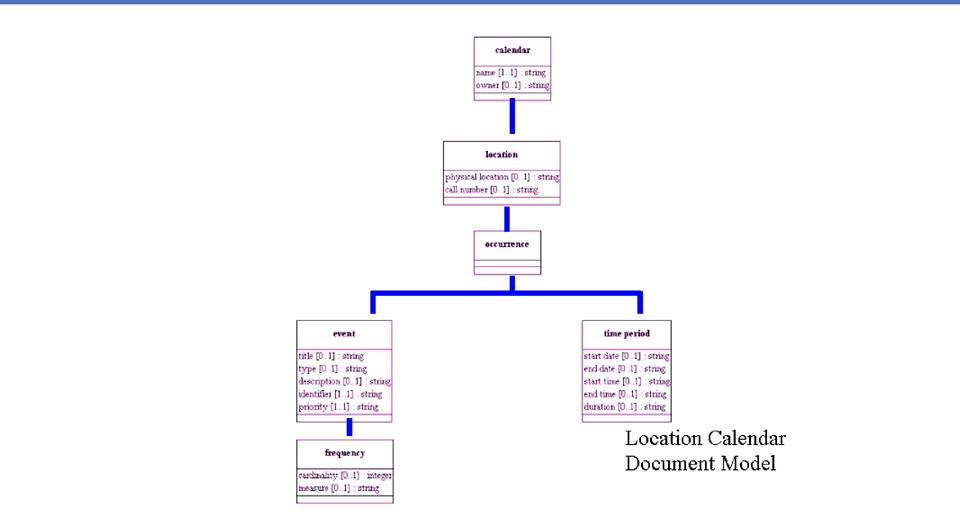
Repetitions
o
Different aggregates might have the
same components
o
"Contract" and
"Shipment" might both have "Start Date," "End
Date" and "Duration"
o
The repeated components can be
extracted and created as a reusable aggregate
o
In this example we might call the
common pattern the "Period"
Reuse of Existing
or External Patterns
o
Many
of the patterns that you might identify as repetitions would have also been
identified in a previous analysis of your domain or context
o
You
should determine if their analysis yielded components for you to reuse
o
Pay
particular attention to "standards" if they come from credible
sources
o
But
don't accept someone else's analysis and models if you don't understand them
o
And
NEVER assume that a component model is appropriate solely on the basis of its
name because:
o
Names
aren't "self-describing"
o
Otherwise,
why are we bothering to collect all the bits of metadata about each candidate
component?
Identifying
Aggregate Components in Non-Transactional Documents
o
We also can identify aggregates via a kind of
reverse engineering of the document models required or suggested by the context
o
We call this CORE PLUS CONTEXTS -- factoring
a set of related document models into the aggregates that are needed to
assemble them
Identifying
Aggregates in More Formal Ways
o
The heuristic and informal approach we just
followed was called "document analysis" in the
SGML/publishing/content management tradition
o
But these techniques are shaped by the skill
and biases of the document analyst; they don't yield uniform results and don't
scale well
o
If there is to be a discipline of Document
Engineering, we need a more formal and deterministic modeling approach that is
consistent with classical document analysis
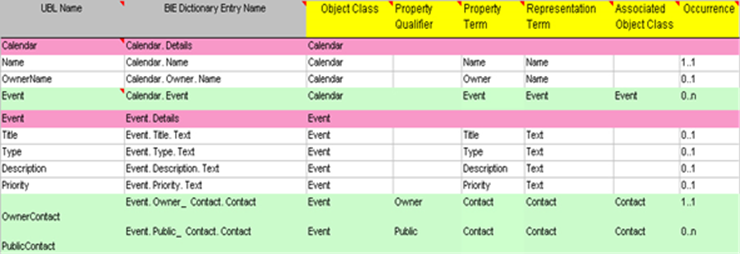
Data Modeling Principles for Designing Content Components
o
The more transactional our design
situation is the more we can (and need) to apply additional rules or
requirements that apply to "data-intensive" components
o
Data Integrity– the information must
be correct
o
Referential Integrity
–
repeated data components (in an
"information supply chain" or set of documents) must agree in values
o
Identification Integrity – the
identify of data should be unambiguous
o
These three principles embody the
concept of Essentiality – the model contains only the essential information
with no duplication
o
Relational Theory is the basis for
identifying essential components
Relational
Theory
§
Mother
of all data modeling approaches (Codd, 1970s; Date,
1980s)
§ Relational
theory gets its name from the fact it defines relations, two dimensional
matrix views of data, which we know better as tables
§ The
focus of relational theory is …
§ Keys (essential data identification) - uniquely
referencing structures- prevents identification integrity problems
§ Functional Dependency (essential data aggregates) -
aggregating data into logical groups or sets (or relations, tables, entities,
object classes)- prevents referential integrity problems
§ Normalization – formal techniques for identifying and
defining functional dependencies; yields a set of progressively more rigorous
"normal forms"
Normalization
- Normalization is a formal technique
for identifying and defining functional dependencies
- The
result is a set of models that describe the network of relationships
within and between groups of logical components in optimal ways that
minimize redundancy (and prevent the loss or corruption of information
when instances are added or deleted)
- Six steps: 1NF, 2NF, 3NF, BCNF, 4NF,
5NF1NF= First Normal Form, etc. (BCNF = Boyce/Codd
Normal Form)
- Often
3NF is considered adequate, but full normalization gives greater
understanding of semantics
First Normal
Form
§ The
consolidated list of unique candidate components is equivalent to 1NF in
relational theory
§
Make
all of the components discrete – only take a single value in their set
§
Remove
repeating sets of data into their own (new) set
§
Identify
components that are keys
§ For
example, an Order may contain components for item descriptions, prices and
quantities.
·
Because there can be
many repetitions of these components, we need to introduce a component like LineItem as an aggregate data set that contains them
·
Now the model for
Order is that it contains one of more unique LineItems
(discrete with no repetition)
Second Normal Form
§
2NF
separates all non-dependent components
§ Split
off into separate (new) sets any components that do not wholly depend on the
entire key
§
Focus
on sets of components with composite keys
§ For
example, for a given LineItem, the Description and
Price may be the same each time, but the Quantity depends on the particular
occurrence of a LineItem.
§ 2NF
would separate these non-dependent components into their own set, possibly
called Product or Item
Third Normal
Form
§
Ensure
that all non-key components are independent of one another
§
As
for 2NF but for components that are not keys.
§ For
example, Order may contain a CustomerName and their AccountCode
·
These non-key values may have some dependency
on each other and should be separated into another set, e.g. Customer.
§ 3NF
also involves removing any derived or calculated components
Normalization
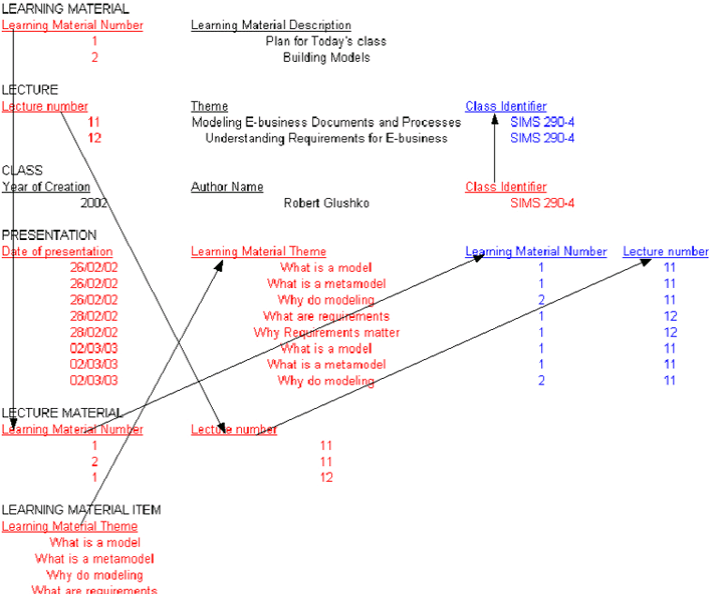
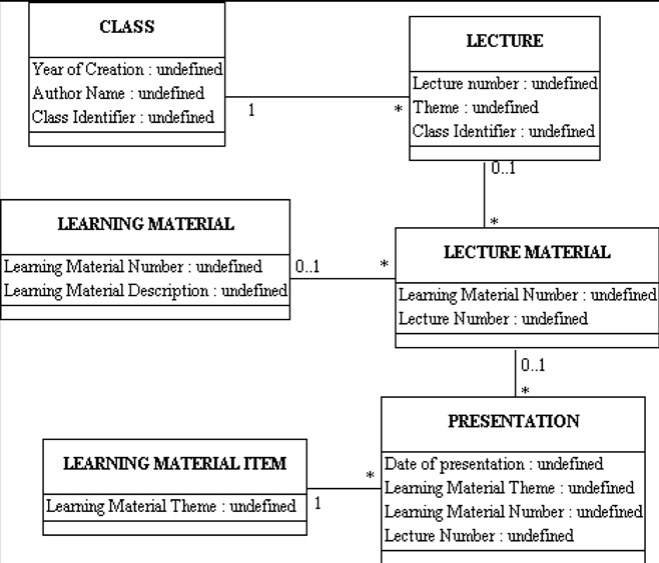
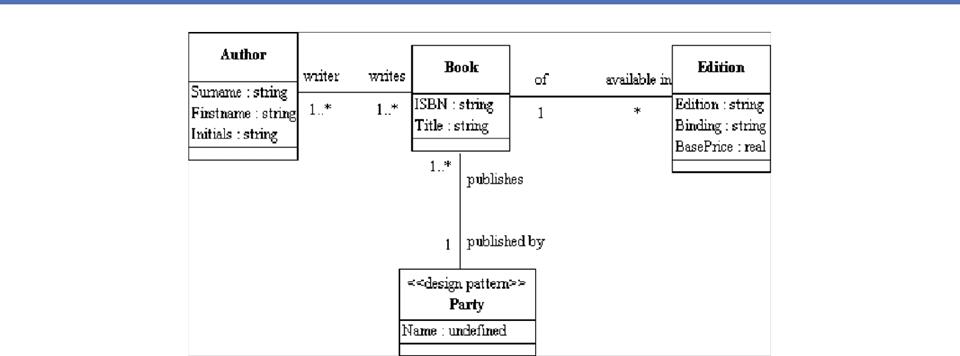
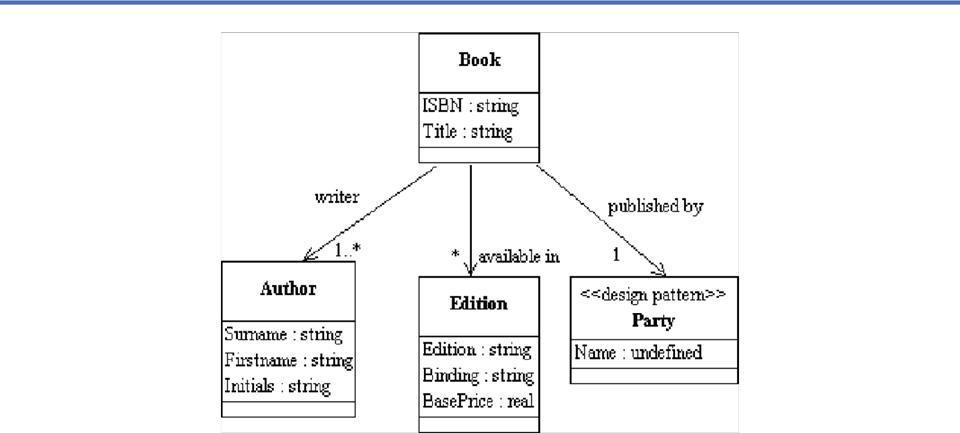
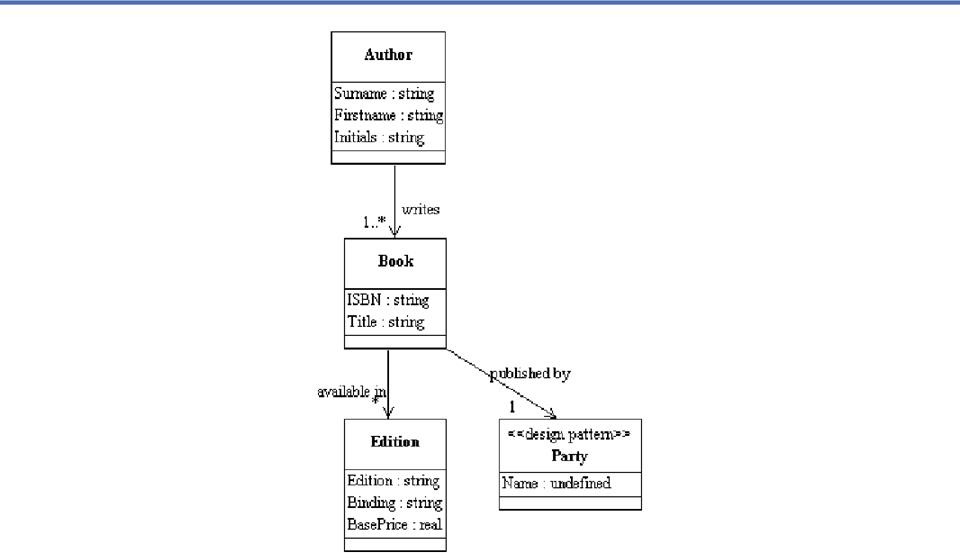
Example: Model of Lecture Notes
- Assume
we've analyzed my lecture notes to yield a set of candidate components
- We
can represent a populated set of content components for a lecture in a
single data set (as a table or "relation'")
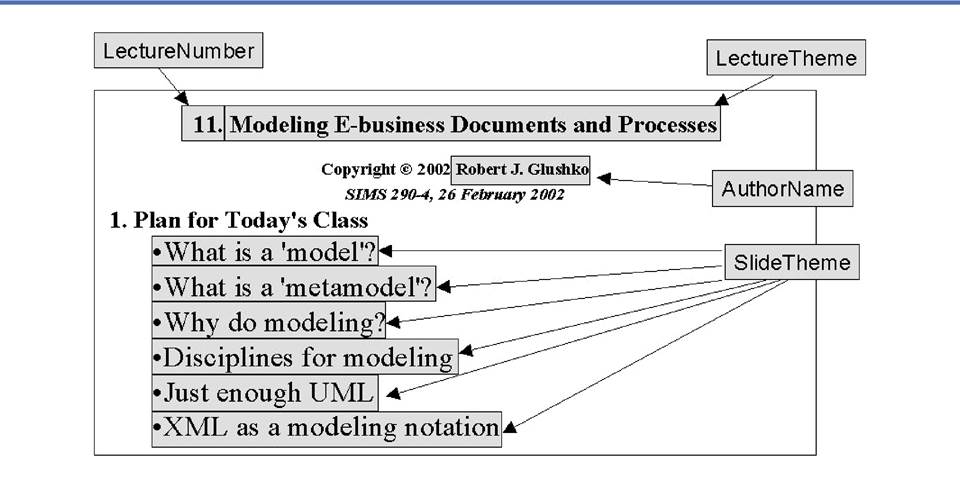
Content View of a
Lecture Slide