


The model assigns a probability to each possible string. There is an infinite number of possible strings. This is handled by using a Probabilistic Context Free Grammar (PCFG). This assigns a probability to each rewrite rule, but ignores context.
Given a string of words w1...wn,
This is simplified using a bigram model, in which the probability of wi depends only on previous word w_i-1.
We estimate P(wi|wi-1) based on the training corpus (the body of training examples):
For instance a training corpus is:
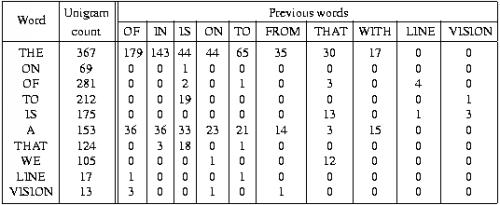
A trigram model, in which P(wi|wi-1,wi-2), is more difficult to estimate from the training corpus. The bigram and trigram models capture some local contextual information, such as subject-verb agreement. The unigram model just measures word frequencies.
We can use the weighted sum of trigram, bigram and unigram models: