|
SE735 - Data and Document Representation
& Processing |
|
Lecture 3 - XML Foundations |
Additional Reference and Resource: XML Lecture
Document Engineering has nothing inherently to do with
XML
o XML has rapidly become the preferred format for
representing the physical models used to exchange information.
o XML is a format for describing document models that represent
entire business events
o Using coarse-grained documents as interfaces is the key
idea behind web services and service-oriented architectures.
The syntax isn’t what is most important about XML
XML Foundations for Document Engineering
1.
Neither the methods
of Document Engineering nor the models it produces have anything inherently to
do with XML or any other syntax
2.
But HTML has
limited use for business applications because it has no tags for marking up
information to give it business meaning
3.
XML has become the
preferred format for representing physical models of documents and business
processes
4.
XML was designed to
give the intuitive idea of a document model a more physical, formal foundation
5.
XML is a metalanguage for markup, and markup languages --
"document types" -- can be created for very specific document or
process models
6.
XML schemas define
the rules that govern the arrangement and values of a document’s content
7.
An XML schema
communicates the model of a document type to people or applications that need
to create or receive document instances, so an XML document without a schema is
little more than a bag of tags whose meanings are undefined
8.
There is often a
gap between the conceptual model of a document – all the "business rules"
associated with it -- and what can be described in an XML schema
9.
The decision about
where to transform documents is a business one
From HTML to XML
o HTML and the web browser transformed the Internet
o HTML took off because it was nonproprietary and because
of the conceptual and technical simplicity of publishing with it
o These two ideas—using tags to enclose or surround
content with labels, and relating the labels to the desired presentation of the
content—are easy to understand, even for
schoolchildren.
A Calendar Event in HTML

A Calendar Event in HTML viewed with a Browser

The Browser War
The idea of a standard and simple HTML
vocabulary didn't survive the browser wars
From the Web for Eyes to the Web for Computers
HTML has no tags for marking up
business meaning
No single vocabulary can have enough
semantic precision for all applications
XML’s Big Ideas
Five
big ideas relating to XML:
1.
XML
is extensible: it enables the creation of new sets of tags for domain-specific
content.
2.
XML
encodes content rather than presentation formatting; content and its
presentation are kept separate.
3.
XML
schemas define models of document types.
4.
XML
schemas enable XML document instances to be validated.
5.
XML
is often produced by converting non-XML
information; and XML documents are often transformed
to meet the requirements of specific implementations.
Creation of New Sets of Tags for Domain-Specific Content
XML document in which the text content is nearly
identical to that of the HTML
Ø XML
specification is more precise about syntax than HTML
Ø XML
is extensible: there is essentially no limit to
the element types and XML document can contain, and the elements are
often named to suggest the meaning of the content
Ø XML
is a metalanguage, which defines the rules by which
specific XML markup languages are created but says nothing about what element
types they use.
Ø These
specific XML languages are also called XML
vocabularies or XML applications
Ø For
example
o
XHTML is an XML vocabulary that recasts
HTML in XML syntax to make it more modular and to more rigorously separate
content and presentation.
o
UBL, the Universal Business Language, is an
XML vocabulary for business documents
Separation of Content and Presentation
In XML the separation of content and
presentation is inherent and desirable
Ø Nearly always necessary to apply to the XML document a transformation or stylesheet
that creates HTML or some other presentation-oriented vocabulary to the XML
information.
Ø Sometimes a stylesheet is
then also applied to the transformed HTML to optimize its presentation
Ø XML elements should be used to encode conceptual
distinctions in a presentation-independent manner to enable the reuse and
repurposing of information for different contexts or implementations.
Ø XML’s separation of content and presentation also
reinforces and rewards specialization in skills between information modeling
and user interface or graphic design.
Basic XML
eXtended Markup Language (XML)
Recommended
textbooks:
S. Holzner, Sams Teach
yourself XML in 21 Days, 3rd edition, 2004.
C. Bates,
XML in Theory and Practice, Wiley, 2003.
The
following examples are from Holzner:
Sample
HTML doc:
|
Text View |
Browser View |
|
<HTML> <HEAD> <TITLE>Hello From HTML</TITLE> </HEAD> <BODY> <CENTER> <H1> An HTML Document </H1> </CENTER> This is an HTML document! </BODY> </HTML> |
|
Sample
XML doc:
|
Text View |
Browser View |
|
<?xml
version="1.0" encoding="UTF-8"?> <document> <heading> Hello From XML </heading> <message> This is an XML document! </message> </document> |
<?xml version="1.0"
encoding="UTF-8" ?> - <document> <heading>Hello From XML</heading> <message>This text is inside a <message>
element.</message> </document> |
Sample
XML with Stylesheets:
|
Test View |
Browser View |
|
Xml files contents: <?xml
version="1.0" encoding="UTF-8"?> <?xml-stylesheet
type="text/css" href="ch01_04.css"?> <document> <heading> Hello From XML </heading> <message> This is an XML document! </message> </document> |
|
|
Stylesheet file contents (ch01_04.css): heading
{display: block; font-size: 24pt; color: #ff0000; text-align: center} message{display:
block; font-size: 18pt; color: #0000ff; text-align: center} |
|
XML
Structure
XML Tags
Tags
o Valid tags begin with A to Z, _ , a to z
o Second
characters may be digits 0 – 9, - , and .
o Tag names
are case sensitive
o Tag names
cannot include white space
Elements – composed of two
tags:
<book>
XML in Theory and Practice </book>
<name> Professor
F. T. Marchese </name>
Rules:
o An element must have start and
end tags unless it is an empty element
o Start and end tags must form a
matched pair
Empty elements –
Only have one tag: Syntax …<
/>
<heading/>
<heading text = “Hello from XML” />
Root elements:
o Each well
formed document must contain a root element with any legal name
o This element contains all other
elements
e.g.
<document>
<heading>
Hello From XML
</heading>
<message>
This is an XML
document!
</message>
</document>
Nesting
elements: tags
must pair-up inside XML so they are closed in reverse order:
<document>
<heading>
Hello From XML
</heading>
<message>
This is an XML
document!
</message>
</document>
Character Encoding
o ASCII – 1 byte – 256 characters
o Unicode – 2 bytes 65536
characters
o UCS – Universal character system
- 4 bytes – 4.3 billion characters
XML
supports:
US-ASCII
– US ASCII
UTF-8 -- Compressed
Unicode -- two bytes – 1st byte ASCII , 2nd byte Unicode
subset.
UTF-16 –
Compressed UCS
ISO-10646-UCS-2
-- Unicode
In
practice… XML
“processors” support UTF-8
<?xml version="1.0"
encoding="UTF-8"?>
<document>
<heading>
Hello From XML
</heading>
<message>
This is an XML
document!
</message>
</document>
Character
Reference
|
Character |
Sequence |
|
< |
< |
|
> |
> |
|
‘ |
' |
|
& |
& |
|
“ |
" |
e.g.
<message> This text is inside a
<message> element. </message>
Result: This text is inside a <message> element.
Comments
<!-- This is a comment -->
Attributes
Attributes
may appear in:
o Elements
o Processing instructions
o XML declarations
Syntax:
attributename
= “value”
e.g.
<brush width=”10” height =”5” color=”cyan” />
<point x=”10” y=”100” />
<book title=”Home Alone 2” review=”bad” />
CDATA
CDATA are
sections of the XML document that are not parsed.
CDATA – Character Data
PCDATA – Parsed Character Data
|
<?xml version="1.0"
standalone="yes" ?> - <document> - <text> Here's how the
element starts: - <![CDATA[ <employee
status="retired"> <name> <lastname>Kelly</lastname> <firstname>Grace</firstname> </name> <hiredate>October
15, 2005</hiredate> <projects> <project> <product>Printer</product> <id>111</id>
<price>$111.00</price> </project> . . . ]]>
</text> </document> |
XML
Namespaces
Namespace – a unique identifier for a set
of names within an XML document
Declaring
a Namespace: assign xmlns:prefix
attribute to a unique identifier, e.g.
xmlns:hr=http://www.superduperbigco.com/human_resources
The URIs (Uniform Resource Identifiers) or URLs specified
can point to a document such as a DTD or schema.
|
Original
document |
|
- <document> - <employee> - <name> <lastname>Kelly</lastname> <firstname>Grace</firstname> </name> <hiredate>October 15, 2005</hiredate> - <projects> - <project> <product>Printer</product> <id>111</id> <price>$111.00</price> </project> - <project> <product>Laptop</product> <id>222</id> <price>$989.00</price> </project> </projects> </employee> </document> |
|
Document
using namespaces |
|
- <hr:employee xmlns:hr="http://www.superduperbigco.com/human_resources" xmlns:boss="http://www.superduperbigco.com/big_boss"> - <hr:name> <hr:lastname>Kelly</hr:lastname> <hr:firstname>Grace</hr:firstname> </hr:name> <hr:hiredate>October 15, 2005</hr:hiredate> <boss:comment>Needs much supervision.</boss:comment> - <hr:projects> - <hr:project> <hr:product>Printer</hr:product> <hr:id>111</hr:id> <hr:price>$111.00</hr:price> </hr:project> - <hr:project> <hr:product>Laptop</hr:product> <hr:id>222</hr:id> <hr:price>$989.00</hr:price> </hr:project> </hr:projects> </hr:employee> |
Definition of Document Types
Easy to distinguish:
Ø a dictionary from an invoice,
Ø a newspaper from a novel,
Ø a restaurant menu from a collection of poems,
Because each document
follows a characteristic structural pattern to arrange types of content
unlikely to be found in the other.
Intuitive notion of models
of different types of documents is very useful.
Ø Explains why we have had:
o standard business forms for centuries
o style guides for authors
o national and international standards for electronic
business messages
o templates in word processors and spreadsheets
o various other ways of describing expectations about content
and its arrangement in documents.
Models of Documents
Need for Models
Ø Define models of
different types of documents in a rigorous and unambiguous way to automate
their process or exchange within or between applications.
Ø Use their formal definitions
to generate and drive some of the software needed to process the documents.
XML Schemas
An XML schema defines the
possible types of content in a document and the rules that govern the structure
and values of that content.
Ø Every XML schema contains definitions of element types.
Ø An XML schema also specifies the attributes that can be
associated with elements, but they’re not self-describing either.
Ø The meaning of elements is represented in an XML schema
through the constraints or rules that govern the structural arrangement of
elements and the values that elements and attributes can have.
Ø Business rules - constraints on structure, data, and behavior are
called.
o The kinds of rules expressed in XML element definitions
include:
§ containment relationships
§ sequence and cardinality relationships
§ choices
§ recursion
Schema Languages
Ø First XML schema language was Document Type Definition
(DTD)
Ø DTDs were designed to represent the structural
properties of documents, but they treat most data as just text and can’t
represent meaningful information models.
Ø DTDs are sufficient for describing
models of narrative document types like newspapers, dictionaries, and reports,
whose content is primarily text and intended for use by people.
Ø DTDs can also easily express mixed
content models in which character data can contain “in-line” elements, a very
common requirement in narrative documents
Document
Type Definitions (DTDs)
v A DTD
defines the formal rules of a documents structure
v Lists elements,
attributes, and entities that may be used in the document
v Defines
the relationship among elements, attributes, and entities
v DTDs
outline the tree structure of an XML document
v DTDs
have own structure and syntax
DTD Structure
o DTD is a
series of declarations of the form <! >
o DTDs
contain 4 keywords:
o
ELEMENT – which defines a tag
o
ATTRIBUTE – which defines an attribute of an
ELEMENT
o
ENTITY – which is used to define an ENTITY
o
NOTATION – which defines a data type
e.g. from Bates:
|
<!DOCTYPE letter[ <!ELEMENT letter (address)> <!ELEMENT address (line1,
line2?, line3*, city, (county|state)?, country?,
code?)> <!ELEMENT line1 (#PCDATA)> <!ELEMENT line2 (#PCDATA)> <!ELEMENT line3 (#PCDATA)> <!ELEMENT city (#PCDATA)> <!ELEMENT county (#PCDATA)> <!ELEMENT state (#PCDATA)> <!ELEMENT country (#PCDATA)> <!ELEMENT code (#PCDATA)> ]> |
o DTD describes structure of XML
document starting with root node – letter
o DTD is declared by using a
<!DOCTYPE> element
o <!DOCTYPE> element syntax:
o <!DOCTYPE rootname [DTD]>
o
<!DOCTYPE
rootname SYSTEM URI>
o
<!DOCTYPE
rootname SYSTEM URI [DTD]>
Elements
o
Each tag is declared as an ELEMENT
o
Each element may contain data or more elements, and
may have further attributes
o The
structure must be declared as 1st element,
e.g. <!ELEMENT letter
(address)>
o
ELEMENT content follows name and is in parentheses
o Content
is a list of items separated by “,” or “|” – known as content model
o Root node
has another ELEMENT as its content -(address)
o Address
element contains all components:
<!ELEMENT address (line1, line2?,
line3*, city, (county|state)?, country?, code?)>
o Comma
between elements means that all may be in XML document
o Element
ordering is logical for human understanding, not required by XML.
o Parentheses
used for grouping, and | is logical OR
o Symbols
after items signify appearance:
|
Symbol |
Example |
Meaning |
|
Asterisk |
item* |
Item appears
zero or more times |
|
Comma |
(item1,
item2, item3) |
Separates
items in sequence |
|
None |
item |
Item appears
exactly once |
|
Parentheses |
(item1,
item2) |
Encloses
group of items |
|
Pipe |
(item1 |
item2) |
Separates a
set of alternatives |
|
Plus |
Item+ |
Item appears
at least once |
|
Question Mark |
Item? |
Item appears
once or not at all |
Text
Content
o Parsed character data -
<!ELEMENT line1 (#PCDATA)>
o Mixed content model - <!ELEMENT
line1 (#PCDATA | house_number | street_name)*>
o
Must
obey this form -> #PCDATA -> other elements separated by pipe ->
followed by *
Attributes
o Attributes give additional info
about element or content
o Attributes declared separately and
associated with element:
<!ATTLIST element attribute type default>
o element
– name of element to which the attribute applies
o attribute - attribute name
o type –
XML data type
o default
- XML attribute defaults
e.g.
|
<!ELEMENT country (#PCDATA)> <!ATTLIST country continent (Europe | Asia | Africa | North America )”Asia” language CDATA #IMPLIED> |
o element
– country
o attribute - continent – followed by an enumerated list
of values
o default
- Asia
o attribute - language – followed by CDATA
o default
- #IMPLIED
XML Attribute Types
|
Type |
Usage |
|
CDATA |
Character data – not parsed |
|
ENTITY |
Attribute values is reference to
an entity declared elsewhere in DTD |
|
ENTITIES |
Multiple entities referenced |
|
ID |
Identifies a location within
document |
|
IDREF |
References an ID declared
elsewhere in DTD – used for hyperlinking in document |
|
IDREFS |
Multiple Ids linked |
|
NMTOKEN |
Value can be word or token |
|
NMTOKENS |
A list of tokens |
|
NOTATION |
NOTATION declared elsewhere |
|
Enumeration |
List of possible values in parens |
XML Attribute Defaults
|
Default |
Usage |
|
#REQUIRED |
Value must be given for each
element that has an attribute |
|
#IMPLIED |
Attribute is optional – no value
must be given |
|
#FIXED value |
Attribute must have value given |
|
Default |
Default value is given for
attribute |
Entities
o XML document separated into number
of components called Entities
o Each entity has a unique name
o Entities use to:
o
Split
large documents
o
Content
needs to be used in a number of places with document without duplication
o
Different
systems may render same content in different ways
o Declaration:
o
<!ENTITY
name definition>
o
<!ENTITY
name SYSTEM system_identifier [NOTATION]>
o
<!ENTITY
name PUBLIC [public_identifier] system_identifier
[NOTATION]>
o Internal entity - simplest definition –– within DTD
– wherever referenced in XML document content in DTD will be substituted for
reference.
o
Internal
entity definition - <!ENTITY
name definition>
o
External
reference – refers
to content outside DTD and XML file – may be on remote system
o
<!ENTITY
locationmap SYSTEM “./images/home.png” NDATA PNG>
§ URI - “./images/home.png”
§ NDATA – Notation data type follows
§ PNG – type of data
Notations
NOTATIONS normally specify
applications that can process data:
e.g.
<!NOTATION PNG SYSTEM “/usr/bin/display”>
<!NOTATION gif SYSTEM
"gifviewer.exe">
Using DTDs
Internal DTD –
|
<!DOCTYPE rootnode[ ]> |
External DTD –
|
<?xml version="1.0"?> <!DOCTYPE rootnode
SYSTEM | PUBLIC [public_identifier] URI> |
Example: from Holzner
|
XML file |
|
<?xml version =
"1.0" encoding="UTF-8" standalone="no"?> <!DOCTYPE document
SYSTEM "ch04_07.dtd">
<document> <employee> <name> <lastname>Kelly</lastname> <firstname>Grace</firstname> </name> <hiredate>October 15, 2005</hiredate> <projects> <project> <product>Printer</product> <id>111</id> <price>$111.00</price> </project> <project> <product>Laptop</product> <id>222</id> <price>$989.00</price> </project> </projects> </employee> </document> |
|
DTD file |
|
<!ELEMENT document
(employee)*> <!ELEMENT employee
(name, hiredate, projects)> <!ELEMENT name (lastname, firstname)> <!ELEMENT lastname (#PCDATA)> <!ELEMENT firstname (#PCDATA)> <!ELEMENT hiredate (#PCDATA)>
<!ELEMENT projects
(project)*> <!ELEMENT project (product,id,price)>
<!ELEMENT product
(#PCDATA)> <!ELEMENT id
(#PCDATA)> <!ELEMENT price (#PCDATA)> |
XML Schemas:
o
For transactional document types
the most useful schema language is the one recommended by the W3C called XSD or XML Schema (with a capital S).
o
XSD was developed to meet a much
broader and more computer-oriented set of requirements than DTDs.
o
XSD documents are encoded using
XML syntax and overcome most of the limitations of DTDs.
- Provide a means for defining the structure,
content and semantics of XML documents through XML itself.
o
The XSD language includes all the
basic data types common in programming languages and databases (string,
Boolean, integer, floating point, and so on), as well as mechanisms for
deriving new data types.
o For example, an XSD schema can define a Student type as a specialization
of a Person type with additional required elements, or an alphanumeric PartNumber type as a string whose values are restricted
using regular expressions.
- XML Schemas make it easier to validate
documents based on namespaces (unique identifiers for a set of names
within an XML document)
- XSD supports namespaces, a mechanism for distinguishing
XML vocabularies so that a schema can reuse definitions while avoiding
conflicts between elements with the same name that mean different things
o
Defined in the W3C's XML Schema
Working Group
- BUT greater expressiveness and extensibility of
XSD comes with substantially more complexity
An XML Schema:
- defines
elements that can appear in a document
- defines
attributes that can appear in a document
- defines
which elements are child elements
- defines
the order of child elements
- defines
the number of child elements
- defines
whether an element is empty or can include text
- defines
data types for elements and attributes
- defines
default and fixed values for elements and attributes
Using Schema:
|
<?xml
version="1.0"?> <xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <!-- Define the actual document --> <xsd:element name="letter"> </xsd:element> </xsd:schema> |
o
Content of schema – mostly
element definitions
o
Elements may contain sub-elements
(e.g. string or numbers, or both)
o Simple types - Elements that contain only data
o Complex types – all others
Example:
Mortgage file (Holzner)
|
XML file |
|
<?xml
version="1.0" encoding="UTF-8"?> <document documentDate="2005-03-02"> <comment>Good risk</comment> <mortgagee phone="888.555.1234"> <name>James Blandings</name> <location>1234 299th St</location> <city>New York</city> <state>NY</state> </mortgagee> <mortgages> <mortgage loanNumber="66 7777 88"> <property>The Hackett Place</property> <date>2005-03-01</date> <loanAmount>80000</loanAmount> <term>15</term> </mortgage> <mortgage loanNumber="11 8888 22"> <property>123 Acorn Drive</property> <date>2005-03-01</date> <loanAmount>90000</loanAmount> <term>15</term> </mortgage> <mortgage loanNumber="33 4444 11"> <property>99 West Pocusset St</property> <date>2005-03-02</date> <loanAmount>100000</loanAmount> <term>30</term> </mortgage> <mortgage loanNumber="55 3333 88"> <property>19 Johnson Place</property> <date>2005-03-02</date> <loanAmount>110000</loanAmount> <term>30</term> </mortgage> <mortgage loanNumber="22 6666 99"> <property>345 Notingham Court</property> <date>2005-03-02</date> <loanAmount>120000</loanAmount> <term>30</term> </mortgage> </mortgages> <bank phone="888.555.8888"> <name>XML Bank</name> <location>12 Schema Place</location> <city>New York</city> <state>NY</state> </bank> </document> |
|
XSD file |
|
<?xml
version="1.0" encoding="UTF-8"?> <xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <xsd:annotation> <xsd:documentation> Mortgage record XML schema. </xsd:documentation> </xsd:annotation> <xsd:element name="document" type="documentType"/> <xsd:complexType name="documentType"> <xsd:sequence> <xsd:element ref="comment"/> <xsd:element name="mortgagee" type="recordType"/> <xsd:element name="mortgages" type="mortgagesType"/> <xsd:element name="bank" type="recordType"/> </xsd:sequence> <xsd:attribute name="documentDate" type="xsd:date"/> </xsd:complexType> <xsd:complexType name="recordType"> <xsd:sequence> <xsd:element name="name" type="xsd:string"/> <xsd:element name="location" type="xsd:string"/> <xsd:element name="city" type="xsd:string"/> <xsd:element name="state" type="xsd:string"/> </xsd:sequence> <xsd:attribute name="phone" type="xsd:string" use="optional"/> </xsd:complexType> <xsd:complexType name="mortgagesType"> <xsd:sequence> <xsd:element name="mortgage" minOccurs="0" maxOccurs="8"> <xsd:complexType> <xsd:sequence> <xsd:element name="property" type="xsd:string"/> <xsd:element name="date" type="xsd:date" minOccurs="0"/> <xsd:element name="loanAmount" type="xsd:decimal"/> <xsd:element name="term"> <xsd:simpleType> <xsd:restriction base="xsd:integer"> <xsd:maxInclusive value="30"/> </xsd:restriction> </xsd:simpleType> </xsd:element> </xsd:sequence> <xsd:attribute name="loanNumber" type="loanNumberType"/> </xsd:complexType> </xsd:element> </xsd:sequence> </xsd:complexType> <xsd:simpleType name="loanNumberType"> <xsd:restriction base="xsd:string"> <xsd:pattern value="\d{2} \d{4} \d{2}"/> </xsd:restriction> </xsd:simpleType> <xsd:element name="comment" type="xsd:string"/> </xsd:schema> |
Rules That Schema Languages Can’t Represent
Every XML schema language
makes tradeoffs that determine:
o the range of document models it can realize
o the ease with it defines them
o how readily it can reuse a model or parts of models in
more than one schema.
e.g. XSD cannot express dependency constraints on element
content:
o
“the start time for
a calendar event must be earlier than the end time”
o “if the total is greater than $1,000 the purchase order
requires an authorization code”
Validation
o Validation is the process of testing whether an XML
document follows the rules defined in an associated schema.
o A document that follows or satisfies the schema is said
to be valid.
o Validation is most often carried out by a validating
parser embedded in an XML-aware text editor, application server, integration
tool, or other software that processes XML
o Weaker criterion of quality checking for XML documents
is called well-formedness and requires merely that
the XML document meets some minimal syntactic constraints, such as having
exactly one root element and having matching start and end tags that don’t
overlap.
o An XML document that isn’t even well-formed will be
rejected by an XML parser and not passed on for further processing.
Conversion and Transformation
o XML is often produced by converting non-XML information
o XML documents are often transformed to meet the
requirements of other contexts or implementations
o Issues and problems that arise in conversion and transformation
are shaped by where the source and target documents lie on the Document Type
Spectrum
o The greater semantic precision in transactional
documents makes them easier to convert to or from, regardless of the source or
target syntax
Conversion to XML
Reason to covert to XML:
o To facilitate a single-source publishing strategy in
which content is created once and then reused many times.
o Extract or format the same content in many different
ways to create different documents. This form of reuse is often called repurposing.
o To extract information from a database, ERP system, or
legacy application primarily used inside an enterprise to enable Internet-based
transactions with customers or business partners.
XML Conversion
o The conversion of information to XML can be completely
automated if the information source is well structured with explicit semantics
and the structure and semantics are rigorously described with a schema.
o Process of adding value to information by converting it
to XML is often called up translation
to express the work it takes to give XML the informational equivalent of
potential energy.
o Once information is in XML syntax its greater potential
energy makes it easy and straightforward to create any other format, so
naturally the transformation from XML to a non-XML format is often called down translation.
Up- and Down-Translation with XML
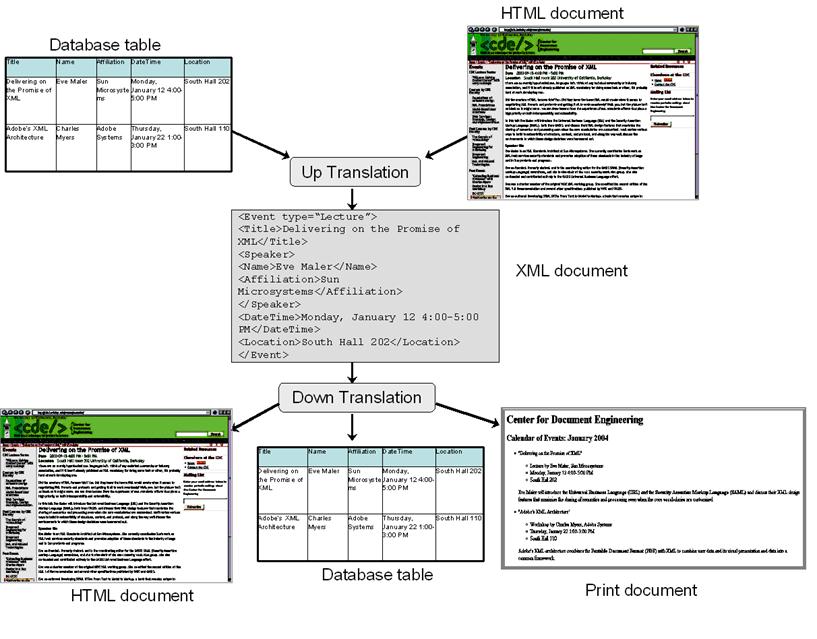
Transformation from XML
o Transforming an XML document involves selecting,
reordering, or restructuring its content.
o Transforming an XML document so that it conforms to a
different XML schema is often followed by down-translation to a non-XML format,
as it is in EDI (Electronic Data Interchange) gateway applications.
o Often necessary to transform or down-translate XML to
HTML so that it can be viewed in a web browser.
o The process of applying a presentation to an XML
document is called styling
o Styling is done by using W3C: XSLT, the Extensible Stylesheet Language
for Transformation, and XSL FO, the
Extensible Stylesheet Language Formatting Objects
XSLT
o XSLT is an XML-aware functional programming language
that operates on logical “node sets” derived from the element and attribute
structure of XML documents.
o XSLT has the usual constructs for logical flow of
control like conditional, loops, and switches. What makes it most useful for
transforming XML are its XPath facilities for
expressing and matching patterns in the logical XML structures so that
arbitrary trees or subtrees can be selected and
rearranged.
o XSL FO, often a target vocabulary of an XSLT transform,
is designed for typesetting-quality control of printed XML output.
XML Stylesheets
From:
http://nwalsh.com/docs/tutorials/xsl/xsl/slides.html
·
XML is not a fixed tag set (like HTML)
·
XML by itself has no (application) semantics
·
A generic XML processor has no idea what is
"meant" by the XML
·
XML markup does not (usually) include formatting
information
·
The information in an XML document may not be in
the form in which it is desired to present it
·
Need something in addition to the XML document that
provides information on how to present or otherwise process the XML
Advantages
to separating content from style
·
Separation of style from content allows for the
same data to be presented in different ways.
·
Enabling:
o
Reuse of fragments of data: the same content should
look different in different contexts
o
Multiple output formats: different media (paper,
online), different sizes (manuals, reports), different classes of output
devices (workstations, hand-held devices)
o
Styles tailored to the reader's preference (e.g.,
accessibility): print size, color, simplified layout for audio readers
o
Standardized styles: corporate stylesheets
can be applied to the content at any time
o
Freedom from style issues for content authors:
technical writers needn't be concerned with layout issues because the correct
style can be applied later
Options for
displaying XML
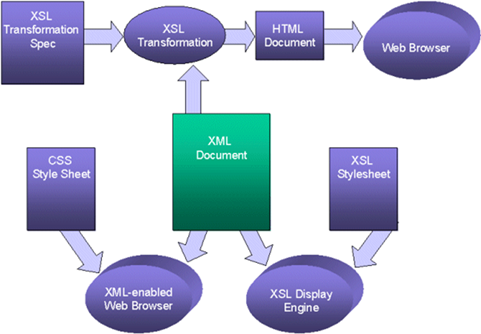
What Does
a Stylesheet Do?
·
A stylesheet specifies
the presentation of XML information using two basic categories of techniques:
·
An optional transformation of the input document
into another structure
·
A description of how to present the transformed
information (i.e., a specification of what properties to associate to each of
the various parts of the transformed information)
Transformation
capabilities
·
Transformation capabilities include:
o
generation of constant text
o
suppression of content
o
moving text (e.g., exchanging the order of the
first and last name)
o
duplicating text (e.g., copying titles to make a
table of contents)
o
sorting
o
more complex transformations that "compute"
new information in terms of the existing information
Description
of information
o
Description of how to present the (possibly
transformed) data includes three levels of formatting information:
o
Specification of the general screen or page (or
even audio) layout
o
Assignment of the transformed content into basic
"content container types" (e.g., lists, paragraphs, inline text)
o
Specification of formatting properties (spacing,
margins, alignment, fonts, etc.) for each resulting "container"
The
components of the XSL language
·
The full XSL language logically consists of three
component languages which are described in three W3C (World Wide Web
Consortium) Recommendations:
o
XPath: XML
Path Language--a language for referencing specific parts of an XML document
o
XSLT: XSL Transformations--a language for
describing how to transform one XML document (represented as a tree) into
another
o
XSL: Extensible Stylesheet
Language--XSLT plus a description of a set of Formatting Objects and Formatting
Properties
XML to
result tree
An XSLT
"stylesheet" transforms the input (source)
document's tree into a structure called a result
tree consisting of result objects
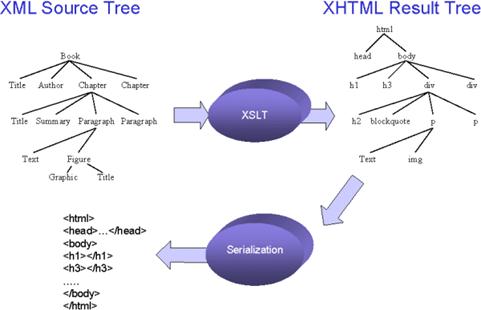
Result
tree doctypes
·
The result tree's structure is that of an XML
document, and its objects correspond to elements with attributes
·
The result tree's structure and "tag set"
can match that of any XML document or doctype.
o
In particular, the result tree could be:
§ HTML/XHTML
result tree is
easily written out as an HTML document
§ other XML
doctype
result tree is easily written out as
an XML document in this other doctype (for some
further application-specific processing)
§ FO result
tree
result tree's
structure (and element and attribute names) matches the set of formatting objects and formatting properties defined by the (non-transformation)
part of XSL
·
Serialization of the result tree is not necessary
for further processing of the result tree.
An XSL stylesheet
·
An XSL stylesheet
basically consists of a set of templates
·
Each template "matches" some set of
elements in the source tree and then describes the contribution that the
matched element makes to the result tree
·
Generally, elements in a stylesheet
in the "xsl" namespace are part of the XSLT
language, and non-xsl elements within a template are
what get put into the result tree
HTML vs.
XSL Formatting Objects
·
Transformation is independent of the target result
type
·
Most people are more familiar with HTML so many of
the examples in this tutorial use HTML
·
The XSL implementation in IE5 is incomplete. The
examples in this tutorial will not work in IE5
·
The techniques apply equally well to XSL Formatting
Objects or other tag sets
·
XSLT is a tree-to-tree transformation process
·
Serialization may vary depending on the selected
output method
·
There is a distinction between HTML element names
and HTML
The
Structure of a Stylesheet
·
XSLT Stylesheets are XML
documents; namespaces (http://www.w3.org/TR/REC-xml-names)
are used to identify semantically significant elements.
·
Most stylesheets are
stand-alone documents rooted at <xsl:stylesheet>
or <xsl:transform>. It is possible to have
"single template" stylesheet/documents.
·
<xsl:stylesheet>
and <xsl:transform> are completely synonymous.
Note that
it is the mapping from namespace abbreviation to URI that is important, not the
literal namespace abbreviation "xsl:" that
is used most commonly.
Stylesheet Examples
A Stylesheet
|
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
version="1.0"> ... </xsl:stylesheet> |
A
Transformation Sheet
|
<eg:transform xmlns:eg="http://www.w3.org/1999/XSL/Transform" version="1.0"> ... </eg:transform> |
Document
as Stylesheet
|
<html xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <head> <title>Silly Example</title> </head> <body> <h1>Silly Example</h1> <p>You'd probably use extension elements, or somthing more interesting in real life: 3+4 is <xsl:value-of
select="3+4"/>. </p> </body> </html> |
How to
Get Started
Start
with your XML Document
Want
to transform the following XML document ("cdcatalog.xml") into
XHTML:
|
<?xml
version="1.0" encoding="ISO-8859-1"?> <catalog> <cd> <title>Empire
Burlesque</title> <artist>Bob Dylan</artist> <country>USA</country> <company>Columbia</company> <price>10.90</price> <year>1985</year> </cd> . . . </catalog> |
Create an
XSL Style Sheet
Create
an XSL Style Sheet ("cdcatalog.xsl") with a transformation template:
|
<?xml
version="1.0" encoding="ISO-8859-1"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <html> <body> <h2>My CD Collection</h2> <table border="1"> <tr bgcolor="#9acd32"> <th
align="left">Title</th> <th
align="left">Artist</th> </tr> <xsl:for-each
select="catalog/cd"> <tr> <td><xsl:value-of
select="title"/></td> <td><xsl:value-of
select="artist"/></td> </tr> </xsl:for-each> </table> </body> </html> </xsl:template> </xsl:stylesheet> |
Link the
XSL Style Sheet to the XML Document
Add
an XSL Style Sheet reference to your XML document ("cdcatalog.xml"):
|
<?xml
version="1.0" encoding="ISO-8859-1"?> <?xml-stylesheet type="text/xsl"
href="cdcatalog.xsl"?> <catalog> <cd> <title>Empire
Burlesque</title> <artist>Bob Dylan</artist> <country>USA</country> <company>Columbia</company> <price>10.90</price> <year>1985</year> </cd> . . . </catalog> |
If
you have an XSLT compliant browser it will nicely transform your XML
into XHTML!
View the result in IE 6 or Netscape 6 and
Example
Explained
·
An XSL style sheet consists of a set
of rules called templates.
·
Each <xsl:template> element contains rules to apply when a
specified node is matched.
XSLT uses
Templates
·
The <xsl:template> element contains rules to apply when a
specified node is matched.
·
The match attribute is used to associate
the template with an XML element. The match attribute can also be used
to define a template for a whole branch of the XML document (i.e.
match="/" defines the whole document).
·
The following XSL Style Sheet contains
a template to output the XML CD Catalog
|
<?xml
version="1.0" encoding="ISO-8859-1"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <html> <body> <h2>My CD Collection</h2> <table border="1"> <tr bgcolor="#9acd32"> <th>Title</th> <th>Artist</th> </tr> <tr> <td>.</td> <td>.</td> </tr> </table> </body> </html> </xsl:template> </xsl:stylesheet> |
·
Since the style sheet is an XML
document itself, the document begins with an xml declaration: <?xml version="1.0" encoding="ISO-8859-1"?>.
·
The <xsl:stylesheet> tag defines the start of the
style sheet.
·
The <xsl:template> tag defines the start of a
template. The match="/" attribute associates (matches) the
template to the root (/) of the XML source document.
·
The rest of the document contains the
template itself, except for the last two lines that defines the end of the
template and the end of the style sheet.
·
The result of the transformation will
look (a little disappointing) like this:
My
CD Collection
|
Title |
Artist |
|
. |
. |
·
If you have Netscape 6 or IE 5 or
higher you can view: the XML file, the XSL file, and the result
·
The result from this example was a
little disappointing, because no data was copied from the XML document to the
output.
Introduction
to XSL-FO
- XSL-FO is
about formatting XML data for output.
What is
XSL-FO?
- XSL-FO
is a language for formatting XML data
- XSL-FO
stands for Extensible Stylesheet Language
Formatting Objects
- XSL-FO
is a W3C Recommendation
- XSL-FO
is now formally named XSL
XSL-FO is
About Formatting
XSL-FO
is an XML based markup language describing the formatting of XML data for
output to screen, paper or other media.
XSL-FO is
Formally Named XSL
- XSL-FO
and XSL the same thing?
- Styling
is both about transforming and formatting information
- When
the World Wide Web Consortium (W3C) made their first XSL Working Draft, it
contained the language syntax for both transforming and formatting XML
documents.
- Later
the XSL Working Group at W3C split the original draft into separate Recommendations:
§ XSLT,
a language for transforming information
§ XSL
or XSL-FO, a language for formatting information
§ XPath,
a language for defining parts of an XML document
XSL-FO is
a Web Standard
·
XSL-FO became a W3C Recommendation 15.
October 2001. Formally named XSL.
·
To read more about the XSL activities
at W3C please read our W3C Tutorial.
·
XSL-FO documents are XML files with
output information.
XSL-FO
Documents
·
XSL-FO documents are XML files with
output information. They contain information about the output layout and output
contents.
·
XSL-FO documents are stored in files
with a *.fo or a *.fob extension. It is also quite
normal to see XSL-FO documents stored with the *.xml extension, because this
makes them more accessible to XML editors.
XSL-FO
Document Structure
XSL-FO
documents have a structure like this:
|
<?xml
version="1.0" encoding="ISO-8859-1"?> <fo:root xmlns:fo="http://www.w3.org/1999/XSL/Format"> <fo:layout-master-set> <fo:simple-page-master
master-name="A4"> <!-- Page template goes here --> </fo:simple-page-master> </fo:layout-master-set> <fo:page-sequence master-reference="A4"> <!-- Page content goes here --> </fo:page-sequence> </fo:root> |
Structure
explained
·
XSL-FO
documents are XML documents, and must always start with an XML declaration:
|
<?xml
version="1.0" encoding="ISO-8859-1"?> |
·
The
<fo:root> element
contains the XSL-FO document. It also declares the namespace for XSL-FO:
|
<fo:root xmlns:fo="http://www.w3.org/1999/XSL/Format"> <!-- The full XSL-FO document goes here
--> </fo:root> |
·
The
<fo:layout-master-set> element contains one or
more page templates:
|
<fo:layout-master-set> <!-- All page templates go here --> </fo:layout-master-set> |
·
Each
<fo:simple-page-master>
element contains a single page template. Each template must have a unique name
(master-name):
|
<fo:simple-page-master master-name="A4"> <!-- One page template goes here --> </fo:simple-page-master> |
·
One
or more <fo:page-sequence>
elements describe page contents. The master-reference attribute refers to the
simple-page-master template with the same name:
|
<fo:page-sequence master-reference="A4"> <!-- Page content goes here --> </fo:page-sequence> |
Note: The
master-reference "A4" does not actually describe a predefined page
format. It is just a name. You can use any name like "MyPage",
"MyTemplate", etc.
·
XSL-FO
uses rectangular boxes (areas) to display output.
Where to Transform
o XML is everywhere in distributed computing
architectures.
o It can be the native format in an XML database or
created by conversion from a non-XML database, ERP (Enterprise resource planning ) application, legacy system, or EDI data source.
o XML can be sent anywhere inside or outside the
enterprise to expose information or functionality or to create an extended
enterprise
o Since many web browsers contain XML parsers and support
XSLT, XML can go all the way to the end user’s client.
XML Everywhere in a Generic System
Architecture
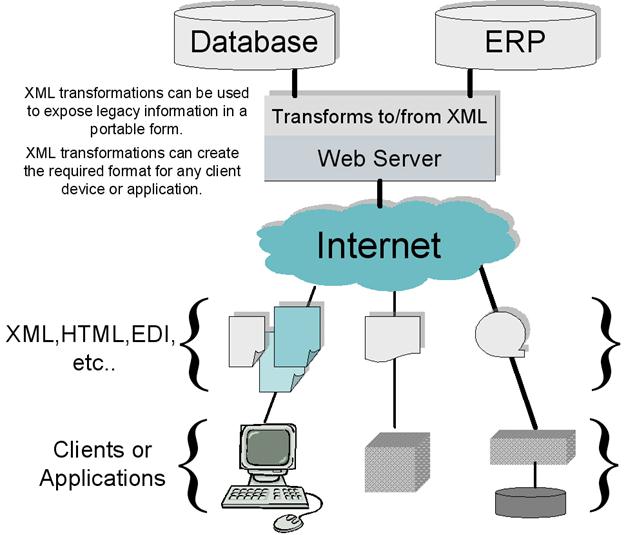
The decision about where to transform
is a business one