


The acoustic model relates the words to the underlying signal: P(signal|words). This refines the process of speech recognition into the following steps:word --> sequence of phones --> acoustic signal --> vector quantization
The phonetic variations are due to:
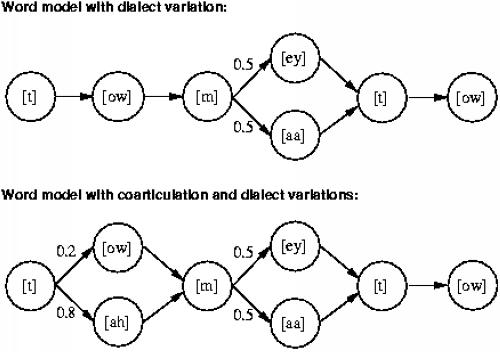
The states represent phones, and the transitions represent succession with some probability. If there is only one successor, then the probability = 1.
There is one Markov model per word. This model is used to predict the probability that each particular combination of phones occurs.
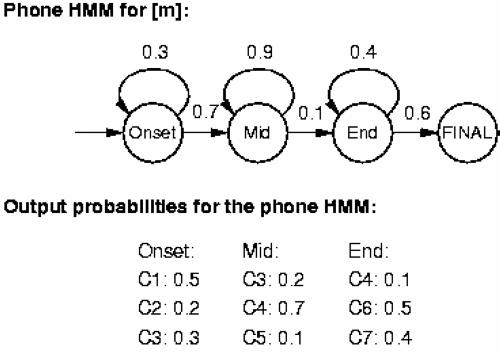
Each state has multiple outputs with associated probabilities. The outputs represent vector quantization values. The transitions can be loops, which permits iteration of vector quantization values for slow speakers. The model is called hidden because we don't know which state (Onset, Mid, End) produced which output (C1-C7). As a result, the pronunciation Markov model is actually a Hidden Markov model. Other phones have similar HMMs.
Given vector quantization values, we compute P(VQ values|phone):